这次我们讲解一下DWS的设计思路,我们将数据数据提前传入到了DWM之中
然后就需要考虑进行实际的大屏展示了,由于实时计算的成本问题,所以需要结合实际情况考虑是否有必要建立一个大而全的中间层
如果没有必要,就可以考虑按照不同的指标,建立主题宽表,输出到DWS层
对于DWS,需要首先进行轻度的聚合因为DWS层需要应对实时查询,所以不能是简单的明细
而且将其以主题的方式组合起来,减少维度查询次数
而DWS层需要进行持久化的存储,这里考虑使用的是ClieckHouse数据库,使用C++编写,用于在线分析处理查询OLAP
存储的特点也是列式的存储
对于列的聚合,记数,求和等统计操作的原因优于行式存储
对于其的安装基本如下
1.关闭防火墙
systemctl disable firewalld
2.取消文件数量限制
/etc/security/limits.conf文件的末尾加入以下内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
/etc/security/limits.d/20-nproc.conf文件的末尾加入以下内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
然后进行安装依赖
yum install -y libtool
yum install -y *unixODBC*
然后取消SELINUX
SELINUX=disabled
执行同步操作
xsync /etc/selinux/config
之后下载官网的安装包
https://repo.clickhouse.tech/rpm/stable/x86_64/
并将其上传并安装
rpm -ivh *.rpm
修改其配置文件etc/clickhouse-server/config.xml文件70行,取消注释
![]()
修改后才能让ClickHouse被除本机以外的服务器访问
之后启动ClientHost
systemctl start clickhouse-server
并利用客户端连接服务器
clickhouse-client -m
然后是ClickHouse中的数据类型
首先是整形,包含了有符号整形和无符号整形,浮点数,布尔值,Decimal,字符串,枚举,时间和数组
其采用了和MySQL类似的架构,实际的数据存储交给了表引擎,其支持的表引擎有
TinyLog
以列文件的形式保存在磁盘上,不支持索引
Memory内存引擎,重启就会丢失数据
MergeTree 其中的首推引擎,支持索引和分区
ReplacingMergeTree 上面的MergeTree的变种,支持一个额外的去重能力
基本的创建表语句如下
| create table t_order_rmt(
id UInt32, sku_id String, total_amount Decimal(16,2) , create_time Datetime ) engine =ReplacingMergeTree(create_time) partition by toYYYYMMDD(create_time) primary key (id) order by (id, sku_id); |
其中的引擎指定了ReplacingMergeTree,至于后面的create_time,则和排序有关
Partition by一个可选项,按照一个字段进行分区,降低扫描的范围
对于一个批次的数据写入,会先写到一个临时分区中,不会纳入任何一个已经存在的分区,然后在之后过了一段时间,才会执行合并操作,将临时分区的数据,合并到已有分区中
或者执行
optimize table t_order_mt final;
手动要求合并
然后是primary key,只是一个索引,并不是唯一约束
Order by是其中的必选项,要求分区内的数据按照哪些的字段进行有序的保存
比Primary key还重要
那么我们指定了ReplacintMergeTree,其去重的能力是不稳定的,也就是去重的时间不确定,因为上面的合并时间不确定,而去重的规则首先找order by 字段进行去重,然后将重复的数据保留,取其中排序为1 的
其基本的SQL如下
Inser into 和mysql一致
Update和delete则有所修改
在Click House中,这是被认作为Alter的一种
虽然可以修改和删除,但是并不建议,因为这涉及到删除一个分区并重建一个分区,所以很重
删除的sql基本如下
alter table t_order_smt delete where sku_id =’sku_001′;
修改则是
alter table t_order_smt update total_amount=toDecimal32(2000.00,2) where id =102;
查询操作则和mysql基本一致
那么我们回到我们DWS层的构建上,我们需要将多个topic的表形成一个DWS层的宽表
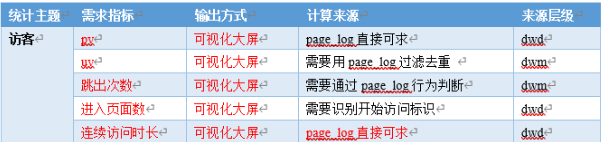
我们将上面中的重要字段,渠道,地区,版本,新老用户进行聚合
整体思路就是讲各个数据流,合并在一起,组成一个相同格式对象的数据流
对合并的流进行聚合,产生一个时间窗口
最终写到数据库中
基本的代码步骤如下
在准备完成基本的Kafka连接环境之后
需要从不同的主题中读取数据
页面数据流
| final DataStreamSource<String> pageDS = env.addSource(
new FlinkKafkaConsumer<String>( Const.TOPIC_DWD_LOG_PAGE, new SimpleStringSchema(), kafkaProp ) ); |
UV数据流
| final DataStreamSource<String> uvDS = env.addSource(
new FlinkKafkaConsumer<String>( Const.TOPIC_DWM_LOG_UV, new SimpleStringSchema(), kafkaProp ) ); |
跳出数据流
| final DataStreamSource<String> jumpOutDS = env.addSource(
new FlinkKafkaConsumer<String>( Const.TOPIC_DWM_LOG_JUMP_OUT, new SimpleStringSchema(), kafkaProp ) ); |
然后将不同的数据流进行map为统一的数据格式,字段如下
| //统计开始时间
private String stt; //统计结束时间 private String edt; //维度:版本 private String vc; //维度:渠道 private String ch; //维度:地区 private String ar; //维度:新老用户标识 private String is_new; //度量:独立访客数 private Long uv_ct=0L; //度量:页面访问数 private Long pv_ct=0L; //度量: 进入次数 private Long sv_ct=0L; //度量: 跳出次数 private Long uj_ct=0L; //度量: 持续访问时间 private Long dur_sum=0L; //统计时间 |
我们就需要将其进行转换为如上格式
由于我们统计的是访客数据,需要的是其中的vc ch ar is_new
那么转换如下
| // 页面流
final SingleOutputStreamOperator<VisitorStats> vsDSByPage = pageDS.map(s -> { JSONObject json = JSON.parseObject(s); return new VisitorStats( json.getJSONObject(“common”).getString(“vc”), json.getJSONObject(“common”).getString(“ch”), json.getJSONObject(“common”).getString(“ar”), json.getJSONObject(“common”).getString(“is_new”), 0L, 1L, 0L, 0L, 0L, json.getLong(“ts”) ); }); // UV流 final SingleOutputStreamOperator<VisitorStats> vsDSByUV = uvDS.map(s -> { JSONObject json = JSON.parseObject(s); return new VisitorStats( json.getJSONObject(“common”).getString(“vc”), json.getJSONObject(“common”).getString(“ch”), json.getJSONObject(“common”).getString(“ar”), json.getJSONObject(“common”).getString(“is_new”), 1L, 0L, 0L, 0L, 0L, json.getLong(“ts”) ); }); // 跳入流 final SingleOutputStreamOperator<VisitorStats> vsDSByIn = pageDS.process( new ProcessFunction<String, VisitorStats>() { @Override public void processElement(String value, Context ctx, Collector<VisitorStats> out) throws Exception { final JSONObject json = JSON.parseObject(value); final String lastPage = json.getJSONObject(“page”).getString(“last_page_id”); if (StringUtils.isEmpty(lastPage)) { // 当前数据为跳入数据 VisitorStats vs = new VisitorStats( json.getJSONObject(“common”).getString(“vc”), json.getJSONObject(“common”).getString(“ch”), json.getJSONObject(“common”).getString(“ar”), json.getJSONObject(“common”).getString(“is_new”), 0L, 0L, 1L, 0L, 0L, json.getLong(“ts”) ); out.collect(vs); } } } ); // 跳出数据 final SingleOutputStreamOperator<VisitorStats> vsDSByOut = jumpOutDS.map(s -> { JSONObject json = JSON.parseObject(s); return new VisitorStats( json.getJSONObject(“common”).getString(“vc”), json.getJSONObject(“common”).getString(“ch”), json.getJSONObject(“common”).getString(“ar”), json.getJSONObject(“common”).getString(“is_new”), 0L, 0L, 0L, 1L, 0L, json.getLong(“ts”) ); }); |
之后利用union合并数据流
final DataStream<VisitorStats> vsDS = vsDSByPage.union(
vsDSByUV, vsDSByIn, vsDSByOut
);
然后我们需要进行时间窗口的聚合
| // TODO 大屏展示时有时效型,所以抽取事件事件和水位线
final SingleOutputStreamOperator<VisitorStats> vsTimeDS = vsDS.assignTimestampsAndWatermarks( WatermarkStrategy.<VisitorStats>forMonotonousTimestamps() .withTimestampAssigner( new SerializableTimestampAssigner<VisitorStats>() { @Override public long extractTimestamp(VisitorStats element, long recordTimestamp) { return element.getTs(); } } ) ); |
然后进行Tuple的分组
| // TODO 对数据进行分组
// 元组:元素的组合 Tuple final KeyedStream<VisitorStats, Tuple4<String, String, String, String>> vsKS = vsTimeDS.keyBy( new KeySelector<VisitorStats, Tuple4<String, String, String, String>>() { @Override public Tuple4<String, String, String, String> getKey(VisitorStats value) throws Exception { return new Tuple4<String, String, String, String>( value.getCh(), value.getAr(), value.getVc(), value.getIs_new() ); } } ); |
然后创建时间窗口
| // TODO 需要设定时间窗口
final WindowedStream<VisitorStats, Tuple4<String, String, String, String>, TimeWindow> vsWindow = vsKS.window(TumblingEventTimeWindows.of(Time.seconds(10))); |
之后将时间窗口内的数据进行居合
| final SingleOutputStreamOperator<VisitorStats> vsReduceDS = vsWindow.reduce(
// TODO 聚合窗口中的数据 new ReduceFunction<VisitorStats>() { @Override public VisitorStats reduce(VisitorStats value1, VisitorStats value2) throws Exception { value1.setPv_ct(value1.getPv_ct() + value2.getPv_ct()); value1.setUv_ct(value1.getUv_ct() + value2.getUv_ct()); value1.setSv_ct(value1.getSv_ct() + value2.getSv_ct()); value1.setUj_ct(value1.getUj_ct() + value2.getUj_ct()); return value1; } }, // TODO 补全时间字段 new ProcessWindowFunction<VisitorStats, VisitorStats, Tuple4<String, String, String, String>, TimeWindow>() { @Override public void process(Tuple4<String, String, String, String> stringStringStringStringTuple4, Context context, Iterable<VisitorStats> elements, Collector<VisitorStats> out) throws Exception { final long start = context.window().getStart(); final long end = context.window().getEnd(); SimpleDateFormat sdf = new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss”); for (VisitorStats vs : elements) { vs.setStt(sdf.format(start)); vs.setEdt(sdf.format(end)); out.collect(vs); } } } ); |
这样处理完成的数据流,就可以写入ClickHourse了
我们首先在ClieckHourse中准备和一个数据库表
| create table visitor_stats_2021 (
stt DateTime, edt DateTime, vc String, ch String , ar String , is_new String , uv_ct UInt64, pv_ct UInt64, sv_ct UInt64, uj_ct UInt64, dur_sum UInt64, ts UInt64 ) engine =ReplacingMergeTree( ts) partition by toYYYYMMDD(stt) order by ( stt,edt,is_new,vc,ch,ar); |
利用ReplacingMergeTree来保证数据表的幂等性
然后修改项目的Pom文件,增加配置项
| <dependency>
<groupId>ru.ivi.opensource</groupId> <artifactId>flink-clickhouse-sink</artifactId> <version>1.2.0</version> </dependency> |
然后准备好对应的参数
我们可以将ClickHourse相关的配置写入环境的上下文中,作为一个GlobalParameters来使用
| Map<String, String> globalParameters = new HashMap<>();
globalParameters.put(ClickHouseClusterSettings.CLICKHOUSE_HOSTS, “http://linux:8123/”); globalParameters.put(ClickHouseSinkConst.TIMEOUT_SEC, “1”); globalParameters.put(ClickHouseSinkConst.FAILED_RECORDS_PATH, “d:/”); globalParameters.put(ClickHouseSinkConst.NUM_WRITERS, “2”); globalParameters.put(ClickHouseSinkConst.NUM_RETRIES, “2”); globalParameters.put(ClickHouseSinkConst.QUEUE_MAX_CAPACITY, “2”); globalParameters.put(ClickHouseSinkConst.IGNORING_CLICKHOUSE_SENDING_EXCEPTION_ENABLED, “false”); ParameterTool parameters = ParameterTool.fromMap(globalParameters); |
然后将其塞入了环境变量中
env.getConfig().setGlobalJobParameters(parameters);
之后就是创建一个ClieckHouseSink()
| Properties p = new Properties();
p.put(ClickHouseSinkConst.TARGET_TABLE_NAME, “itdachang.visitor_stats_2021”); p.put(ClickHouseSinkConst.MAX_BUFFER_SIZE, “10000”); ClickHouseSink sink = new ClickHouseSink(p); vsReduceDS.map( new MapFunction<VisitorStats, String>() { @Override public String map(VisitorStats value) throws Exception { return VisitorStats.transformCSV(value); } } ).addSink(sink); |
不过需要注意,写入的String需要是CSV格式的,然后保存在CSV中
然后我们简单说下如何从Spring中读取ClickHouse的数据
首先添加对应的maven依赖
| <dependency>
<groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.1.3</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.11</version> </dependency> <dependency> <groupId>ru.yandex.clickhouse</groupId> <artifactId>clickhouse-jdbc</artifactId> <version>0.1.55</version> </dependency> |
然后配置相关的参数
spring.datasource.driver-class-name=ru.yandex.clickhouse.ClickHouseDriver
spring.datasource.url=jdbc:clickhouse://linux:8123/default
之后创建一个Mapper文件即可
| @Repository
public interface VisitorStatsMapper { @Select(” select is_new, sum(uv_ct) uv_ct, sum(pv_ct) pv_ct, sum(sv_ct) sv_ct, sum(uj_ct) uj_ct from itdachang.visitor_stats_2021 group by is_new”) public List<VisitorStats> queryVisitorStats(); } |
这样就可以从Controller中读取数据了
这样就基本实现了从DWS层存入数据,并拿出数据的流程