本次我们来了解下大数据相关的概念,其次在去学习相关的大数据组件的使用
首先明确什么是大数据
大数据就是一个过大的数据集合,无法用常规的软件进行处理,对应的主要的工作就是海量数据采集 存储 分析计算的问题
主要问题一就是大数据的大
数据量极其的大,需要特定工具去进行处理
然后大数据追求的还有的是快
处理速度快也是大数据的追求,因为企业也在追求数据的高效
之后大数据整体结构中,可以分为两个大模块
分别对应的是上层的分布式数据计算和下层的分布式存储
分布式存储就是多台单机存储系统的各司其职,协同合作,统一对外的提供服务
分布式存储的出现时伴随着单点登录的局限性发展出来的
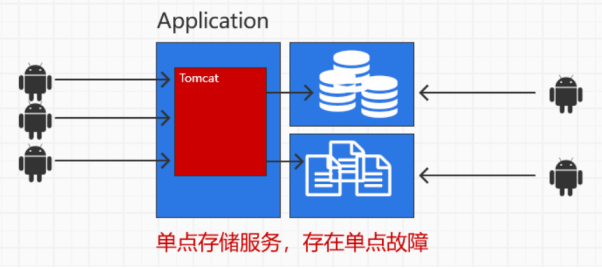
如果出现了单点的故障,那么就会有服务的不可用,故为了高可用,发展出了分布式存储
在分布式存储中,我们将集群分为了两大类,即管理节点和数据节点,亦或者叫 主节点和从节点
而在数据节点中,可以根据数据节点的拓扑关系,确定是不是包含主从之分
更为详细的,可以在后面的组件介绍中详细讲述
其次是在大数据领域的核心,分布式的计算
其思路很简单,就是化整为零,将大人物不断的分割为小的任务,由多台计算机分别计算,最后将计算的结果进行统计输出
那么分布式计算的发展旅程基本如下
首先是利用fork-join的思想,也就是进行分而治之的思想
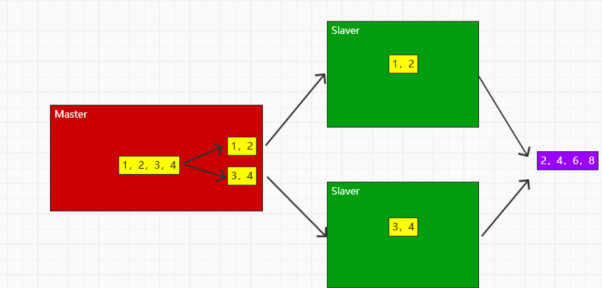
上面的思想中,我们将一个大任务进行了拆解进行了运算
不过还不够彻底,因为在分布式计算的时候,计算的逻辑不应该和Slaver进行绑定,而是希望可以作为任务的输入一部分进行传递,故整体应该如下
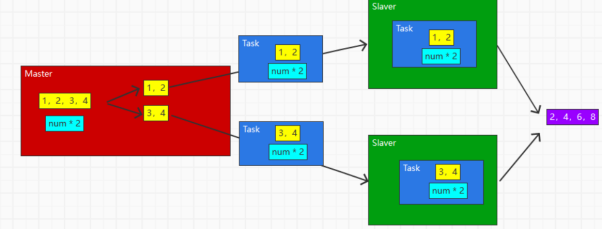
当然,还有一个汇总的步骤,我们没有书写,不过就是在计算完成后对各个子任务进行汇聚
其次需要考虑一个数据存放的位置
应该考虑到数据存放的位置
将数据存放的位置和Slaver计算节点尽可能的绑定,
总结下来是一句话,移动数据不如移动计算