我们来说一下在Kafka早期版本到现在版本的生产者和消费者
原本Kafka的Producer和Consumer是由Scala实现的,后来利用java版本进行了迭代和替换
基本在kafka 1.0.0之后都替换为了新版本的。
新版本的producer不再依赖于Zookeeper了,基本的逻辑工作图如下
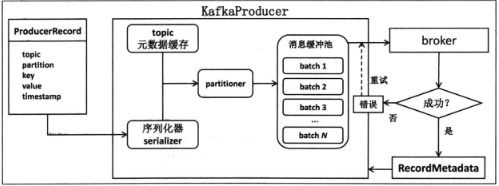
新版本会将消息封装为一个ProducerRecord对象,并利用KafkaProduer.send方法进行发送,然后交给Proudcer对象,进行序列化,并根据元数据信息,写入消息缓冲池,最后交给一个Send线程来发送到broker上。
这样,就将用户的主线程和Sender线程解耦,逻辑上更容易把控。
其次是异步发送消息,提供回调机制来判断发送是否成功
批处理的方式发送,提高了吞吐量
优化了分区策略,在老版本中,对于没有指定key的消息来说,会在一段时间后发送到固定分区,新版本采用轮询,消息发送更加均匀化。
关于新版本的API,如下图所示

重点在于其中的send:消息发送的主方法,close:关闭producer,正确的关闭对于程序来说至关重要
Metrics:获取producer的实时监控数据,比如速率。
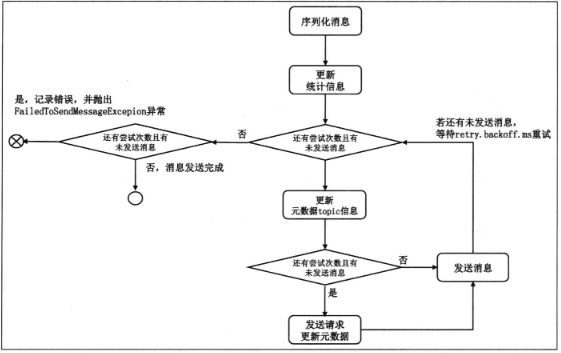
而对于老版本的producer而言,其消息发送是同步,这就导致必须要一条条的发送,因此老版本的producer的吞吐量很慢。整体的工作流程如下图。
提供的API也很有限,基本如下图
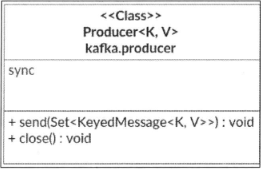
整体只提供了send和close两个方法,设计是非常简陋的。
其次是新版本的consumer和老版本的consumer,新版本的consumer也脱离了Zookeeper的依赖,老版本中,消费位移都保存在Zookeeper中,而在新版本中,位移的管理和保存不再依赖Zookeeper了,自然瓶颈就消失了。
新版本Consumer消费主要依靠的是Kafka的poll方法,这一点类似Linux的epoll,通过一个线程来管理多个链接broker的socket。避免了一个broker一个线程的设计
其次是位移不在保存在Zookeeper中,而是单独保存在一个内部topic中,避免了Zookeeper的频繁读写,也是利用了Kafka自身的高可用机制
最后是改进了消费者组的概念,增加了一个集中式协调者 coordinator的角色,所有成员的管理交给coordinator负责。
提供的API也更加丰富

其中的重点是poll读取消息的核心方法。
还有subscribe 订阅哪些topic的分区
commitSync和commitAsync 手动提交位移
seek 设置位移方法
而对于老版本的consumer而言,其中让人诟病的是分为了high-level consumer 和 low-level consumer
其中low-level consumer是指的单个consumer,没有什么消费者概念,也就是单个消费者,不产生任何的关联。
其api设计的如下

其中还提供了send方法,这个send不是发送消息,而是发送一些具体的请求。
而high-level consumer则是有着只能从上次保存的位移处开始读取消息的问题,无法实现高度定制化的消费策略,所以也是死板的。
基本的API如下

从上面的角度来看,建议大家在任何情况下都是用新版本的kafka。