已经说完了Flink的基本使用方式,我们需要看下实时数仓还需要的其他组件
因为普通的实时计算过程中,对于数据中间状态没有进行保存,导致的计算的复用性比较差,开发成本成倍的上升
于是提出了实时数仓的概念,将数据进行分层,保存,提高数据的复用性
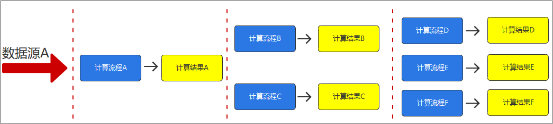
至于为什么分层,这是一个软件开发的基本思路,解耦加提高复用性,这就是分层的主要原因
其中不同的层次可以分为
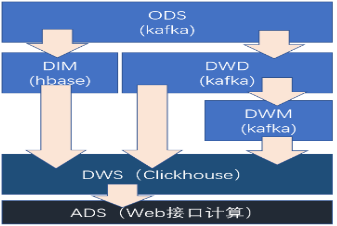
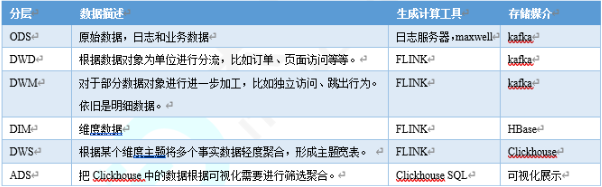
ODS:原始数据,日志和业务数据
DWD,根据数据对象为单位进行分流
DIM 维度数据
DWM 对于数据对象进行进一步加工
DWS 根据某个主题进行轻度的居合,形成宽表
而对于实时数仓的架构,我们可以总结如下

其中对于数据的生成
可以总结为
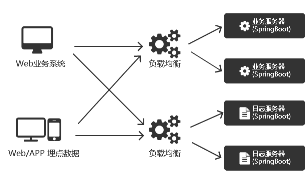
根据负载均衡,最终到服务器上的Agent,然后分别存放在不同的位置
比如业务服务器一般讲数据放在数据库中
而日志服务器则是直接将日志落盘,放在文件中,同时发送给Kafka等
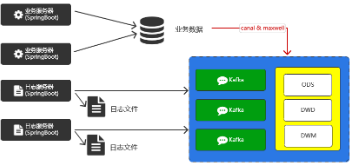
对于日志服务器的架构很简单,直接在落盘的时候发送给Kafka即可
而对于业务服务器,我们不会在代码中直接写代码发送出去,而是用第三方工具,从数据库中拿到数据推送到Kafka中
之后的数据计算,则是交给了Flink

而数据展示,则是从Flink计算并落盘后的存储位置,读取出来,进行展示
那么我们首先看的部分,是业务服务器将数据同步到Kafka的步骤
这里我们说过,会使用一些第三方的工具
比如Maxwell和Canal,两者的对比如下
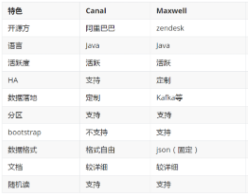
Canal交给Java开发,分为了服务端和客户端,功能稳定,但需要书写代码
Maxwell更为简单和轻量级,将数据直接变为Json字符串进行输出,而且支持导出完整的历史数据
Maxwell的基本原理很简单,就是读取Mysql的binlog,并且要求mysql的binlog为row格式
所以我们首先配置MySQL的config
| # binlog 格式
binlog_format=ROW # 指定具体要同步的数据库 binlog_do_db=gmall_itdachang server_id=1 |
然后安装并配置Maxwell
tar -zxvf /opt/software/maxwell-1.25.0.tar.gz -C /opt/module/
# 修改名称
mv maxwell-1.25.0 maxwell
然后初始化maxwell
首先是在mysql中创建一个库用于存储元数据
CREATE DATABASE maxwell;
其次是创建一个账号用于操作这个数据库
mysql> CREATE USER ‘maxwell’@’%’ IDENTIFIED BY ‘12345678’;
mysql> GRANT ALL ON maxwell.* TO ‘maxwell’@’%’ IDENTIFIED BY ‘12345678’;
mysql> GRANT SELECT ,REPLICATION SLAVE , REPLICATION CLIENT ON *.* TO ‘maxwell’@’%’;
然后配置maxwell的文件
| #配置生产者
producer=kafka kafka.bootstrap.servers=linux1:9092,linux2:9092,linux3:9092 #topic kafka_topic=ods_base_db_m # mysql配置 host=linux1 user=maxwell password=12345678 schema_database=maxwell #需要添加 后续初始化会用 client_id=maxwell_1 |
启动前别忘了创建maxwell的topic
ods_base_db_m(一个分区,2个副本)
然后启动maxwell
/opt/module/maxwell/bin/maxwell –config /opt/module/maxwell/config.properties >/dev/null 2>&1 &
接下来我们需要搭建一个Java项目来进行消费并存储数据
| <properties>
<java.version>1.8</java.version> <maven.compiler.source>${java.version}</maven.compiler.source> <maven.compiler.target>${java.version}</maven.compiler.target> <flink.version>1.13.1</flink.version> <scala.version>2.12</scala.version> <hadoop.version>3.1.3</hadoop.version> </properties> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-cep_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-json</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.68</version> </dependency> <!–如果保存检查点到hdfs上,需要引入此依赖–> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <!–Flink默认使用的是slf4j记录日志,相当于一个日志的接口,我们这里使用log4j作为具体的日志实现–> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.25</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.25</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> <version>2.14.0</version> </dependency> </dependencies> |
然后就可以利用从Kafka中消费数据进行存储了
但是需要注意,Maxwell是将所有的数据统一的写入到一个Topic中,包括业务数据和维度数据
我们需要在Flink中,将其进行分流,写入到不同的地方
而如果分辨哪些数据是作为维度表,哪些数据是作为事实表的呢?
是不建议写到配置文件中,而是可以考虑写到诸如Zookeeper或者Mysql中,进行感知获取的
我们先利用之前说的CDC,从MySQL中读取表配置,并对数据进行分流
那么我们首先编写datasouce从kafka中读取数据
本质上并不困难
| DataStreamSource<String> kafkaDS = env.addSource(
new FlinkKafkaConsumer<String>( “ods_base_db_m”, new SimpleStringSchema(), properties) ); |
首先是一个DataSource
同时我们对数据进行简单的ETL
| SingleOutputStreamOperator<JSONObject> filteredDS = jsonObjDS.filter(
new FilterFunction<JSONObject>() { @Override public boolean filter(JSONObject jsonObj) throws Exception { System.out.println(jsonObj); boolean flag = jsonObj.getString(“table”) != null && jsonObj.getString(“table”).length() > 0 && jsonObj.getJSONObject(“data”) != null && jsonObj.getString(“data”).length() > 3; return flag; } } ); |
这里只不过是转换为Json对象并判断其中字段是否为空罢了
其次是一个MySQL的数据流
这里使用的是之前提到过的CDC连接流
| DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname(“linux1”) .port(3306) .username(“root”) .password(“123456”) .databaseList(“test”) .tableList(“test.table_process”) .deserializer(new MyDeserializationSchemaFunction()) .startupOptions(StartupOptions.initial()) .build(); |
在其中我们传入了自定义的解析器,将其进行初始化处理
| public static class MyDeserializationSchemaFunction implements DebeziumDeserializationSchema<String> {
@Override public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception { //定义JSON对象用于存放反序列化后的数据 JSONObject result = new JSONObject(); //获取库名和表名 String topic = sourceRecord.topic(); String[] split = topic.split(“\\.”); String database = split[1]; String table = split[2]; //获取操作类型 Envelope.Operation operation = Envelope.operationFor(sourceRecord); //获取数据本身 Struct struct = (Struct) sourceRecord.value(); Struct after = struct.getStruct(“after”); JSONObject value = new JSONObject(); // System.out.println(“Value:” + value); if (after != null) { Schema schema = after.schema(); for (Field field : schema.fields()) { String name = field.name(); Object o = after.get(name); // System.out.println(name + “:” + o); value.put(name, o); } } //将数据放入JSON对象 result.put(“database”, database); result.put(“table”, table); String type = operation.toString().toLowerCase(); if (“create”.equals(type)) { type = “insert”; } result.put(“type”, type); result.put(“data”, value); //将数据传输出去 collector.collect(result.toJSONString()); } @Override public TypeInformation<String> getProducedType() { return TypeInformation.of(String.class); } } |
这样就具有一个从Kafka读取数据,并将其转换为JsonObject
一个从MySQL中读取数据,将其转换为String
接下来,我们需要考虑到,如何将两者进行结合,形成一道流,方便我们根据Mysql中的定义来处理Kakfa数据
因为我们定义了多个Kafka数据流,这就有一个问题,要求MySQL数据流一对多,这就使用了Flink中的一个广播流的定义
| MapStateDescriptor<String, TableProcess> mapStateDescriptor = new MapStateDescriptor<>(“table-process”, String.class, TableProcess.class);
BroadcastStream<String> broadcastStream = mysqlDS.broadcast(mapStateDescriptor); |
接下来创建为一个连接流
BroadcastConnectedStream<JSONObject, String> connectedStream = filteredDS.connect(broadcastStream);
并准备一个侧输出流
方便日后保存在Hbase中
OutputTag<JSONObject> hbaseTag = new OutputTag<JSONObject>(“hbaseTag”){};
并对连接流进行新的处理
final SingleOutputStreamOperator<JSONObject> readtimeDS = connectCS.process(new TableProcessFunction(hbaseTag, mapStateDescriptor));
这里我们去实现了一个Rick的processFunction
public class TableProcessFunction extends BroadcastProcessFunction<JSONObject, String, JSONObject>
首先是MySQL的数据流的处理
我们将其从String转换为一个Json,并保存到上下文中
| // CDC配置数据流
@Override public void processBroadcastElement(String value, Context ctx, Collector<JSONObject> out) throws Exception { // 将单条数据转换为JSON对象 final JSONObject jsonObject = JSON.parseObject(value); final String data = jsonObject.getString(“data”); final TableProcess tableProcess = JSON.parseObject(data, TableProcess.class); // 输出主题(表)名 final String sinkTable = tableProcess.getSinkTable(); // 源数据表名 final String sourceTable = tableProcess.getSourceTable(); // 操作类型 final String operateType = tableProcess.getOperateType(); // 输出类型: kafka / hbase final String sinkType = tableProcess.getSinkType(); // 将数据保存状态并进行广播 // sku_info:insert final BroadcastState<String, TableProcess> broadcastState = ctx.getBroadcastState(mapStateDescriptor); broadcastState.put(sourceTable + “:” + operateType, tableProcess); } |
这样就保存了一个TableProcess对象,对应的key为表名加操作类型
然后就是利用这个上下文,从而进行分流
| @Override
public void processElement(JSONObject value, ReadOnlyContext ctx, Collector<JSONObject> out) throws Exception { // 取出状态信息 final ReadOnlyBroadcastState<String, TableProcess> broadcastState = ctx.getBroadcastState(mapStateDescriptor); String tableName = value.getString(“table”); String type = value.getString(“type”); final TableProcess tableProcess = broadcastState.get(tableName + “:” + type); if ( tableProcess != null ) { final String sinkType = tableProcess.getSinkType(); if ( “hbase”.equals(sinkType) ) { ctx.output(hbaseTag, value); } else if ( “kafka”.equals(sinkType) ) { value.put(“topic”, tableProcess.getSinkTable()); out.collect(value); } } else { System.out.println(tableName + “:” + type + “没有对应的配置数据”); } } |
利用tableProcess中的sinkType,从而放在不同的数据输出流
然后我们还说过,对于DWM层,还存在着事件数据
也就是用户触发的动作数据,举个例子
用户查看页面,会生成页面日志
用户启动APP,会生成启动日志
以此类推,还有曝光数据等
而这些数据,存在于日志之中,以JSON的方式推送到Kafka,那么这一次的最后一点,就是将数据从Kafka中存入DWD层
我们提前准备了三种数据,分别为页面日志 启动日志和曝光日志,进行拆分处理,将拆分后的不同日志写回Kafka的不同主题,作为DWD层
其中页面日志输出到 dwd page log
启动日志输出到 dwd start log
曝光日志输出到 dwd display log
那么整体的代码如下
准备一个环境
| Properties kafkaProp = new Properties();
kafkaProp.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, “linux1:9092”); kafkaProp.put(ConsumerConfig.GROUP_ID_CONFIG, “atguigu-itdachang-log”); kafkaProp.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, “earliest”); final DataStreamSource<String> kafkaDS = env.addSource( new FlinkKafkaConsumer<String>( Const.TOPIC_ODS_LOG, new SimpleStringSchema(), kafkaProp ) ); |
然后准备两个侧输出流
// TODO 声明两个侧输出流
OutputTag<String> startOutTag = new OutputTag<String>(“start”){};
OutputTag<String> displayOutTag = new OutputTag<String>(“display”){};
然后准备一个Process
| // TODO 对读取的数据进行处理,来一条处理一条
final SingleOutputStreamOperator<String> splitStreamDS = kafkaDS.process( new ProcessFunction<String, String>() { @Override public void processElement(String value, Context ctx, Collector<String> out) throws Exception { // TODO 将读取的数据转换为JSON final JSONObject jsonObject = JSONObject.parseObject(value); final JSONObject start = jsonObject.getJSONObject(“start”); if (start != null && start.size() > 0) { // TODO 当前数据为启动日志 ctx.output(startOutTag, value); } else { // TODO 当前数据为埋点数据 out.collect(value); // TODO 如果是曝光数据,应该有特殊处理 final JSONArray displays = jsonObject.getJSONArray(“displays”); if (displays != null && displays.size() > 0) { for (int i = 0; i < displays.size(); i++) { final JSONObject data = displays.getJSONObject(i); ctx.output(displayOutTag, data.toJSONString()); } } } } } ); |
然后将其输出到不同的流中
| // TODO 对不同流进行不同操作(保存到不同主题中)
// 页面数据 splitStreamDS.addSink( new FlinkKafkaProducer<String>( “linux1:9092”, Const.TOPIC_DWD_LOG_PAGE, new SimpleStringSchema() ) ); // 启动数据 splitStreamDS.getSideOutput(startOutTag).addSink( new FlinkKafkaProducer<String>( “linux1:9092”, Const.TOPIC_DWD_LOG_START, new SimpleStringSchema() ) ); splitStreamDS.getSideOutput(displayOutTag).addSink( new FlinkKafkaProducer<String>( “linux1:9092”, Const.TOPIC_DWD_LOG_DISPLAY, new SimpleStringSchema() ) ); |
这样就准备好了DWD层的数据