简单介绍过了大数据,我们来看下具体的一些组件,首先是实时数据的存储器,外加传递媒介的Kafka
Kafka本质上来说,是一个消息队列
而一个消息队列的本质工作就是桥接多个系统,一个系统用于发送数据,另一个数据从其中获取数据

而在Kafka,更为具体的消息传递模型如下
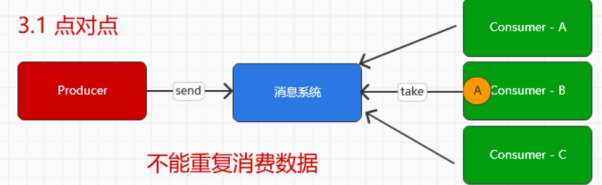
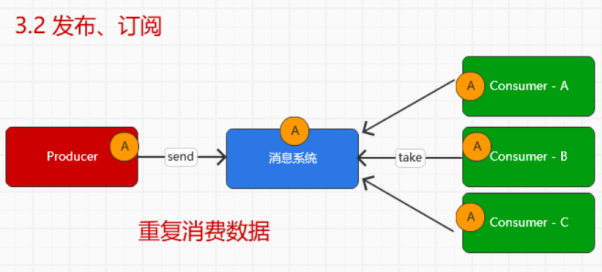
对应的实现的思想,其实在RocketMQ中已经通过源码查看了
而之所以在大数据传递中选择Kafka,除了Kafka是个开元项目,性能足够好,还有就是同类的中间件或多或少的具有一些小问题,
而且一般大数据组件默认都会考虑集成Kafka,所以在现在的开发中,也默认考虑了Kafka作为首要集成的对象
其次是Kafka中的一些组件及概念
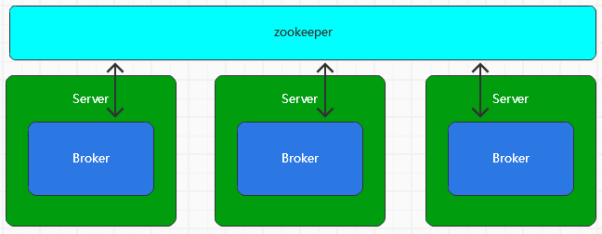
Broker
是Kafka中用来提供消息读写服务的节点,称之为Broker
在整个集群环境下,多个机器组成集群,并提供服务
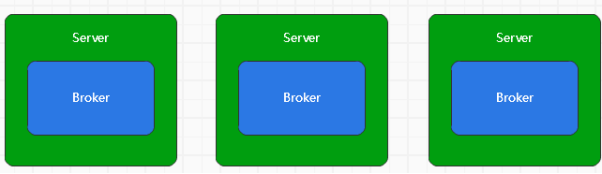
而Broker代表着一个服务节点,多个服务节点之间的管理利用于zookeeper,每个Broker节点在集群中具有唯一性的标识,不能重复
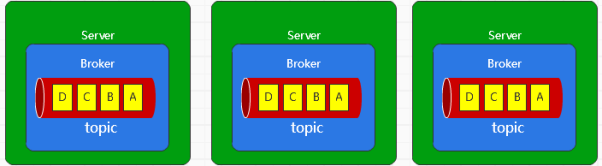
其次是Topic
Topic是承载消息的逻辑容器,用于区分不同的具体业务数据
在Kafka中,作为一个虚拟的概念,用于区分Kafka中不同的数据的类别,也就是消息队列的ID
我们可以在服务器上创建一个Topic进行测试
bin/kafka-topics.sh –bootstrap-server linux1:9092 –create –topic itdachang –partitions 3 –replication-factor 2
首先使用官方指定的sh脚本,然后说明了服务器的地址,当然只需要指定这个集群中任意一个地址即可,其次是topic的名称,再之后指定了partition为3个,replication副本为2个
如果partition和replication不懂的话,先往下看
接下来就可以kafka的控制台上可以看
首先是获取新创建的topic下的分区
然后是任意一个分区的状态
这个分区0很明显的表示了自己的leader是2,也就是broker-id为2的broker
其次是ISR,也就是这个分区存在的所有节点,分别是broker 2 和 broker 1
然后是这个分区如何分配给不同的broker
如果无脑的进行轮询放置,那么必然存在broker-id越小的broker上分区越来越多
所以Kafka会在实际分配分区和副本的时候,首先随机的从集群中找到一个节点存放第一个分区,然后轮询分区到其他的分区
这就是分配的原则,所有的副本要分配尽可能的均匀
Partition
这是一个分区的概念,我们虽然将数据按照主题,分为了不同的虚拟消息队列
但是一个消息队列不能只在一个Broker上存在,所以需要将消息队列中不同的数据分开,每个Broker上放置一部分,用来分开提供服务,基本的模型如下
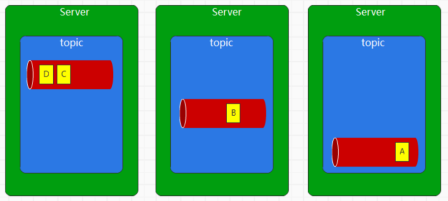
这样topic下的不同子存储,我们称为Partition,将所有分区合在一起就是一个完整的topic
但是如果只是简单的将Topic分为Partition,那么当某一个Broker出现问题的时候,仍然有部分Partition不可用
所以Partition之间仍然需要考虑彼此备份
这就引申了一个新的概念,Kafka的Replica 副本机制
为了保证数据的可靠性,Kafka将Partition在不同的Broker上进行了备份
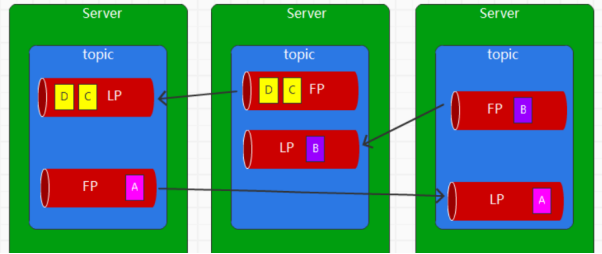
将不同的Partition进行备份,提供了多个副本
其中一个为Leader,其他的副本都是follower
Leader负责读写,follower用于备份
至于具体的存储实体,在Kafka中落盘为了Log文件
其中重要的是数据日志文件,因为分区内部就是一个一定长度的数组队列,新的数据可以追加到这个队列中,数据在这个队列中的位置称为偏移量offset
这样的不断叠加,将磁盘文件,从随机访问变为了顺序写入数据
而文件具有上限的,如果想要快速的消费数据,则需要将文件进行拆分,称为Seqment
当然seqment的上限是可以配置的,在config配置文件中进行设置即可
为了快速的访问文件中的数据,Kafka还会产生索引文件
索引是用来快速查找log文件中的数据的,两者的关系为,log为写入一定量的消息,比如为4KB,这时候会生成一条index记录
这样形成一条如下的图
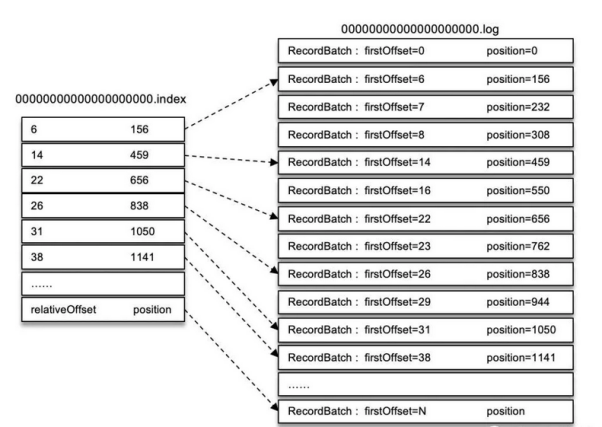
对于数据的查找,就是根据client请求的Offset,在index中进行二分查找
比如offset为23,那么就会在二分查找之后,确定为[22,26]之间
那么就拿着offset 22 对应的position,也就是物理偏移量来log文件中读取,从656之后开始读取,依次找到23的offset对应的record
而且从上面可以看出来,每一个log和index的名字都是一致的,只不过后缀不同罢了
查看日志文件,需要我们使用kafka的对应sh
bin/kafka-run-class.sh kafka.tools.DumpLogSegments –files /opt/module/kafka/logs/test-0/00000000000000000000.log –print-data-log
最后我们查看下Kafka中的RPC请求,这需要我们走部分的源码
首先是一个初始化服务的Scala代码
整个应用程序的main函数中首先初始化了Server
在buildServer中,会根据是否依赖ZK
分别创建KafkaServer和KafkaRaftServer
在KafkaServer中会逐渐创建到SocketServer
以及在SocketServer中创建Acceptor和Processor
开始监听port,并对发来的请求,进行handle
在其中还有一个概念
就是Controller,虽然节点的上下线交给了ZK进行管理,但是消息的分布不能全交给ZK管理,于是Kafka内部存在着利用节点来管理的概念,对应的就是controller
而这个Controller的选举,利用的还是zk,zk中存在临时节点,一旦节点小时,所有的节点都会监听到,然后重新争抢节点,谁先注册成功就是谁的
Controller负责将元数据保存起来,然后同步到其他的broker