现在我们说一下Flink中状态的含义
因为Flink的一个主打有点就是有状态,比如之前讲过的水位传感器,在水位传感器超过了一定的高度,或者水位传感器短时间的增长过大,发出报警,对这样的一个有状态事件进行计算.
Flink中的很多算子都有状态保存,比如source数据源,sink输出,流中的数据也会有一定状态的
算子的状态要简单分为两种
一种是算子状态
同一并行任务处理的所有数据都是可以访问到相同状态,状态这个一个任务内是共享的,算子状态不能由不同的算子访问
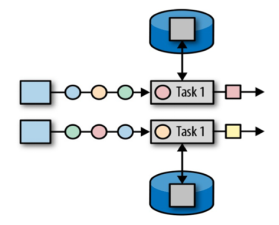
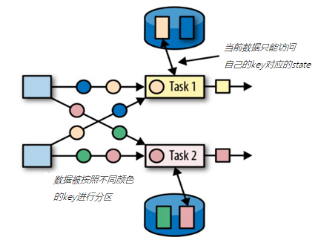
二是 keyed state
根据数据流中的键进行维护的,基于Flink中的keyby操作,为每一个键值维护一个状态实例
因为一个算子任务中对应的键是相同,所以在一个任务处理处理一个数据的时候,可以或这个数据的key对应的数据
Keyed state支持的数据类型如下
Value state[T]保存单个值,值的类型为T
ListState[T] 保存一个列表,值的类型为T
MapState<K,V> 保存键值对
那么我们拿一个小demo来看下Keyed State如何使用
仍然是一个水位偏差的小demo,如果两次的水位偏差超过40cm,就会发出预警信息
首先是一个map
| socketDS.map(
new MapFunction<String, WaterSensor>() { @Override public WaterSensor map(String value) throws Exception { String[] datas = value.split(” “); return new WaterSensor(datas[0], Long.parseLong(datas[1]), Integer.parseInt(datas[2])); } } ) |
然后进行分组
.keyBy(s->s.getId())
然后书写一个process函数
其中我们实现了open函数,其中我们向runtimecontext注册了一个MapState
MapStateDescriptor,声明了name和key value的class
然后再之后的processElement中
我们利用Map中保存的水位,进行对比,大于的则进行报警
| new KeyedProcessFunction<String, WaterSensor, String>() {
// 声明状态对象 private MapState<String, Integer> lastVCMapState; @Override public void open(Configuration parameters) throws Exception { lastVCMapState = getRuntimeContext().getMapState( new MapStateDescriptor<String, Integer>(“last-vc”, String.class, Integer.class) ); } @Override public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception { String id = value.getId(); final Integer vc = value.getVc(); final Integer lastVC = lastVCMapState.get(id); System.out.println(“现在的水位是 =》” + vc ); System.out.println(“以前的水位是 =》” + lastVC ); if ( lastVC != null ) { if ( vc – lastVC > 10 ) { out.collect(“监控点【”+id+”】的水位差为”+(vc-lastVC)+”, 超过阈值10,请及时处理”); } } lastVCMapState.put(id, vc); } } |
在说完了每个算子中,临时状态的保存之后,我们需要考虑一个问题,就是分布式系统中,状态的一致性保存,毕竟Flink是一个分布式计算的框架.固然需要考虑在分布式系统中出现偏差的时候,计算的结果是怎么样的,是可以数据丢失,还是冗余计算
根据不同的情况,流处理也可以分为3个级别
At most once 最多一次,也就是数据只会发送一次,数据可能会丢失
At least once 最少一次,也就是数据至少会处理一次,可能有冗余计算
Exactly-once 精准定位,系统发生了故障也可以保证数据一致
对于Flink,是实现了Exactly-once的,但是也不是只靠自己实现的
而是通过一种端到端的方式,实现了Exactly-once的精准处理
因为Flink将数据的处理分为了三个部分,分别是数据源 计算算子 输出,整个Exactly-once要求每一个组件都要保证他自己的一致性,就好比一个水桶,整个端到端的一致性级别,取决于其中一致性最弱的组件
如果需要保证Exactly-onece,则需要
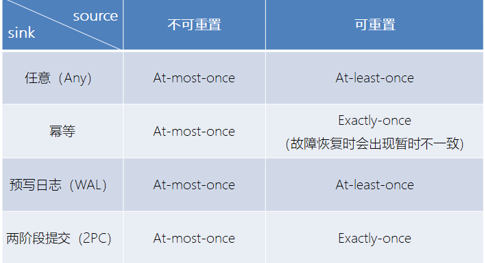
Souce端,需要外部源可重设数据的读取位置
Flink内部 依赖checkpoint
Sink 保证故障恢复的时候,数据不会重复写入数据,常见的实现有幂等和事务写入
对于Source和Sink的不同一致性,可以用下面的表说明
说完了这两个外部因素,对于Flink的内部的保证,则利用了检查点机制,用于记录Flink数据自身的状态
而这样一个机制的具体实现,在Flink中称为检查点机制,交给每一个算子去保证
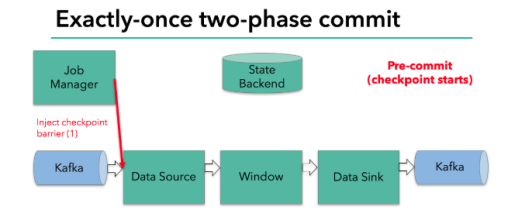
简单来说如上图所示
具体实现是checkpoint是一个持久化在外部的记录
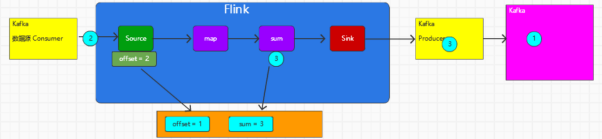
当checkpoint启动的时候,会根据source的偏移量,生成一个检查点分界线 barrier,注入数据流,然后这个barrier会在每个算子之间传递,每个算子看到这个barrier的时候,就会对当前的状态做个快照,保存在后端,然后直到sink,这时候会生存一个commit操作,将barrier之前未提交的数据进行提交消费,并开启新的事物
总结一下整体分工
首先是,source中的偏移量会被保存,再出现故障的时候,可以重新消费
Flink内部有着checkpoint机制,每一个算子会把自己的当前状态保存下来
最后是sink,如果是二阶段提交,那么就会在barrier达到sink的时候,触发commit,之前的数据处理完成操作只是预提交
具体的数据流转,则是
首先第一条数据来了之后,开启一个kafka事务,正常写入kakfa的分区日志文件,但是并未提交
然后job manager触发一个checkpoint操作,barrier生成后从source开始,记录当前的source偏移量,然后一直传入到算子,算子记录自己当前状态,然后交给sink
Sink收到barrier之后 ,通知jobmanager,开启下一阶段的事务
Jobmanager收到所有的任务回调,表示checkpoint完成
Sink收到了jobmanager的确认信息,正式提交这一阶段的数据
外部kafka关闭事务,提交数据可以正常消费了
一个简单的demo如下
首先是开启一个检查点机制
streamEnv.enableCheckpointing(1000);
然后设置checkpoint保存的位置,这里保存在文件中
streamEnv.setStateBackend(new FsStateBackend(“file:///D:/idea/classes/itdachang-0608/cp”));
先设置重试策略
streamEnv.setRestartStrategy(
RestartStrategies.fixedDelayRestart(3, 5000)
);
设置的时重试3次,每次间隔1s
然后设置退出的时候checkpoint文件保存状态,默认是删除checkpoint数据
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
最后创建一个假的数据源,并进行测试,三次后是否退出
| final DataStreamSource<String> stringDataStreamSource = streamEnv.addSource(
new RichParallelSourceFunction<String>() { private boolean run = true; private int count = 0; @Override public void run(SourceContext<String> ctx) throws Exception { while (run) { ctx.collect(“flink kafka”); count = count + 1; TimeUnit.SECONDS.sleep(1); if (count % 5 == 0) { throw new RuntimeException(“Error”); } } } @Override public void cancel() { run = false; } } ); stringDataStreamSource.flatMap( new FlatMapFunction<String, String>() { @Override public void flatMap(String value, Collector<String> out) throws Exception { String[] datas = value.split(” “); for ( String data : datas ) { out.collect(data); } } } ).map( new MapFunction<String, Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> map(String value) throws Exception { return Tuple2.of(value, 1); } } ).keyBy(0).sum(1).print(“sum>>>>”); streamEnv.execute(“State”); |