对于Kafka的集群监测
首先需要明确,对于Kafka集群来说,哪些指标是必要的
首先,需要知道并了解broker的执行状态,运行状态,所属版本,底层日志路径磁盘的使用情况.
其次是Kafka运行所需的ZooKeeper运行状态,版本,文件使用情况
Topic分布和分区状态,所有topic分区情况和topic的每个副本存活情况
客户端的运行情况,topic分区情况和每个分区leader副本的存活情况
版本匹配性,是否存在版本适配性
集群中定时作业的运行状态,比如preferred leader选举,分区重分配
对于Kafka具体实现是利用了MBean
利用MBean,这个Java管理扩展来进行对指标的监控.
Kafka内部的MBean的名称表示了其的监控范围,统一的命名格式为
Xxx.type.xxx
第一个xxx是所属的Kafka组件,比如kafka.sever,kafka.producer,kafka.consumer
第二个xxx是表示前面Bean的范围,比如topic=test表示MBean的范围是test的topic
对于JMX的使用,可以Java自带的JConsole工具
比如连接后可以查看topic test1的LEO指标
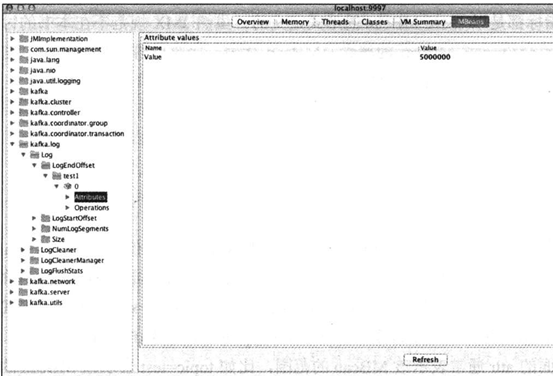
常见的JMX的指标中
Broker端可以监控server network log controller等属性
Clients可以监控producer,consumer,connect,streams等属性
对于JMX的设置,默认是不开启,如果需要烤漆,则需要设置JMX_PROT 环境变量来让其开启JMX监控
比如
JMX_PROT=9997 bin/kafka-server-start.sh config/server.properties
对于不同的broker的JMX端口,可以从ZK中查看
从其中的/brokers/ids/<broker ID> 进行查看详情
![]()
其中指明了jmx_port的端口号
然后对于broker端的详细讲解
其实官网上提供了broker端的常见JMX指标
https://kafka.apache.org/documentation/#monitoring
首先是检测消息的入站和出站的速度
对于消息的入站,很好理解,就是来自于producer端的发送或者leader的发送
对应的指标就是
Kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec
对于出站速度,leader将消息备份给follower leader
Kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec
而且对于这两个指标的检测,同样支持topic级别的粒度
比如
Kafak.server.type=BrokerTopicMetrics,name=BytesInPerSec,topic=test
内部包含一些属性
Controller的存活指标
这是由于controller利用Zookeeper来管理着众多kafka节点,所以需要对其进行监控
利用的指标是kafka.controller:type=KafkaController,name=ActiveControllerCoout
表明当前集群的controller数量,理论上应该为恒定为1,如果长时间为0,那么就需要进行业务人员的介入.
备份不足的分区数
即topic下哪些分区的副本数没有达到最大的分区数
对应的MBean的名称是 kafka.server:type=ReplicaMananger,name=UnderReplicatedPartitions
这个值统计的是整个集群上所有topic的情况,当然,这个值越小越好.
Leader的分区数
kafka.server:type=ReplicaMananger,name=LeaderCount
统计这个broker会存在多少个分区leader副本
这是为了对整个集群的所有broker的MBean的统计,所以可以检测是否某些broker上承载过多的分区leader角色的情况.
Broker IO工作处理线程空闲率
因为每个broker都会创建8个工作线程,有一个指标
kafka.network:type=SocketServer,name=NetworkProcessorAvgIdlePercent来统计
这个值会计算所有IO处理空闲状态的时长和总运行时长的比例,建议不要低于30%
Broker的网络处理线程空闲率
每个broker会创建3个网络处理线程
Kafka提供了kafka.server:type=KafkaRequestHandlerPool,name=RequestHandlerAvgIdlePercent来统计空闲率,也是不要小于30%.
单个topic的字节数
对于计算一个topic的总字节数,Kafka提供了专门的指标
为kafka.log.type=Log,name=Size,topic=<topic>,partition=<partition id>
假设一个topic有10个分区,用户可以查询kafak.log.type=Log,name=Size,topic=test,partition=0
kafak.log.type=Log,name=Size,topic=test,partition=9的字节数,然后相加即可.
Producer端JMX监控
对于Producer端的监控,Kafka提供的指标并不多
但是每一个指标内部的属性却非常多
比如下面一个producer启动后,就只会存在一个console-producer的MBean
除了这个MBean之外,还允许用户指定节点序号和topic,分别从Kafka节点和topic维度来查看相应运行指标,MBean格式分别是
![]()
![]()
对应的consumer端的JMX监控
也是JMX指标不多,属性很多的MBean,包含以下几类
Fetcher-manager 统计consumer 底层 fetch的各种状态信息
kafka.consumer:type=consumer-fetch-manager-metrics,client-id=<CLIENT_ID>
Consumer各个状态信息
kafka.consumer:type=consumer-metrics,client-id=<CLIENT_ID>
Coordinator 统计consumer coordinator
kafka.consumer:type=consumer-coordinator-metrics,client-id=<CLIENT_ID>
Fetcher的JMX包含的公共属性和topic级别的属性
Fetch-latency-avg broker的延时
Bytes-consumed-rate 每秒consumer消费的字节数
Coordinator的属性
Assigned-partitions 统计这个consumer被分配的分区数
Join-time-avg 加入consumer group的平均时间
Sync-time-avg consumer执行组同步操作的平均时间
Commit-latency-avg 统计consumer提交位移的平均延时
Consumer本身的属性
Request-rate consumer平均每秒发送的fetch请求数
Request-size-avg consumer平均每秒发送的fetch请求字节数

对于Kafka的进程
其实也有两个点可以进行监控
分别是
Java.lang:type=OperatingSystem、MaxFileDescriptionCount
Java.lang:type=OperatingSystem、OpenFileDescriptorCount
前者是一个JVM可以打开的最大文件描述符个数
后者是指当前JVM打开的文件描述符个数
一旦前者接近了后者,就需要调整前者的最大值
避免崩盘