一,什么是消息引擎
Kafka,通常来说,我们将其称为消息队列或者消息中间件,但是Kafka这类系统,并不能简单的称呼为上面两者,因为其不是简单的以队列的方式实现的,而消息中间件又过度夸张强调了中间件这个概念,实际上更像是一个引擎,具有能量转换,能量传输的能力,故可以称为消息引擎或者消息传输系统。
那么Kafka就是以软件接口为主要形式,来进行异步式数据传递的系统,可以以松耦合的方式集成在不同的系统之间。不过为了集成不同的系统,不同的应用,就需要考虑到两个方面,一是消息设计,二是传输协议设计。
对于消息的设计,Kafka也采用了结构化的设计模式,从而方便后续的处理操作。
其二对于消息传输协议的设计,其定义了消息在不同系统之间的传输方式,诸如阿里的Dubbo,谷歌的Google PB,而Kafka设计了一套二进制的消息传输协议,用于自己的消息传输
在完成上面两个重要模块之后
需要考虑,消息引擎支持何种类型的范型,也就是如何确定不同系统在消息引擎之间如何进行交互的。
常见的交互范型包含消息队列模型和发布订阅模型,消息队列模型是基于队列提供消息传输服务的,定义了消息队列,发送者 接受者三者,提供了一种点对点的消息传输方式,一条消息生产者出来,就会被一个消费者处理
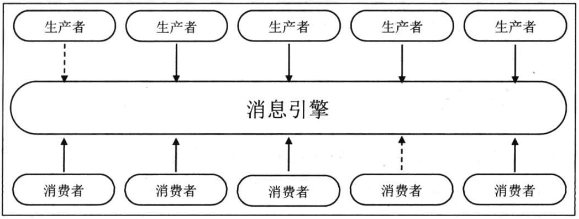
而发布订阅模型则是利用一个逻辑性的topic,并存在发布者和订阅者,发布者将消息生产者出来发布到指定的topic中,订阅者就会接收到订阅topic下的所有消息,通常是所有订阅者都会受到相同的消息。
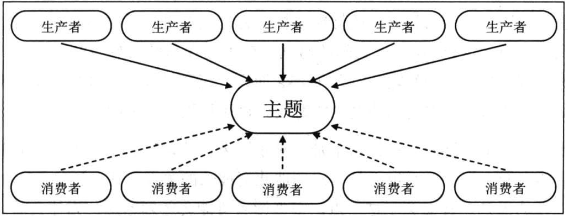
而Kakfa支持两种消息引擎模型,其利用了消息组的概念来进行支持两种模型。
二,Kafka的概要设计
而Kafka在更加具体的设计之中,还考虑到了其他的几个方面的问题
分别是吞吐量及延时,消息持久化,负载均衡和故障转移,伸缩性
1.对于吞吐量这个概念,应该都不陌生,其和延时的概念往往成反比
往往一定时间内的吞吐量升高,就会导致消息的响应延时增加。
对于Kafka这个概念,其如何做到了高吞吐量低延时的呢?首先是Kafka采用了批处理的操作,不再是一条条的消息发送,而是一小批一小批的消息发送,通过增加消息的延迟,来平衡增加吞吐量。
其次是从文件系统开始优化,在消息到达Kafka的时候,Kafka会直接进行落盘操作,其落盘只是将数据写入到了操作系统的页缓存中,然后交由操作系统自行决定什么时候来将页缓存写回磁盘上,并且利用追加写入,来避免磁盘的随机写操作。
因为追加写,导致磁盘拥有更加强劲的利用率,吞吐量也上升了。其次只写入到页缓存,导致在落盘中最慢的IO操作交给了操作系统。
而且使用了页缓存,导致读取的情况下,很多时候都可以直接命中缓存,而不穿透到底层获取消息,从而提高消息吞吐量。
2.对于消息的持久化,Kafka是直接将自己收到的消息直接持久化到磁盘上,这样就减少了内存的使用,而当有请求需要消费数据的时候,再从磁盘中读取。这样就实时保存了数据,又减少了Kafka程序对内存的消耗。
3,对于Kafka的高可用,Kafka提供了负载均衡和故障转移功能
利用提前安排的算法来进行分区领导者选举,利用每一个机器都有机会成为leader,来实现负载均衡。除此外,还提供了故障转移,利用Kafka服务器和Zookeeper服务器之间的心跳来进行检测,当心跳出现问题之后,就会开启故障转移,选举出另外一台服务器来替代这台服务器来提供服务。
4.对于Kafka的伸缩性,也就是讲消息的传递尽可能的交给不同的Kafka服务器,来进行分摊,但是对于消息引擎,往往是具有状态,而Kafka将所有状态交给了Zookeeper保管。内部只保存了很轻量级的内部状态。
三,Kafka的内部概念
接下来我们会讲述下Kafka的一些基本概念
由于Kafka内部的流程不变的还是:
生产者发送消息给Kafka服务器
消费者从Kafka服务器读取消息
Kafka服务器依托Zookeeper集群来进行服务的协调管理
那么我们会围绕上面的三个流程来讲述Kafka的一些基本概念。
1,首先是Kafka的服务器,Kafka的部署服务器有其官方名字“broker“,我们接下来也会以broker作为接下来的服务器代称。
2,Kafka的消息,因为Kafka是一个消息引擎,面向的是不同的系统,所以需要一个统一的消息体,用于存储和消费,大致的消息格式如下
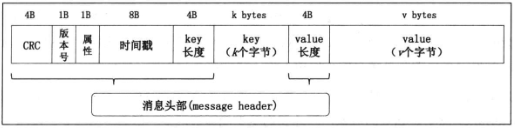
首先是消息的CRC码,消息的版本号,属性,时间戳,键长度(表明后面的key总长度),key,value长度(表明后面的value总长度),value。
对于实际开发中会涉及的字段,分别是Key,Value,TimeStamp
Key是消息键,用于对消息分区,确定保存在哪个topic的哪个partition。
Value是消息体,保存实际的消息数据。
TimeStamp 消息发送时间戳,可以配合后续的流处理,如果不指定就取当前时间。
顺便提一嘴其中的属性,属性是一字节,不过只用了低三位来进行保存消息的压缩类型,比如(1 GZIP ,2 Snappy ,3 LZ4)
而且在代码中,为了减少内存使用,使用的是ByteBuffer而不是独立的对象,方便了后续的扩展,减少了内存占用
3.Kafak的Topic和Partition
我们聊过kakfa的topic和partition,也是Kafka的核心概念
对于topic,是Kafka中的逻辑概念,代表了一个大类的消息,也可以利用topic来进行业务的区分。
但是一个topic并不是直接管理message,而是在message之上,多了一个partition的概念,组成了topic-partition-message的三级结构,一个topic由多个partition组成,kafka的partition具有不可修改的有序消息队列,每个partition拥有自己的编号,从0开始,而message到达了partition之上,就是往消息序列的尾部追加式的写入消息。Partition不具有任何的业务信息,引入其是为了提高吞吐量,实现性能的最大化。
4.将消息写入之后,会保存一个唯一的序列号,这个序列号被称为offset,从0开始顺序递增的整数。利用位移信息来定位一个partition下的一条信息。Kafka的消费端也存在offset的概念,不过两者的目标不同
对于消费者,其会在不断的消费中将offset前移,而对于topic,partition,offset,是用于实际定位一条数据的。
5.由于partition是实际存储消息的,那么为了高可用,不可能只保存一份日志,故有了副本概念,replica,防止数据丢失。其分为两种领导者副本和追随者副本,只有leader负责对外提供服务,而follower只是负责充当其的候补,方便leader挂掉后的选举,成为新的leader对外提供服务
而且为了避免一个物理broker上存在多个replica,因为了一定的算法。
6.ISR,全名in-sync replica,就是与leader replica 保持同步的replica,
Kafka为所有的partition维护一个replica集合,这个集合中所有的replica保存的消息都和leader保持同步状态,同样只有这个replica中的follower可以选举为leader,一条数据也只有同步到了ISR中所有的follower,才会被认为同步完成。而且需要确保ISR中至少存在一个replica,已经提交的消息才不会丢失。
当一些Follower落后于leader的进度一定程度后,就会被踢出ISR,不过在重新追上去之后,又会被Kafka加回到ISR中。