Flink为了支持多种存储系统,提供了多种读写连接器。诸如Kafka或者RabbitMQ
Flink为Kafka Kinesis, RabbitMQ Nifi 多种文件系统,Cassandra,ElasticSearch 以及JDBC来进行相对应的连接器.
那么我们接下来讨论一下系统常见的连接器,Apache Kafka,文件系统以及Apache Cassandra
1. Kakfa连接器
Kafka对于流处理中并不少见,广泛的应用于获取或者分发事件流,我们了解下Kafka核心概念.
Flink为不同的Kafka版本提供了数据源连接器,Kafka在0.11版本之前,为多个版本提供了专用的连接器,在1.0之后,API一直比较稳定,提供了一个通用的Kafka连接器.
使用方式也是直接将连接器添加到Maven项目中

Flink Kafka连接器会以并行的方式获取到事件流,每个任务都可以从一个或者多个分区读取数据,任务会跟踪每一个负责的分区偏移.
而且这个偏移量的追踪并不依赖于Kafka提供的consumer group偏移量追踪机制.
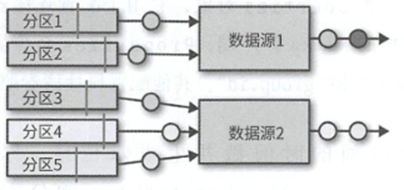
在需要进行恢复的时候,就通过每个任务保存的偏移量处开始恢复.
那么我们创建一个Kafka数据源连接器的代码如下

构造方法需要三个参数,第一个参数是读取主题
第二个参数是一个序列化器
第三个参数是一个Properties对象,至少需要bootstrap.servers和group.id
还有些值得关注的配置项,比如
FlinkKafkaConsumer.setStartFromGroupOffset() 设置读取消费者组最后偏移量
FlinkKafkaConsumer.setStartFromEarliest() 设置读取消费者组最早偏移量
FlinkKafkaConsumer.setStartFromLatest() 设置读取消费者组最晚偏移量
FlinkKafkaConsumer.setStartFromTimestamp (long) 设置消费者组从哪开始读取,
FlinkKafkaConsumer.setStartFromSpecificOffsets(map) 利用Map对象来为分区指定读取位置.
虽然设置了这个配置,不过只有第一次会这么操作,后续出现了故障之后恢复,就会从内部保存的偏移量开始读取.
其次是Kafak数据源如何使用时间算子,为了提取时间戳,来通过调用assignTimestampAndWatermark()方法来向消费者提供一个AssignerWithPeriodicWatermark 或 AssignerWithPunctuatedWatermark对象,从而获取时间戳信息,创建水位线
其次从1.0版本之后,因为消息的元数据带有了时间戳,那么可以自动提取消息的时间戳作为事件时间的时间戳.
Kafka的输出连接器.
对应版本的连接器,也是1.0版本之前,也是提供不同版本的连接器,而之后,而是由于比较稳定,提供了一个通用的Kafka连接器.使用的方式如下

创建的代码如下

创建的构造器还是包含三个参数,分别是Broker的list,写入的目标主题,最后跟着一个序列化器
而且还支持传入Properties,或者给予一个FlinkKafkaPartitioner来控制自定义分区
那么Kafka数据输出算子对至少一次语义是如何保障的呢?
Flink Kafka提供的一致性保障取决于配置,需要Flink本身提供检查点状态.且数据源本身可以重置.
还有就是在生成检查点的时候,理论上算子是不处理任务的,如果允许继续处理,那么就不能局保障
对于精准一次.
首先也需要启用检查点,并提供了可重置的数据源消费数据.
Flink输出算子可以配置一个参数 Semantic参数
这个参数可以选择
Semantic.None,不进行任何保障
Semantic.AT_LEAST_ONCE 至少一次
Semantic.EXACTLY_ONECE 利用事务机制,来保证精确一次的写入.
对于设定了EXACTLY_ONCE的写入,虽然在Kafka中是通过事务进行的提交,但是消费者还是可以通过配置隔离级别读取到尚未提交的消息的.
其次我们说过在数据输出算子的构造函数中可以定义一个FlinkKafkaPartitioner对象,来手动进行相关的分配操作,我们可以使用一个自定义的FlinkKafkaPartitionor来控制数据到分区的路由方式.
其次是Flink提供的文件系统数据源连接器
文件系统简单易用,存储性价比高,可以作为很多分析查询引擎的数据来源,诸如Hive Impala Presto
Flink提供了可重置的数据源连接器,本身集成了在了Flink中,无需添加额外依赖
同时支持多种文件系统,诸如HDFS S3等文件系统.
那么我们先创建一个简单的文件系统数据源

readFile方法的参数包括
传入一个FileInputFormat,负责读取文件内容
读取的目标路径
目标路径读取方式,分别是PROCESS_ONCE或者PROCESS_CONTINUOUSLY,代表着只扫描一次,或者对路径进行周期性的扫描
以及如果配置了PROCESS_CONTINUOUSLY,周期性扫描的间隔.
我们来依次看这些参数
FileInputFormat是一个专门从文件系统中读取文件的InputFormat
首先会扫描路径下的所有文件,并为满足条件的文件创建一些输入划分的对象.每个输入划分定义了文件中的某个范围,这个范围交给起始偏移或者长度决定.但是往往有些文件没法进行拆分,只能作为一个整体读入.
FileInputFormat接下来就是根据自己分配到的输入划分,按照划分来读取文件中的内容.
FileInputFormat还实现了CheckpointableInputFormat接口,定义了生成检查点以及针对某个输入划分重置InputFormat中读取位置的方法
Flink提供了一组继承自FileInputFormat并实现了CheckpointableInputFormat的类,TextInputFormat按照行来读取文件,CsvInputFormat来读取CSV文件,AvroInputFormat可以读取存放Avro编码格式的文件.
如果想要使用文件数据源来搭配事件时间的话,工作可能有点困难,因为输入划分是单个进程中生成的,然后循环发送到所有读取器重,读取器会按照文件修改时间来进行处理,但是文件修改时间并不一定代表事件时间,所以可能需要在任务中再度进行推测最小时间戳.
那么文件系统输出算子
流式输出算子通常会将输出写入多个文件,并且将记录组织到不同的桶中,以便后续的消费.
Flink提供的StreamingFileSink算子也是内置的,并且可以提供端到端得一致性保障.

StreamingFileSink在收到记录后,会分配到一个桶中,每个桶都是StreamingFileSink中指定的基础路径下的一个子目录.
具体的子路径交给BucketAssigner来完成,来为每一个记录返回一个目录BucketId,使用构建器withBucketAssigner()方法配置BucketAssigner,如果没有指定BucketAssigner,会默认使用DateTimeBucketAssigner,来按照处理时间分配到间隔为1小时的子目录下.
每个桶对应的目录下都会包含很多分块文件,交给输出算子进行并行的写入.
文件的路径基本遵循以下的原则
[base-path]/[bucket-path]/part-[task -idx]-[id]
比如一个基础路径为 /johndoe/demo 和分块文件前缀part,得到的路径可能就是
/johndoe/demo/2018-07-22-17/part-4-8
那么这些文件的来源,取决于Sink中的RollingPolicy,可以调用构造器的withRollingPolicy来配置
默认情况下是使用DefaultRollingPolicy,会根据现有文件大小超过128MB或者打开时间超过60秒创建一个新文件.
其次在构造器的上面,我们可以指定分块文件的写入模式,行编码 row encoding和批量编码 bulk encoding.
行编码中,每条记录都会被单独编码到分块文件中
批量编码中,会一批一批的写入,这一点在Parquet中常见.
之后是传入一个StringEncoder,负责进行文件编码,我们使用了SimpleStringEncoding,会调用记录的toString()方法.
最后,StreamingFileSink如何提供精准一次的输出保障呢?实现方式是利用多阶段的状态转换
将文件在不同的阶段之间转移.
正在写入文件的时候,文件会进入处理状态,
如果写完了,那么这个文件会被关闭,进入等待状态
如果检查点生成完成了,那么等待的文件会被进入完成状态
状态之间的转换利用的是文件的重命名保障的.
需要注意,如果没有开启检查点机制,那么可能文件永远不会进入完成状态.
如果出现了故障,那么任务可能会将正在写入的文件重置到上一次成功的检查点.并关闭正在写入的文件,对文件进行截断来完成.
Cassandra的连接器.
Apache Cassandra是一个流行的NoSQL数据库,利用对应的语言,来进行对应的读写操作.
Flink提供了对应的连接器,但需要添加额外的依赖

那么简单的使用这个输出算子的方式如下
| val sinkBuilder: CassandraSinkBuilder[(String, Float)] =
CassandraSink.addSink(readings) sinkBuilder .setHost (“localhost”) . setQuery( “INSERT INTO example.sensors(sensorid, temperature) VALUE S (?, ?);”) .build() |
上面我们给出的数据流中包含的类型是元祖类型
而Cassandra的使用方式最大的不同就在于不同的数据流类型,基本可以分为两类
元组,样例类 或者 POJO类型
上面就是元组,样例类等的使用方式,需要在setQuery中配置一个INSERT查询,这样在使用的是时候,就会自动的映射为对应的参数,这个映射是按照位置进行的.比如元组中的一个值会被转换为第一个参数.
但是诸如POJO的字段,需要利用Object Mapper来进行处理,利用Object Mapper,可以映射POJO中的字段到Cassandra中的字段
这个映射利用的是在字段上面加上注解实现的

除了这两个区别,Cassandra构造器还能提供其他的配置方法.
setClusterBuilder 能传入一个Cluster对象,配置多个主机节点,来进行访问
setHost 简单的主机名和端口的快捷方法
setQuery() 传入一个SQL用于INSERT
setMapperOptions 指定Mapper的一些选项
enableWriteAheadLog([CheckpointComitter]) 开启WAL机制
带有WAL的Cassandra数据输出连接器是基于Flink的GenericWriteAheadSink算子实现的.