最近来开一个新坑,尝试写下阅读DDIA(设计数据密集型应用的读后感),或者说是一种对文章的理解和提炼。
那么我们废话不多说,直接开始,第一章,关于可靠性 可伸缩性 可维护性
作者指出,现在的后端服务从计算密集型转向了数据密集型,而数据密集型系统的核心是数据,具体点是数据量,数据复杂度,数据的变更速度。
在这个数据密集型的系统中,开发人员往往会将总体的工作拆分为一系列能被单个工具完成的任务,并且利用代码将其串联起来。
那么开发这样一个提供数据的应用程序的开发者,也能被称为数据系统设计人员。
而对于数据密集型的应用,作者希望讨论其可靠性(Reliability) 可伸缩性(Scalability) 可维护性(Maintainability)
对于可靠性,有一些关键名词,比如故障,指的是造成错误的原因. 容错,指的是容忍某些特定的错误,而非所有的错误. 而容错的目的是避免因为故障而导致系统级别的失效.
首先是硬件故障,作者拿数据中心中的硬盘集群来举例,说明冗余硬件的使用方式.其次对于现在主流的云服务,作者希望引入软件容错机制,这里让我联想到,现在主流的软件集群,常见于Master-Slave节点.无论Master还是Slave节点,都具有多节点备份机制.
而且往往面向Web,连接数据库的应用都是无状态的服务,可以将硬件故障的影响降到一个非常低的值.
其次是软件故障,作者提到了系统性的错误,对于这类错误,是没有特效药,只能通过不断的测试来进行检验.
最后是人为的错误,这一点和人有关,可以考虑区分生产测试环境,合理设计API,多层次测试,采用多版本发布模式(蓝绿/金丝雀),配置明确的监控指标等方面进行控制.
对于可伸缩性
在做着说明应对方针之前,作者利用推特来讲述了负载这个概念,这里我们引用下推特
|
推特的两个主要业务是:
发布推文
用户可以向其粉丝发布新消息(平均 4.6k 请求 / 秒,峰值超过 12k 请求 / 秒)。
主页时间线
用户可以查阅他们关注的人发布的推文(300k 请求 / 秒)。
处理每秒 12,000 次写入(发推文的速率峰值)还是很简单的。然而推特的伸缩性挑战并不是主要来自推特量,而是来自 扇出(fan-out)[^ii]—— 每个用户关注了很多人,也被很多人关注。 |
那么如何将一个推文推送到所有关注他的人的主页呢?有两种实现方式
|
1.发布推文时,只需将新推文插入全局推文集合即可。当一个用户请求自己的主页时间线时,首先查找他关注的所有人,查询这些被关注用户发布的推文并按时间顺序合并。 2. 为每个用户的主页时间线维护一个缓存,就像每个用户的推文收件箱。 当一个用户发布推文时,查找所有关注该用户的人,并将新的推文插入到每个主页时间线缓存中。 因此读取主页时间线的请求开销很小,因为结果已经提前计算好了。 |
第一种方式简单,但是对服务器端的负载大,但是第二种面对某些名人的时候,可能导致一条推文出现上千万次的写入,非常占据性能。
最终推特采用了两种方式的混合,即多数用户的发文采用第二种方式,直接在发送的时候进行插入到关注他的人的主页,而对于名人则采用了第一种,在获取主页的时候进行刷新,在与主页的时间线缓存合并。
那么上面实例大致描述了对应负载的混合做法,面对不同的场景采用不同的方式处理。
其次是负载的具体指标,比如延迟,响应时间
两者之间的区别在于响应时间是客户所看到的,除了实际处理请求的时间( 服务时间(service time) )之外,还包括网络延迟和排队延迟。
而且即便我们使用响应时间作为指标来统计,也是需要注意统计的方式,即采用什么样的计算逻辑来统计。
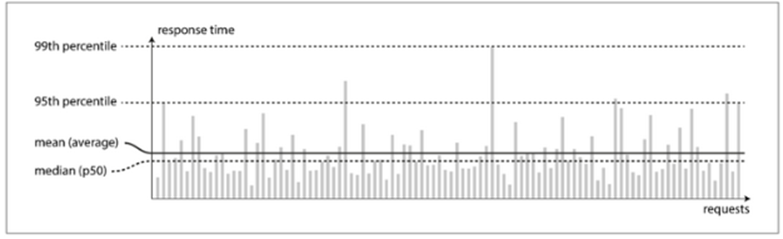
即便我们统计响应时间,使用平均值和百分位点来统计也是不一样的,通常获取用户在某一场景下需要等待多久,中位数是一个好的度量标准。而且在其中尾部延迟往往很重要,比如99百分位点.最后的百分之一的等待时间也是很重要的。
而且,由于很多客户在使用过程中,无法区分响应时间和排队时间,所以还是需要在客户端测试整体响应时间,为了测试的公正性,也需要客户端独立于响应时间之外不断的发送请求。
在说明了直方图作为查看延迟的一个手段后,作者给出了一些应对负载的方法。
常见的有纵向伸缩和横向伸缩,
纵向伸缩讲的是将机器换为性能更为强大的机器。
横向伸缩则是将负载分布到更多的小机器上。
不过往往做法也是和上面推特针对不同用户的做法类似,将两者结合起来使用
对于无状态的服务,从横向扩展必然合适
对于有状态的服务,横向扩展则需要引入诸如分布式系统来进行保存
而且需要注意,对于每秒十万个请求,每个大小1kb和每分钟3个请求,每个大小2GB的系统处理起来不一样,应该分别针对不同场景选取横向还是纵向扩展。
本章最后提到了可维护性,可维护性常见于在项目开发后期或者交付后的维护阶段。
那么这里涉及到了一个遗留系统的概念,就是过时的平台
为了增强可维护性,作者给出了三个建议
可操作性,简单性,可演化性.
对于可操作性,作者提出的观点是,是借助运维团队来进行保证,比如进行系统的监控,跟踪问题原因,进行更新软件,定义工作流程等.但这并非从开发者角度出发的,如果是从开发者的角度来说,则是建议去对系统内部的状态提供监控,增强其可见性
增强项目自动化,以及项目的集群化或者无服务化.对于交付时候,需要提供一个良好文档,以及对用户的合理预测,从而提前避免问题。
将项目简化,往往实际开发项目中,必然会伴随着新需求的开发,导致复杂度变高。
对于这样的一个顽疾,最好的办法是进行抽象,将大量的细节隐藏在一个抽象的方法之下,更有效率的进行开发,也增强了可读性。
最后是可演化性 为了在开发过程中,支持更多新的需求
为了增强可演化性,可以借助很多技术工具或者开发模式,比如测试驱动开发,或者重构。
这样,这一章主要说明了一个项目对于非功能性需求,比如安全性,可靠性,合规性,可维护性等方面的实现,比如可靠性说明了软件,硬件,人为不同层次的维护.
可伸缩性,通过介绍负载的概念,来说明如何进行扩展和收缩
可维护性,大致说明了如何利用抽象来增强可维护性。