Kafka的Controller是在整个Kafka中,选举出一个特定的broker,来协调和管理整个Kafka集群的。
那么我们这就讲一讲Kafka Controller的整体架构
Kafka Controller是用来管理所有Kafka的集群的,其在整个集群中只存在一个,而在系统启动的时候,所有broker都会参与controller的竞选,最终有一个胜出。而这个选举,依托的是ZooKeeper,我们也会在下面详细说明具体的流程
Kafka Controller是用来管理集群和协调集群,关于集群的管理,主要分为两个方向,分别是每台broker的分区副本和每个分区的leader 副本信息,这两者都维护了两个状态机,用于管理副本状态和分区状态。
对于副本状态机
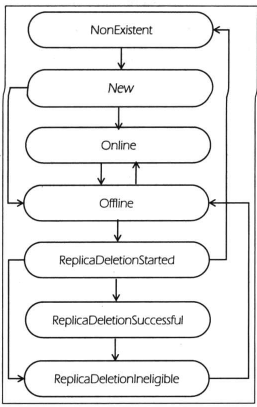
Kafka定义了7种状态来管理副本状态,分别如下
NewReplica controller创建副本的最初状态
OnlineReplica 启动副本后的状态
OfflineReplica broker崩溃后的状态
ReplicaDeletionStarted 开启了topic删除操作,开始删除
ReplicaDeletionSuccessful 响应了删除操作,成功喊出
ReplicaDeletionIneligible 删除失败的状态
NoExistentReplica 成功删除后的状态。
那么整体状态就是,创建某个topic,首先所有副本都是NoExistentReplica,加载分区副本的信息后,状态变成New,然后交给controller决定这个分区中的一个副本作为leader副本,然后在Zookeeper中持久化这个操作。
一旦确定了leader和ISR之后,controller就会将信息发给所有的副本,然后将副本状态设置以为Online。
进行topic删除操作时候,controller就会停止所有的副本,然后设置leader为NO_LEADER,并进入OfflineReplica状态,controller就需要将副本进一步变更到ReplicaDeletionStarted表示开始删除
然后删除失败就是ReplicaDeletionIneligible,进入到ReplicaDeletionSuccessful的副本会被自动的变更到NoExistentReplica进行终止。
整体流程图如下
对于分区状态机
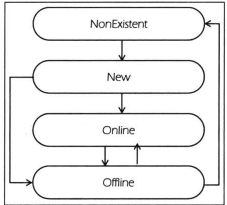
和副本状态机类似,不过管理的对象是分区,只定义了四种状态
NonExistent 不存在的分区
NewPartition 创建后,分区便是这个状态,确定了副本列表,但是没有leader和ISR
OnlinePartition 一旦分区的leader选出,便是这个状态,正常工作
OfflinePartition 选出leader后,若是leader所在的broker宕机,便是这个状态,无法正常工作了。
整体流转便是,创建topic的时候,也会创建分区对象,那么这时候会将状态设置为NonExistent
然后读取Zookeeper进入NewPartition,进行选择leader和ISR,之后设置状态为OnlinePartition
如果进行了删除topic或者关闭broker
就会进入offline操作,如果是删除操作,最终会进入NonExistent状态。
整体流程如下图。
而Kafka的Controller除了这两个状态,还负责维护很多信息,包括
元数据更新信息
创建topic
删除topic
重分配
Preferred leader副本选举
Topic分区扩展
Broker加入集群
受控关闭
Controller leader选举
对于元数据的更新
是一个clients可以对集群中任意一台broker发送METADATA请求来查询对应的topic分区信息
那么所有broker就需要维护这个信息,这个信息也是controller负责在变化后广播的,利用了UpdateMetadataRequests请求,进行了封装,并发送给集群的每一个broker。
创建topic
则是利用Zookeeper的监听,监听/brokers/topics下节点的变更情况,当有topic的变更,其他broker就会变更这个ZNode,从而触发controller的监听者,触发topic创建逻辑,即controller会为新建的topic的每个分区并确定leader和ISR,做完这些操作,controller还会创建一个监听者来监听这个新topic节点的变更,方便得到通知。
删除topic
这样就会在/admin/delete_topics下创建一个ZNode,controller启动之后就会创建一个监听器专门监听这个路径子节点变更的情况,一旦发现有新增节点,则controller开启删除topic逻辑,停止所有副本运行,删除所有副本的日志数据。最后移除 /admin/delete_topics/下的新增节点
分区重分配
目标是对topic中所有分区重新分配副本所在broker的位置,一般是修改ZK下的/admin/reassign_partitions节点
Perferred leader
也是通过向ZK下的/admin/preferred_replica_election节点写入数据,从而修改preferred leader.
Topic分区扩展
是由broker向ZK下的/brokers/topics/<topic>节点下写入新的分区目录
从而交给Controller执行分区创建任务
Broker加入集群
在ZK下的/brokers/ids下创建一个Znode,写入broker的信息
交给controller更新元数据并广而告之。
Broker崩溃
因为Znode的/brokers/ids下的ZNode是临时节点,所以一旦broker崩溃就会被删除,broker子目录消失后controller开启broker退出逻辑,更新元数据。
受控关闭
利用相关的停机脚本来关闭broker,从而让broker执行一些关闭逻辑。诸如这时候broker会主动向controller发送请求,ControllerdShutdownRequest,发送完成,就会将broker阻塞,直到controller处理完成必要的leader重选举和ISR收缩之后,返回Response确定正常退出。
Controller leader
支持故障转移,如果当前controller发生故障或者显式关闭,Kafka能够及时选出新的controller,
具体操作,就是所有的broker都会监听ZK上的/controller节点,一旦失效,所有的broker都会抢着成为controller,成为新的节点之后,就会更新/controller_epoch节点的值。
Controller的组件,基本由下面构成
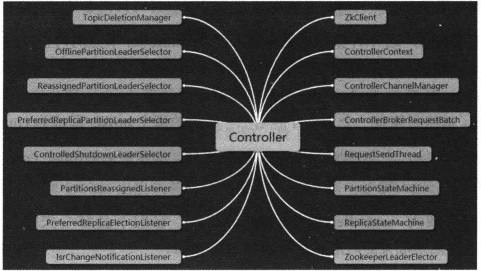
基本可以分为数据类,基本功能类,状态机类,选举器和监听类
首先是数据类
Controller-Context被称为controller缓存,缓存了Kafka集群所有的元数据,基本如下图
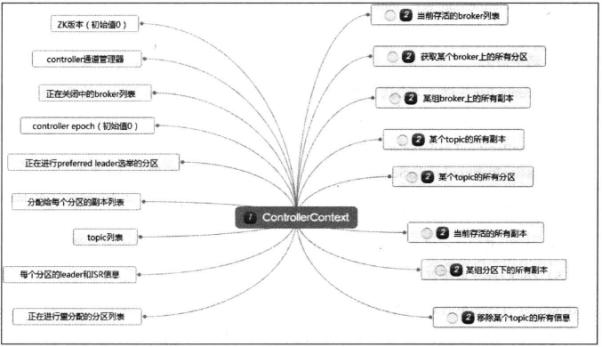
然后是基本功能类
ZkClient,负责和Zookeeper的交互
ControllerChannlManager,controller和其他的broker发送请求,就交给其负责
ControllerBrokerRequestBatch,对发往同一broker的各种请求进行类型分组,进行统一发送提高效率
RequestSendThreadt,负责具体的发送的IO线程
ZookeeperLeaderElector 结合ZooKeeper负责controller的leadar选举
状态机管理
ReplicaStateMachine 副本状态机,负责副本状态流转
PartitionStateMachine 分区状态机,分区状态流转
TopicDeletionManager topic删除状态机,处理删除topic的状态流转。
选举器类
创建了多个选举器类,选举分区的leader选举,而非controller选举。
OfflinePartitionLeaderSelector 常规的分区leader选举
ReassginPartitionLeaderSelector 重分配时的leader选举
PreferredReplicaPartitionLeaderSelector 负责在Preferred leadr选举时进行选举
ControllerShutdownLeaderSelector 受控关闭后的leader选举。
Zookeeper监听器,监听ZK的节点变化,主要维护如下
PartitionReassignedListener 监听ZK下分区重分配路径的数据变更
PreferredReplicaElectionListener,监听ZK下preferred leader选举路径的数据变更
IsrChanageNotificationListener 监听ZK下的ISR列表变化,负责在变化后发起更新元数据请求给集群中所有broker.