这次我们说下Flink的窗口模式
Flink本身是用于处理无界流数据的,而窗口这个概念,模仿的是TCP连接时候的滑动窗口,将数据按照一定的比例,切分为了大小相同的存储桶
这是因为流处理中数据是不间断的,于是我们不能等所有的数据来了再处理,于是考虑按照某种粒度,将数据聚合起来,比如计算过去一分钟有多少用户点击,这样聚合为一个窗口,来进行计算
而在Flink之中,窗口可以分为两类
1. 时间窗口
2. 元素窗口
在时间窗口中,也是分为了滚动时间窗口和滑动时间窗口
滚动时间窗口是将窗口的大小设定为固定大小的,并且保证不会出现数据的重复
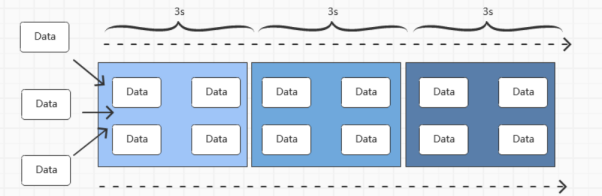
适合进行BI类型的统计,假设我们有一个10s的滚动时间窗口,那么每过10s,就启动一个新的窗口
对应的示例如下
| StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator<WaterSensor> sensorDS = env .socketTextStream(“hadoop102”, 9999) .map(new MapFunction<String, WaterSensor>() { @Override public WaterSensor map(String value) throws Exception { String[] dats = value.split(“,”); return new WaterSensor( dats[0], Long.valueOf(dats[1]), Integer.valueOf(dats[2]) ); } }); //有了一个Operator对象之后,进行开窗口 KeyedStream<WaterSensor, String> sensorKS = sensorDS.keyBy(sensor -> sensor.getId()); WindowedStream<WaterSensor, String, TimeWindow> sensorWS = sensorKS.window(TumblingProcessingTimeWindows.of(Time.seconds(3))); 之后便是对窗口数据的处理 sensorWS .process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() { @Override public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception { long start = context.window().getStart(); long end = context.window().getEnd(); out.collect(“==============================================\n” + “窗口为:[” + start + “,” + end + “)\n” + // “数据:” + elements + “\n” + “数据条数=” + elements.spliterator().estimateSize() + “\n” + “=======================================\n\n”); } }) .print(); |
其次是滑动窗口,跟滚动窗口不同的是,滚动窗口并不保证数据不重复
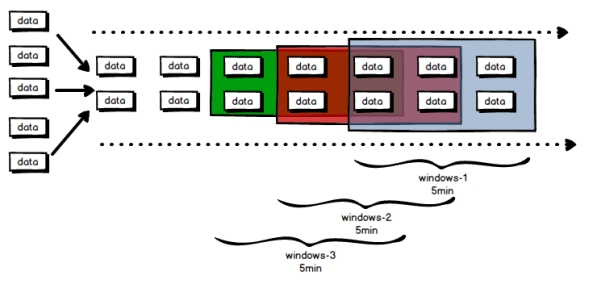
其实就是窗口大小固定 + 滑动幅度
滚动窗口其实可以算是滑动窗口的一种,不过就是滑动的幅度等于窗口的大小
对应的使用也是很简单,只需要在滚动时间窗口之上,在加入一个滚动的幅度
| WindowedStream<WaterSensor, String, TimeWindow> sensorWS = sensorKS.window(SlidingProcessingTimeWindows.of(Time.seconds(5), Time.seconds(3)));
sensorWS .process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() { @Override public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception { long start = context.window().getStart(); long end = context.window().getEnd(); out.collect(“==============================================\n” + “窗口为:[” + start + “,” + end + “)\n” + // “数据:” + elements + “\n” + “数据条数=” + elements.spliterator().estimateSize() + “\n” + “=======================================\n\n”); } }) |
在时间窗口中,还有一种关于会话的窗口
就是以会话为周期,而会话的周期,就是根据数据来的间隔来进行划分的
而这个时间窗口的划分,可以分为静态的时间窗口的划分和动态的时间窗口的划分
静态Gap,就是间隔时间不变,假设Gap为5,那么只要存在5秒的间隔,就认为是新窗口到来
动态Gap,就是根据会话函数返回的时间间隔来动态的确定Session的生成
这里我们先演示静态的Gap
| KeyedStream<WaterSensor, String> sensorKS = sensorDS.keyBy(sensor -> sensor.getId());
WindowedStream<WaterSensor, String, TimeWindow> sensorWS = sensorKS.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10))); sensorWS .process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() { @Override public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception { long start = context.window().getStart(); long end = context.window().getEnd(); out.collect(“==============================================\n” + “窗口为:[” + start + “,” + end + “)\n” + // “数据:” + elements + “\n” + “数据条数=” + elements.spliterator().estimateSize() + “\n” + “=======================================\n\n”); } }) |
上面就传入了一个静态的Session函数,按照10秒进行划分
动态则需要我们实现函数,返回一个long类型对象,来确定下一个Session的时间
| WindowedStream<WaterSensor, String, TimeWindow> sensorWS = sensorKS.window(ProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor<WaterSensor>() {
@Override public long extract(WaterSensor element) { //TODO 动态:根据watersensor的ts字段去动态调整会话时间间隔 return element.getTs() * 1000L; } })); |
其次是元素窗口
这个和时间无关,基本上存在于countWindow函数,是一个滚动的窗口,指定窗口的大小,当元素数量达到窗口大小的时候,就会触发窗口的执行
也是分为了滚动窗口和滑动窗口
滚动窗口,就是当元素的个数达到窗口大小的时候,就会触发窗口的执行
| final SingleOutputStreamOperator<Tuple2<String, Integer>> map = localhost.map(
s -> { int i = new Random().nextInt(5); System.out.println(i); return Tuple2.of(s, i); } ).returns(new TypeHint<Tuple2<String, Integer>>() {}); //形成一个tuple2的数组 final KeyedStream<Tuple2<String, Integer>, String> tsKS = map.keyBy(f -> f.f0); tsKS.countWindow(4).sum(1).print(); |
每隔4个进行一个输出
而滑动窗口,和滚动窗口的函数名完全一致,只不过传入的参数变成了两个,一个是window,size一个是sliding,size,分别表示窗口大小和滚动大小
而这个的输出,则是按照滚动大小决定,只不过每次的输出计算范围是按照windowsize的
| final KeyedStream<Tuple2<String, Integer>, String> tsKS = map.keyBy(f -> f.f0);
tsKS.countWindow(4,2).sum(1).print(); |
然后既然有了窗口,就需要有一个数据顺序的问题
因为大部分的Flink中的DataSource是来源于分布式系统中的不同节点,即使是同一个用户,也可能因为访问到的后端服务器节点不一致导致的其数据的顺序不确定
假设有一个用户,其访问了三次后端,分配到了不同的节点,产生了Log对应在 06:01 06:02 06:03
一般来说,发送到Flink中的数据能按照顺序最好,但是如果发送过程中,到达的顺序有误,导致实际到达的时候,顺序为 06:01 06:03 06:02,这样就导致窗口数据的不准确性
这时候,Flink首先给出了时间概念
分为了三种时间概念
Event time 即事件创建的时间,一般来说,由采集的日志中自带
Ingestion time数据进入Flink的时间
Processing time 进行时间操作的时候算子的本地系统时间,和机器有关系
一般来说,默认的事件属性是Processing time,但是显然,为了确保顺序,我们应该使用Event time
(Flink 1.13.1版本后框架的处理时间语义为Event time)
有了顺序之后,想要保证顺序还是不够的,Flink还提供了另一个属性Watermark
因为顺序的错乱往往是网络传输延迟的导致,那么为了有序,我们可以利用一个机制,延迟等待一段时间,等待之后再对数据窗口进行处理
Watermark实际上是由EventTime创建后自动加入到数据队列中的
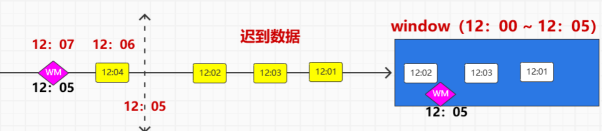
假设我们设定watermark为等待两秒
那么假设一个Windows为00-05
那么一个04秒的数据在06秒到了,因为等待来两秒钟,所以会被加入00-05的窗口的
06-02= 04 ,在00-05的窗口内
指导来一个数据,其Eventtime >=07才会关闭
之前也说过watermark的生成是伴随着数据的进入
而watermark所包含的区间是一个前闭后开的,故为

这样,虽然不能保证所有的乱序数据都是有序的,能接受到的,但是也是尽可能在一个区间内截取了
那么我们看下其api
首先确定一个数据源并将其转换
| final DataStreamSource<String> socketDS =
streamEnv.socketTextStream(“localhost”, 9999); final SingleOutputStreamOperator<WaterSensor> waterSensorDS = socketDS.map( new MapFunction<String, WaterSensor>() { @Override public WaterSensor map(String line) throws Exception { String[] datas = line.split(” “); WaterSensor ws = new WaterSensor(); ws.setId(datas[0]); ws.setTs(Long.parseLong(datas[1])); ws.setVc(Integer.parseInt(datas[2])); return ws; } } ); |
然后在其中明确event time
| waterSensorDS.assignTimestampsAndWatermarks(
WatermarkStrategy .<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(2)) .withTimestampAssigner( (record, ts) -> { return record.getTs() * 1000L; } ) ) |
我们假设了时间延迟为2s
并按照对象中的timestamp进行返回
分组后进行keyby
| .keyBy(ws->ws.getId()) |
之后就是创建窗口函数,我们创建一个滚动窗口
| .window(TumblingEventTimeWindows.of(Time.seconds(5))) |
之后便是对窗口进行处理,使用ProcessWindowFunction
| .process(
new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() { @Override public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception { StringBuilder builder = new StringBuilder(); builder.append(“时间窗口范围[“+new Timestamp(context.window().getStart())+”~”+new Timestamp(context.window().getEnd())+”]\n”); final Iterator<WaterSensor> iterator = elements.iterator(); while (iterator.hasNext()) { builder.append(iterator.next() + “\n”); } builder.append(“*******************************”); out.collect(builder.toString()); } } ).print(); |
上面便是一个简单的延迟数据处理过程
根据Eventtime,来延迟等待一段时间,从而避免乱序数据,和丢失数据
除此之外,为了尽可能的减少数据丢失和记录丢失后的数据,Flink还提供了其他的属性来控制数据的流动
一是在处理流程中,加入了一个属性allowedLateness
这是在延迟数据之外加上了一个新的保险
即在原本延迟2秒的基础之上,再等待3秒
在这3秒之中到达的窗口数据,都会被加入到窗口中,不过会重新计算
也就是会重新触发一次整体的操作
使用方式也是在window函数后面,加上
| .window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(3)) // 迟到数据 |
加上这一个函数,也就是0-5的窗口,但是Eventtime在到达10之前都会触发计算
其次第二个提供则是保证数据没有在窗口及延迟时间和迟到时间之内到达的时候,不会丢失数据
而是将数据放入一个额外的数据流中,对应的API为
SideOutputLateData
需要传入一个OutputTag
使用方式为
| OutputTag<WaterSensor> lateData = new OutputTag<WaterSensor>(“LateData…”){};
.sideOutputLateData(lateData) // 侧(一边)输出流 |
对于这个sideoutput的输出算子的使用
可以如下使用
Process.getSideOutput(lateData).print或者其他输出方式
然后我们上面讲述的,Watermark,是并行度为1的情况下,出现的Flink数据流转
如果并行度为2乃至更多的话,该如何流转
比如有两个Source,同时发送数据
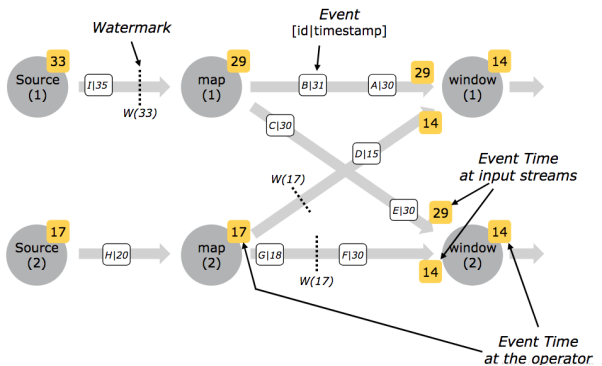
关于多并行度情况下的watermark变化,基本如下
一开始多个watermark默认为 Long.minValue,这时候所有的source中都会记录这个值
然后来了一条数据,假设
Timestamp为1000
那么在Flink中,会将来那条Task的watermark设置为1000-1
但是后面的计算算子并不会把水位线设置为999
而是会比较所有数据源的水位线,以及当前Task的之前的值,取所有中最小的,那么当前线程的值是Long.minValue,故之后计算算子拿到的水位线为Long.minValue,不过在比较出最小值之后,接下来这个Task的水位线就被设置为了999
接下来无论怎么比较,除非所有的Task的水位线都被设置为了999
不然,999就不会成为真正后面计算算子拿到的水位线
当所有的Task都会被设置为了999之后,下一次数据到,水位线才真正是999