我们说一下Flink的反压机制
为什么会出现反压的问题呢?是因为消费端和生产端的数据不平衡导致的
如果消费端的速率慢,而生产端的速度很快的话,那么会导致数据不断的积压,以至于Flink本身的内存OOM,为了解决这个压力速率问题,常见的解决方案是
1. 直接丢弃多余的数据(暴力且不推荐)
2. 向Conusmer申请更多的内存,用于存放数据
3. 进行持久化,暂时不处理
而Flink,则是同时存在了静态和动态的处理方式
对于静态的处理方式,则是通过配置生产者的速率及消费者的速率,使两者平衡
对于动态,Flink是利用的TCP的反压机制
我们看下flink的网络传输
一个数据在传输过程中的图如下
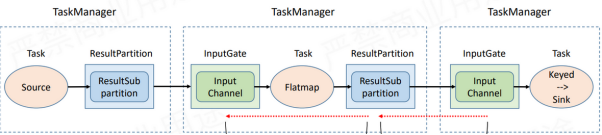
上游的Task向下游的task传输数据的时候,分别有ResultPartition和InputGate两个组件
其中ResultPartition负责发送数据
InputGate负责接收数据
而可以更加细化的分为了,TaskManager内部传输及跨TaskManager传输
首先是跨TaskManager传输,首先是Task的网络分层,从上往下分为了
Task -> InputGate -> Netty -> Socket
无论上游还是下游,在网络传输中,Flink都会存在一个内存上限,更加详细的内存划分如下图
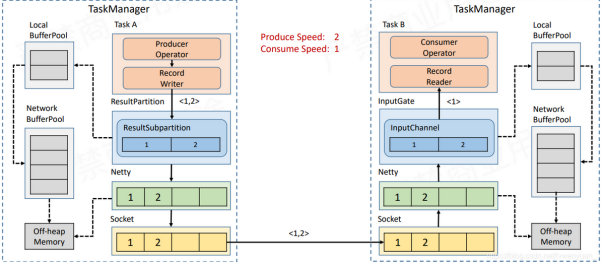
但我们需要注意,无论上游下游,最终都是在一个固定大小的内存池中申请内存
而反压的流程,就是在下游的InputGate数据不被消费者消费成功,一直堆积在IG中,这样最终会导致socket内的缓存被占满,最终上游的Socket也被占满了,以至于不断向上阻塞
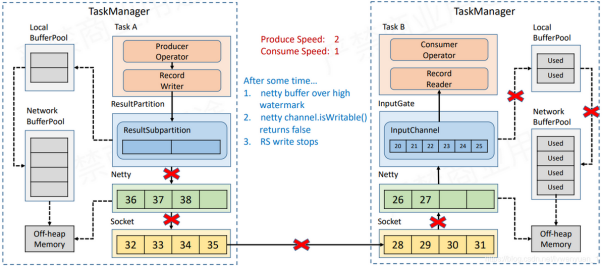
直到阻塞到LocalBufferPool请求内存,以至于RP无法生成数据,这时候,上游就知道阻塞了,这样依次类推,知道第一个Task,使其不再从Source中拉取数据
当然实际的操作中,并不会直接阻塞Netty,因为TM中会有多个Task运行,所以单个Task的反压会阻断整个TM的socket,而其他的task却无法向下游发送数据,连checkpoint的barrier也无法发出.于是Flink模拟出了一套TCP反压流程
名字叫做credit,但是思路基本上是一致的
说完这一个,还需要注意,因为实际使用过程中,存在某些数据存储组件无法进行反压操作,所以还是需要静态+动态