我们说一个正常的数仓DWD层的数据分析之前,我们先总结一下不同的处理函数的区别
比如MapFunction ProcessFunction SinkFunction
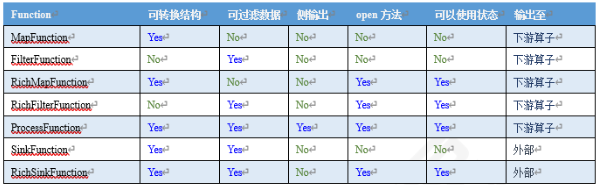
基本总结为上图,上面的图中也可以看出,Rich比简单的Function功能更强大,而唯一能使用侧输出的,只有ProcessFunction
那么接下来,我们继续DWD层的开发
我们通过了分流的手段,将数据分为了独立的topic,这就需要规划topic对应的指标了
基本总结如下
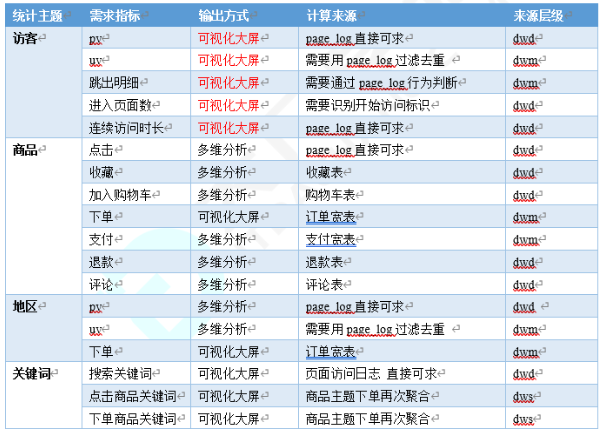
进行了指标的梳理,形成了上面的指标表格
那么,我们就按照上面的指标,依次的书写代码
首先是uv, 独立访客,或者叫做每日的活跃用户
识别的逻辑基本如下
首先是判断这是这个访客打开的第一个页面
然后是访客在这一天内的第一次进入
确认完成后,将数据保存在Kafka中,作为DWM层
那么书写代码基本如下
首先准备一个数据源
| StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); Properties props = new Properties(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, “linux1:9092”); props.put(ConsumerConfig.GROUP_ID_CONFIG, “atguigu”); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, “earliest”); final DataStreamSource<String> kafkaDS = env.addSource( new FlinkKafkaConsumer<String>( “dwd_page_log”, new SimpleStringSchema(), props ) ); |
然后将string转换为一个JsonObject
final SingleOutputStreamOperator<JSONObject> mapDS =
kafkaDS.map(JSON::parseObject);
其次对用户进行分组,按照JSON中的mid进行分组
final KeyedStream<JSONObject, String> jsonKS = mapDS.keyBy(json -> json.getJSONObject(“common”).getString(“mid”));
然后进行用户的过滤,这里我们使用一个RichFilter函数
这里我们需要使用到今日作为一个状态,所以需要在open函数中进行状态的设置
| @Override
public void open(Configuration parameters) throws Exception { // TODO 给状态设定过期时间 final ValueStateDescriptor<String> lastDate = new ValueStateDescriptor<>(“lastDate”, String.class); final StateTtlConfig ondDay = StateTtlConfig.newBuilder(Time.days(1)).build(); lastDate.enableTimeToLive(ondDay); lastDateState = getRuntimeContext().getState(lastDate); sdf = new SimpleDateFormat(“yyyy-MM-dd”); } |
分别给
private ValueState<String> lastDateState = null;
private SimpleDateFormat sdf = null;
属性进行了初始化
然后对数据进行正式的过滤
我们将顺序进行判断
是否存在last_page_id,如果存在,就说明不是第一次的访问,就直接过滤掉
如果没有,就查看跳入时间是不是状态时间,如果一样,就说明是冗余的数据,需要过滤
不一样,则进行数据传输,并更新时间状态,基本上的代码如下
| // TODO 过滤数据
@Override public boolean filter(JSONObject json) throws Exception { // TODO 1. 判断是否存在上一页数据 final String lastPage = json.getJSONObject(“page”).getString(“last_page_id”); if (StringUtils.isNotEmpty(lastPage) ) { // TODO 1.2 如果有的场合,那么说明不是第一回访问,那么直接过滤掉 return false; } else { // TODO 1.1 如果没有的场合,查看跳入时间和当前状态时间是否相同 final String lastDate = lastDateState.value(); final Long ts = json.getLong(“ts”); final String jsonDate = sdf.format(ts); if ( StringUtils.isNotEmpty(lastDate) && lastDate.equals(jsonDate) ) { // TODO 1.1.1 如果相同,那么直接过滤掉 return false; } else { // TODO 1.1.2 如果不相同,那么数据向后传输 // 更新时间状态 lastDateState.update(jsonDate); return true; } } } } |
之后便是创建一个sink,从而将数据再次发出给Kafka
| .map(json->json.toJSONString()).addSink(
new FlinkKafkaProducer<String>( “linux1:9092”, Const.TOPIC_DWM_LOG_UV, new SimpleStringSchema() ) ); |
其次,第二个kpi的计算是跳出率
跳出率就是一个用户访问了网站的一个页面就退出,不在访问网站的其他页面
那么这就需要我们保存哪些只访问一个页面的访客数据
判断的逻辑基本如下
这个页面是用户近期访问的第一个页面,这个可以根据用户是否存在last_page_id来判断,然后很长的一段时间,用户没有访问其他的页面
对于第一个特征,保留last_page_id为空的就可以了,第二个访问的判断,需要使用到CEP技术中的时间观念
基本的框架和上面的UV一致,先是创建一个Source和Map函数,
不过由于涉及到了CEP中的时间概念
所以,需要生成水位线和事件时间
| final KeyedStream<JSONObject, String> midKS = jsonDS.assignTimestampsAndWatermarks(
WatermarkStrategy.<JSONObject>forMonotonousTimestamps() .withTimestampAssigner( new SerializableTimestampAssigner<JSONObject>() { @Override public long extractTimestamp(JSONObject element, long recordTimestamp) { return element.getLong(“ts”); } } ) ).keyBy(json -> json.getJSONObject(“common”).getString(“mid”)); |
然后书写CEP表达式
| final Pattern<JSONObject, JSONObject> pattern = Pattern
.<JSONObject>begin(“start”) .where( new SimpleCondition<JSONObject>() { @Override public boolean filter(JSONObject json) throws Exception { final String page = json.getJSONObject(“page”).getString(“last_page_id”); if (StringUtils.isEmpty(page)) { return true; } else { return false; } } } ).next(“next”) .where( new SimpleCondition<JSONObject>() { @Override public boolean filter(JSONObject json) throws Exception { final String page = json.getJSONObject(“page”).getString(“page_id”); if (StringUtils.isNotEmpty(page)) { return true; } else { return false; } } } ).within(Time.seconds(10)); final PatternStream<JSONObject> ps = CEP.pattern(midKS, pattern); |
第一个where中筛选出了所有不存在last_page_id的
第二个where中筛选出了还有page_id
要求第二个的时间距离必须要在第一个的10s内
这样所有的符合条件的就是用户没有跳出的
这时候我们取反集
| // TODO 对超时数据进行处理
OutputTag<String> timeoutTag = new OutputTag<String>(“timeout”){}; ps.flatSelect( timeoutTag, new PatternFlatTimeoutFunction<JSONObject, String>() { @Override public void timeout(Map<String, List<JSONObject>> map, long l, Collector<String> collector) throws Exception { final List<JSONObject> start = map.get(“start”); // TODO 将每一个超时的数据都放入到侧输出流中 for ( JSONObject json : start ) { collector.collect(json.toJSONString()); } } }, new PatternFlatSelectFunction<JSONObject, String>() { @Override public void flatSelect(Map<String, List<JSONObject>> map, Collector<String> collector) throws Exception { } } ).getSideOutput(timeoutTag).addSink( new FlinkKafkaProducer<String>( “linux1:9092”, Const.TOPIC_DWM_LOG_JUMP_OUT, new SimpleStringSchema() ) ); |
如上面所示,我们只搜集其中的timeout数据,保留到侧输出流中,输出到Kafka中
其次我们涉及到了一个宽表的需求
因为订单是一个非常重要的数据,很多的分析都依赖订单表进行统计
为了统计更加的方便,订单表会被整合为宽表
比如下面的表会被整合为一订单宽表
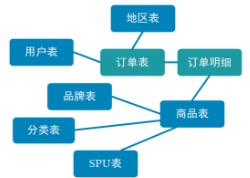
不过我们有两种数据的存储方式,分别对应着事实数据 – kafka,维度数据 – Hbase
我们需要考虑不同维度的整合
分别是事实数据和事实数据关联,也就是流和流之间的关联
事实数据和维度数据关联,也就是流计算之中查询外部数据源
那么我们就按照上面的不同维度的划分,来进行计算不同的代码数据
首先是流和流之间的管理
我们将存在于Kafka的dwd_order_info和dwd_order_detail
为了方便进行序列化和反序列化,我们首先创建对应的Bean
Order_info如下
| @Data
public class OrderInfo { Long id; Long province_id; String order_status; Long user_id; BigDecimal total_amount; BigDecimal activity_reduce_amount; BigDecimal coupon_reduce_amount; BigDecimal original_total_amount; BigDecimal feight_fee; String expire_time; String create_time; String operate_time; String create_date; // 把其他字段处理得到 String create_hour; Long create_ts; } |
Order_detail如下:
| @Data
public class OrderDetail { Long id; Long order_id ; Long sku_id; BigDecimal order_price ; Long sku_num ; String sku_name; String create_time; BigDecimal split_total_amount; BigDecimal split_activity_amount; BigDecimal split_coupon_amount; Long create_ts; } |
然后是Kafka的数据联合
首先分别创建Order_info和Order_detail的数据流
| final DataStreamSource<String> orderDS = env.addSource(
new FlinkKafkaConsumer<String>( Const.TOPIC_DWD_DB_ORDER, new SimpleStringSchema(), kafkaProp ) ); final SingleOutputStreamOperator<OrderInfo> orderInfoTimeDS = orderDS.map( new RichMapFunction<String, OrderInfo>() { private SimpleDateFormat sdf = null; @Override public void open(Configuration parameters) throws Exception { sdf = new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss”); } @Override public OrderInfo map(String value) throws Exception { final OrderInfo orderInfo = JSONObject.parseObject(value, OrderInfo.class); orderInfo.setCreate_ts(sdf.parse(orderInfo.getCreate_time()).getTime()); return orderInfo; } } ).assignTimestampsAndWatermarks( WatermarkStrategy.<OrderInfo>forMonotonousTimestamps() .withTimestampAssigner( new SerializableTimestampAssigner<OrderInfo>() { @Override public long extractTimestamp(OrderInfo element, long recordTimestamp) { return element.getCreate_ts(); } } ) ) |
| final DataStreamSource<String> orderDetailDS = env.addSource(
new FlinkKafkaConsumer<String>( Const.TOPIC_DWD_DB_ORDER_DETAIL, new SimpleStringSchema(), kafkaProp ) ); final SingleOutputStreamOperator<OrderDetail> orderDetailTimeDS = orderDetailDS.map( new RichMapFunction<String, OrderDetail>() { private SimpleDateFormat sdf = null; @Override public void open(Configuration parameters) throws Exception { sdf = new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss”); } @Override public OrderDetail map(String value) throws Exception { final OrderDetail orderInfo = JSONObject.parseObject(value, OrderDetail.class); orderInfo.setCreate_ts(sdf.parse(orderInfo.getCreate_time()).getTime()); return orderInfo; } } ).assignTimestampsAndWatermarks( WatermarkStrategy.<OrderDetail>forMonotonousTimestamps() .withTimestampAssigner( new SerializableTimestampAssigner<OrderDetail>() { @Override public long extractTimestamp(OrderDetail element, long recordTimestamp) { return element.getCreate_ts(); } } ) ); |
然后我们将两者按照相同的id进行分组
final KeyedStream<OrderInfo, Long> orderInfoKS = orderInfoTimeDS.keyBy(info -> info.getId());
final KeyedStream<OrderDetail, Long> orderDetailKS = orderDetailTimeDS.keyBy(detail -> detail.getOrder_id());
之后首先我们考虑利用connect的方式进行两者的连接
这里强调一个概念,就是flink中的join分为两种,分别是基于时间窗口的Time Windowed JOIN
还有就是基于状态缓存的join intervalJoin
我们这里使用interval join,毕竟interaval join的使用更加简单,
在这里我们设置捕获前后五秒的数据进行连接
| final SingleOutputStreamOperator<OrderWide> joinDS = orderInfoKS.intervalJoin(orderDetailKS).between(Time.seconds(-5), Time.seconds(5))
.process( new ProcessJoinFunction<OrderInfo, OrderDetail, OrderWide>() { @Override public void processElement(OrderInfo left, OrderDetail right, Context ctx, Collector<OrderWide> out) throws Exception { out.collect(new OrderWide(left, right)); } } ); |
其次我们会得到一个包含OrderWide的数据流
其次我们将其和HBase进行合并,创建新的数据流
这里我么使用的是异步IO,这里将外部的IO操作进行异步化,单个并行可以连续发多个请求,哪个请求先返回就处理哪个,提高了流处理的效率,也就是AsyncDataStream
那么我们直接看下AsyncDataStream的处理
我们继承了RichAsyncFunction
public class DIMDataFunction extends RichAsyncFunction<OrderWide, OrderWide>
我们首先在open函数中利用文件来模拟HBase的连接
| private Map<Long, Province> prvMap = new HashMap<Long, Province>();
@Override public void open(Configuration parameters) throws Exception { // TODO 将Hbase的操作初始化 // TODO 模仿维度表的查询 – 读取文件 final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); final DataSource<String> file = env.readTextFile(“data/province.txt”); final List<String> datas = file.collect(); for ( String dat : datas ) { final String[] split = dat.split(“\t”); Province p = new Province( Long.parseLong(split[0]), split[1], split[2], split[3], split[4], split[5] ); prvMap.put(p.getId(), p); } } |
其次是连接流,将传入的OrderWide进行加工
| @Override
public void asyncInvoke(OrderWide input, ResultFuture<OrderWide> resultFuture) throws Exception { final Long pid = input.getProvince_id(); final Province province = prvMap.get(pid); input.setProvince_area_code(province.getArea_code()); input.setProvince_3166_2_code(province.getIso_3166_2()); input.setProvince_name(province.getName()); input.setProvince_iso_code(province.getIso_code()); resultFuture.complete(Collections.singleton(input)); } |
最外部的使用如下
| final SingleOutputStreamOperator<OrderWide> orderWideDS = AsyncDataStream.unorderedWait(
joinDS, new DIMDataFunction(), 60, TimeUnit.SECONDS ); |
最终就是标准流程,将数据写入到Kafka的Topic中
| orderWideDS.map(w->JSON.toJSONString(w)).addSink(
new FlinkKafkaProducer<String>( “linux1:9092”, Const.TOPIC_DWM_DB_ORDER_WIDE, new SimpleStringSchema() ) ); |
那么这就基本完成了我们处理DWM层的基本逻辑,将一种明细转换为另一种明细,方便后面的统计
本阶段也介绍了
使用State进行去重
利用CEP进行数据的筛选
使用intervalJoin处理流join
学会处理维度关联,利用缓存和异步查询进行性能优化