数据仓库是存放数据的概念
但是如何构建这样一个存放数据的仓库,以及如何合理的存放数据,是数仓在搭建过程中首先需要考虑的
这样一个数据仓库,是大数据的一种前身,只不过大数据在搭建一个合理的数据仓库的基础上,整合了数据分析,数据展示等一系列的技术体系
数据仓库和数据库在文字上看,是类似的,但是仍有部分的区别
就好比一个仓库和仓库中的一个货架的区别,数据库仍然面对单一应用服务
而数据仓库则是针对一个大型公司,面向不同的部门,建立不同的数据模型,进行数据分析
而在数据仓库的内部,我们队数据仓库进行了分层
分层的概念其实在开发界并不少见,分层的目的都是为了更好的组织,管理,维护数据
而不同的企业对于数据仓库的分层也是不固定的,有的分为了四层,有的分为了五层
首先是ODS 层 Operator Data Store 原始数据层,存放原始数据,或者是原始日志的地方
DWD data warehouse detail DWD层,对ODS层数据进行清洗,去掉空值等,进行脱敏,一行数据代表一次业务行为
DWS data warehouse service DWD为基础,进行轻度的汇总,比如一个动作下一天产生的实际行为
DWT data warehouse Topic DWS 数据进行累计汇总,一行信息代表一个主题对象的累积行为
ADS层, 专为统计报表提供数据的
不同的层级,可以通过表明进行逻辑上的划分
比如ODS层可以以ods开头 ods_表明
Ads为 ads_表明
临时表为 xxx_tmp
而在数据仓库中,除了层级,就是一个维度的概念
其实就是表的划分细粒度问题
如果是一层的,也就是星座模型
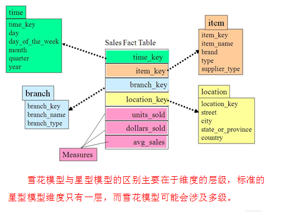
而雪花模型就是更为细粒度,抽象出了多维的概念
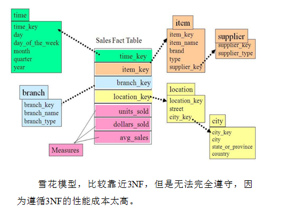
以及星座模型
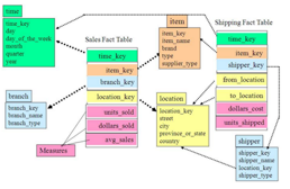
更加复杂,而且具有多个事实表,也就是行为动作触发的业务表,事实表之间还共享一些维度表
而且表也可以根据维度来进行分类
比如上面提到的事实表
其中每行的数据代表一个业务事件,所以非常重要,而且非常的打
其次是维度表,用于对应显示的概念
往往是一些固定的内容,比如编码表这类
而数仓的建立,伴随着大数据技术的发展,也是出现了两种数仓
分别是实时数仓和离线数仓
因为实时数仓的数据统计可能有纰漏,所以需要利用离线数仓进行数据的矫正,两种数仓在早期所使用的技术栈也是不同的
整体的架构如下
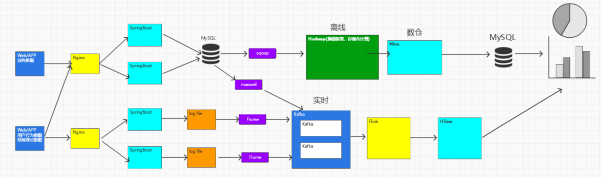
首先是通过mysql和logfile分别进行采集数据
然后分别通过不同的组件,诸如Hadoop和Kafka进行计算,然后存入对应的数仓,最后进行报表展示,我们针对后半段的数据清洗进行讲解
主要的流程就是分别存在实时数仓和离线数仓中的数据
比如在实时数据分析中
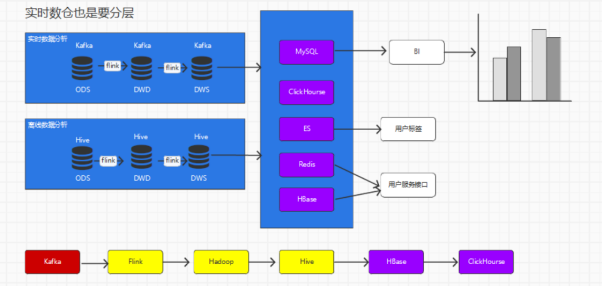
分别使用Kafka 和Hive中读取数据,然后利用fink,spark等进行数据的清洗,然后存入MySQL ClinkHouse ES Redis HBase等组件,最后利用bi等组件进行展示
整体的一个学习技术栈就是
从Kafka开始入手,到Flink 到 Hadoop Hive HBase ClickHouse