本章我们讲解一下Consumer的主要概要
首先是Consumer的group状态机,consumer group具有一定的状态,并且会在不同的状态下进行转换。一共定义了5个状态,分别如下。
Empty 没有任何active consumer,包含位移信息,每个group创建的时候都处于Empty,如果组内不包含任何consumer,也会进入这个状态,
PreparingRebalance 这个group正准备进行group rebalance,已经受理了部分的Join Group请求,会等待一段时间后尝试进入下一个状态。
AwaitingSync 所有成员都加入组等待leader consumer发送分区分配方案
Stable group可以正常工作了
Dead group被废弃了
整个group的基本生命周期变化如下
Group初始化的时候,状态为Empty,然后有新成员加入的是时候,会变成PreparingRebalance,此时Group会等待一段时间,如果所有的成员都加入了组,那么就会变为AwaitingSync,交给leader consumer进行分组方案分配。
确定完分区方案后,leader consumer将其发给coordinator,然后交给coordinator发给下面组成员,组状态进入Stable状态。
更加具体的状态如下:
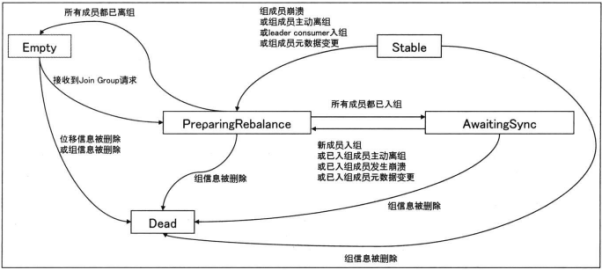
不同状态转变,比如Empty和PrepaingRebalance,当group初始化后,就是Empty,当有一个consumer加入后,就会变为PreparingRebalance,最后所有组成员都离开组,就会变为Empty
Empty也会变为Dead,删除broker上的offset元数据,就会进入Dead
PreparingRebalance和AwatingSync,当进入PreparingRebalance,若是都加入完成了,就会进入AwatingSync状态,
AwaitingSync若是成功同步了leader consumer的方案,就可以进入Stable
Stable和PreparingRebalance,如果有成员离开了group,就会重新进入PreparingRebalance,重新开启一轮rebalance。
而无论什么状态,一旦组信息被删了,就会进入Dead状态
从上面可以看出,Kafka讲Consumer group的分配交给了consumer,而非Broker实现,这样做有两个好处。
1. 便于维护和升级,如果在broker端实现,那么分配策略需要进行Kafka集群的重启,这样的代价极高
2. 方便进行自定义策略,方便自定义的逻辑来实现策略。
其次是group的管理协议
Consumer的状态机可以分为两个阶段,分别是组成员加入阶段和同步状态阶段
我们分别看不同阶段的工作原理
对于第一个加入组,目的是让成员加入group,所用到的协议请求类型是JoinGroup,确定了该group对应的coordinator之后,每个成员都要显式发送JoinGroup给coordinator
封装了各自的订阅信息,成员id等元数据,在所有的group都发送了之后,就会选择其中一个consumer作为leader,给所有组成员发送对应的response。
Coordinator获取到了所有的信息之后,确定所有成员都只支持的分配策略,如果有一个成员的指定策略其他人不支持,那么这个consumer就不被允许加入组。
Coordinator处理JoinGroup的请求后,会将所有consumer成员的元数据封装进一个数组,然后以JoInGroup response的方式发给group的leader consumer,避免其他的成员知晓这些信息。
然后group的所有成员都发送SyncGroup的请求,不过leader consumer在SyncGroup中加入了自己的分区方案,coordinator获取到方案后会抽取每个consumer对应的信息,将其封装后作为SyncGroup的response返回,这样每个consumer都会得到自己对应的分区信息,而不知道其他Consumer的分配方案。
之后就会变为Stable状态,开始正常工作。
在之后,我们看下可能导致rebalance的情景。分别对应着新成员加入组,成员发生了崩溃,成员主动离组
对于新成员加入组,
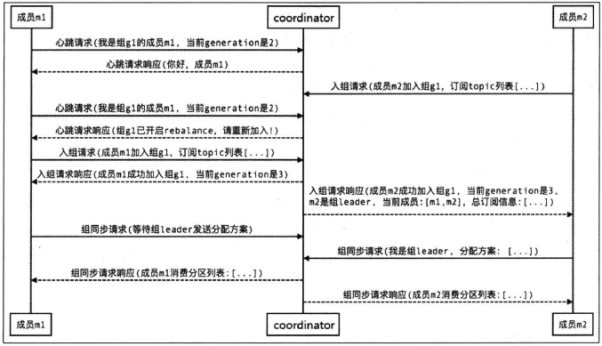
会在加入之后,让所有成员在心跳请求后进入rebalance,重新进行分区。
对于成员崩溃
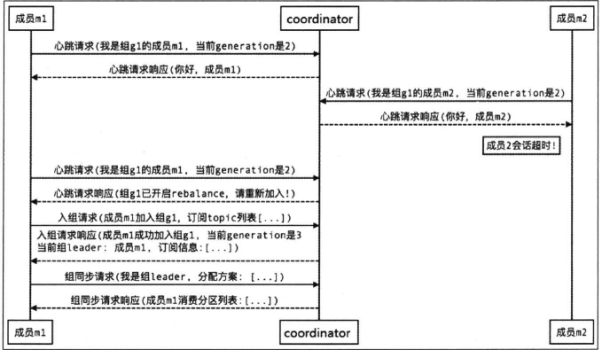
由于崩溃的时候,coordinator并不会立刻知道,所以可能需要一个完整的session.timeout周期才会检测到这个崩溃。
对于成员主动离组

则是和新加入大致一个流程