那么,本章是了解,为何使用流处理技术,以及传统数据架构的局限性.
那么我们以数据处理的发展为基线来看看流处理技术的优越性.
传统数据处理中,基本上包含的有事务性处理和分析型处理.
事务性处理这一点在现在也有很多应用在使用.往往这些应用在处理处理数据之后,通过执行远程数据库的事务来读取或者更新状态.
但往往是多个服务共享一个数据库,乃至一个数据表,导致如果修改表格式,以及对数据库系统进行扩缩容都是极为困难的.
虽然现在提供了微服务架构,将业务进行解耦,从而优化了上面的数据库单节点问题.
分析型处理,则是创建一个专门用于分析查询的数据仓库,为了填充数据仓库,需要将不同类型的事务性数据库中的数据拷贝过去,转换为一个通用格式进行处理,这个过程被称为ETL,全称 Extract-Transform-Load,而且为了保证数据仓库中的数据同步,ETL过程需要周期性的执行.
而且为了进行查询操作,需要多次执行批处理,从而进行结果获取.
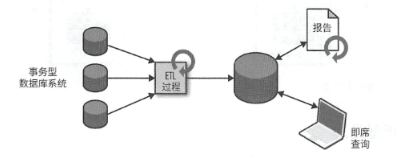
而今天,很多IT企业还是利用Hadoop来进行海量数据日志的查询,批处理.
而无论是网站交互合作和订单下达,以及用户日志,往往都是连续的事件流,而流处理就需要考虑事件不完整的情况下如何形成对应指标.这就涉及到了状态化流处理的工作原理.
任何一个处理事件流的应用,都需要对流数据传输过程的中间状态进行保存,诸如Flink,将应用状态保存在本地内存或者数据库中,而且为了保证分布式的状态一致性,还引入了checkpoint来保存集群一致性状态.
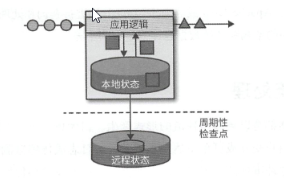
状态化流处理通常需要搭配一个强大的数据来源,常见的是来源事件日志,事件日志将日志追加式的写入持久化日志中,让其顺序无法改变,且支持重复读取.支持上面需求的常见事件日志系统当属Kafka.
那么流状态将两者进行结合,一旦出现问题,流处理系统会利用检查点机制恢复状态并重置事件日志的读取位置,来进行重放输入事件,直到赶上最新的流进度.
而对于流处理,也可以划分几种不同的类型,当然这个类型只是大致划分,往往类型的特点并不是固定使用的.
首先是事件驱动型的应用,这种类型就是收到事件流,从而触发应用业务逻辑.此类应用可以支持触发报警及发送电子邮件等操作.
一般用于监控健康等应用场景.
事务型应用往往需要状态化流处理系统在流转过程中保证事件不丢失,这往往需要流处理引擎提供状态保存,事件时间处理能力,以及对精准一次的保证能力.
其次是数据管道,因为在一个企业中,往往有着不同的数据存储,关系型数据库,分布式文件系统,搜索索引等,其中存储格式也是各有不同,为了在不同的存储系统之间同步数据,传统方式是定期执行ETL作业,但如今已经无法满足延迟方面的需求,于是有些人考虑使用事件日志系统来分发更新,但是这样需要引入一个新的外部系统,来对数据进行归一化处理.有状态的流处理则可以满足这个需求,利用不同的数据源,数据输出,来做到大批量,低延迟的处理插入数据.
最后是流式分析,在传统数据分析中,一般都是在周期的执行ETL作业,从而进行查询.这都是执行批处理,故存在相当大的延迟.
为了减少延迟,最好能够实时收集数据并响应,比如短视频的推送,网购的个性化推荐.
引入了流式分析,流式分析不是周期性地触发,而是持续不断的获取事件流,来整合最新事件,更新结果.
而且对于事件的中间状态,会将其保存在外部数据存储中,也方便外部查询最新状态.
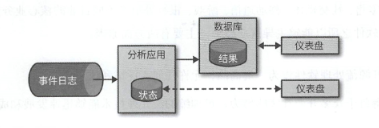
常见于消费应用的实时数据分析.
那么整个流处理技术能够走到今天这一步,也不是一成不变,也是在不断迭代出来的
在早期的流计算中,无法保证结果的准确性,而且处理顺序只取决于事件到达的时间和顺序,顾一条数据可能会被处理多次.为了加强准确性,当时提出了Lambda架构
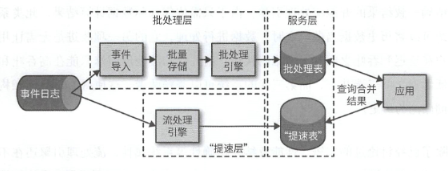
这个架构在传统的批处理架构之上,添加了一个低延迟流处理引擎驱动的提速层
引入了流计算,因为流计算的低延迟性,所以结果出现的很快,并写入提速表
之后在批处理计算出结果后,和提速表中的数据进行合并,去除提速表中非精准的结果.
但是这样也有着相对应的缺点,需要维护两套不同API的处理系统,而且往往在两套系统中的处理逻辑是相同的.
故在不断地迭代中,实现了精准一次故障恢复语义,并且维护了当初了低延迟处理
而且还在不断的融入新的特性,诸如高可用,资源管理框架YARN Kubernetes等