数据模型是一种对于现实动作的抽象,在实际的项目中,应用往往是层层叠加的数据模型构建的,
比如应用开发模拟的是现实生活中的对象动作,而为了驱动这些对象运动,需要存储数据,就需要存储数据模型,存储还需要落盘,在磁盘上需要有数据模型来存储。
不过无论多少层,下层总是可以提供一个明确的API来向上暴露模型可以提供的动作。
作者同时表示聚焦于数据存储和查询的模型,比较关系模型,文档模型和部分图形数据模型。
首先是关于关系型数据模型,用于处理典型的事务操作和批处理
而且由于抽象出来足够好,所以风靡一时,直到现在还是广泛的适用于在线发布,电子商务等领域
其次是NoSql,这个概念伴随着发展,解释起来也是在不断的概念,到现在被解释为了Not Only SQL
毕竟比起一个关系型数据库,有些时候,需要更大的吞吐量或者更好的伸缩性
或者用于支持特殊的查询操作。
当然,无论是关系型数据库还是非关系型数据库,往往会进行混合使用,这种方式被称为混合持久化。
其次,作者还拿简历作为例子进行了比较,如果采用JSON作为存储,在直接查询上的话,会更加方便,但如果我们希望将简历上的学校,工作公司作为一个实体进行抽取的话,JSON就显得非常笨重。
这就是常见的多对一的问题,多个简历会引入同一个实体。如果使用文档模型进行存储,就不怎么吻合,而且很多文档数据库也不支持引用查询,这就需要在外部引入代码来模拟链接。
那么关系数据库的这个关系模型也不是一蹴而就的,也是不断的发展的,这个模型最初是层次模型,类似JSON的树形存储结构,这种存储结构也类似JSON这种文档存储的模式,并不能良好的解决多对多的问题。后来则是发展出了关系模型和网状模型
网状模型则是利用指针来进行记录之间的链接,导致访问起来非常苦难,需要从多条链路中找到一条自己期待的记录。
关系模型则不必说,使我们最为常见的数据模型,利用一个大一统的查询优化器来决定具体的查询事宜,对外只暴露一个通用的使用方式,也就是SQL
而文档数据库则是还原层次模型,不过可以在其中,利用比如超链接的方式引入其他文档。
其他方面,关于文档数据模型和关系数据模型,哪个适合于应用代码,这就是一个根据需求自主选择的方式了
因为文档数据库适合存储一个大而全的树状数据,但是对于多对多的关系,可能文档数据库支持并不太好,所以还是选择关系数据库更好。
而现在来说,诸如PostgreSQL等,也提供了对文档的支持,所以对于不同的数据模型,可以选择在一个数据库中使用。模型的混合使用将是一个很好的路线。
而且对于数据的存储和使用,关系模型和文档模型也是不同的。关系模型对于存储和读取,都要求使用固定的格式,对于存储,也是要求强符合数据表的数据存储
对于文档模型,如果希望增加某些存储列,则是直接修改数据就可以,不用管相关的存储结构。
讲述完成了不同的数据模型的差异和演进,接下来开始讲述不同的数据查询语言的区别。
对于SQL来说,是一种声明式的查询语言,声明式的使用一般优于命令式的,因为声明式的语言,往往后台有一个解释器,来解释查询声明.
而命令式的查询则是告诉系统以某种特定顺序来执行某些特定的操作。
而且作者通过MapReduce和CSS来证明了声明式API是优于命令式的,就好比MapReduce
中,如果希望查询一些数据,那么是需要书写相关的Javascript代码的
这也是MapReduce的一个局限性,于是类似的系统,诸如MongoDB提供了声明式语言的支持。
那么在对比了声明式和命令式语言之间的差异之外,
作者展示了另一种常见的NoSQL方向的实现,图数据库
文档模型适合一个大而全且之间不存在任何关系的场景使用,如果彼此有关系,可以考虑使用关系模型,而对于多对多的关系模型呢?
彼此具有关系,这时候如果使用关系模型必然带来过高的复杂度,这时候提出了图数据库
一个图数据库中往往具有两种对象,比如 顶点和边 或者叫做对象和关系
典型例子就是社交图谱的实现,就是一个图数据库最好的体现
但是往往相同类型对象之间的多对多关系,使用关系数据库还可以hold住,如果类型数量变多了就不好展示了
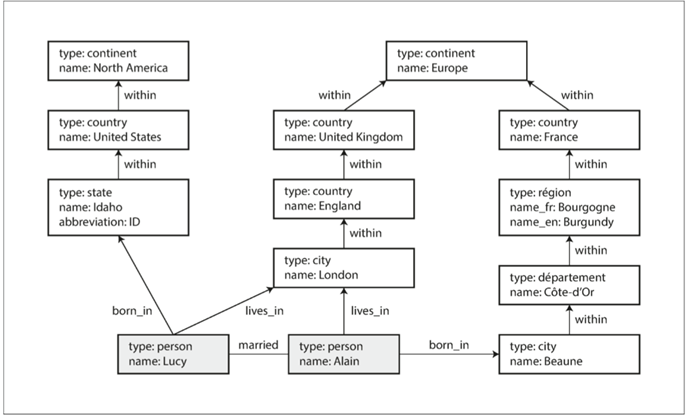
上面途中有着大陆,国家,州,用户等类型的对象,那么在不同类型的图数据库中,如何实现这个关系呢?
首先是属性图,这一个常见于Neo4j等图数据库实现
分为了顶点和边,基本实现如下

我们来看下如何录入一个数据

通过边的label来指定不同类型之间的关系,withIn或者born_in
利用关系和对象的概念,可以模拟很多传统关系难以表达的事情。
那么对这类数据的使用,也是直接使用Cypher进行查询即可

这个match要求要出生在美国,并且现在生活在欧洲
上面的查询的具体实现可以是从人的角度开始出发,依次检查每个人的出生地和居住点,然后返回符合条件的人
或者从两个Location顶点开始反向查找,直到找到具体的人,取交集返回
如果尝试使用SQL来进行查询
那么可能需要书写对应的sql,来不断的递归数据,将数据插入到一个集合
这说明这种具有递归等复杂的场景,选择合适的数据模型很重要。
图数据还有一种类似的存储模式
三元组存储,讲数据分为了主语 谓语 宾语,比如 somebody like something
主语对应的自己这个顶点,宾语可以是某个属性值,也可以是另一个顶点
比如给出一个例子

这种三元组的查询方式,可以使用SPARQL来进行查询,使用更为简单

最后作者还提起了Datalog作为一个更为古早的查询语言,查询应用于三元组,这里我感觉纯属扩展知识,也就随口一提吧
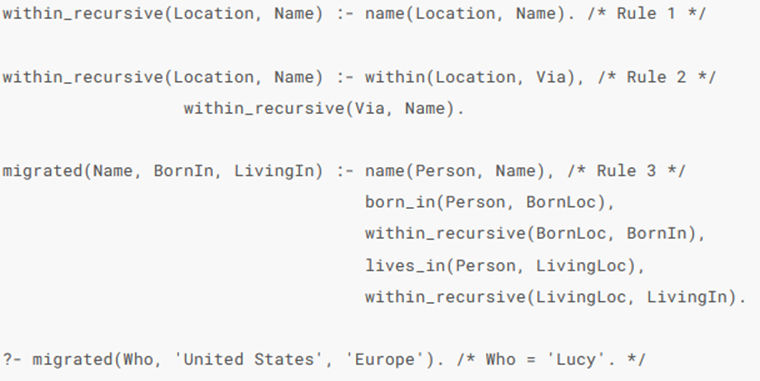
前两个规则去依次运用,从而递归获取符合的地点
最后migrated来组合上面两者的规则,从而结果。
那么说了这么多,可能会觉着图形数据库和网状模型有点相似,但是比如网状模型仍然存在嵌套类型的限制,而且网络模型可能需要维持数据的有序性,而图形数据库只需要在查询的时候排序。并且伴随着发展,图形数据库比起CODASYL,支持了声明式查询
最后也是照搬下作者的总结
这一章,主要说了从SQL -> NoSQL
SQL也就是关系模型,NoSQL则分别说了文档数据库和图形数据库,还声明了NoSQL对于数据结果要求更加灵活。
从一开始的文档和关系结构,到最后专门说明图形数据库
而且声明了伴随着改变,越来越多的系统支持了更多的模式,从而适应更多的需求