随着系统规模的逐步增长,我们可能预见数据库迁移的需求,常见的有
1.对于MySQL,做了分库分表,需要从单实例转到新的数据库集群上
2.系统从传递集群迁移到云上服务器的时候
3,将MySQL替换为更加专业的系统,诸如HBase
那么,如何保证在整个迁移的过程中,不会长时间停服,不会丢数据
对于更换数据库,我们需要考虑整个迁移过程中任何的异常情况,而且新的系统上线了之后,需要一个磨合的过程,逐步的达到一个稳定的状态,最好还是支持回滚操作,方便数据出现异常
我们拿着订单举例子,
我们需要做一个迁移的方案,将旧库中复制到新库中,旧库还在服务线上服务,然后同步的写入两个库,然后逐步的利用灰度发布进行替换
那么我们的整体方案如下,我们搭建了一个初步同步的数据库,然后保留了一个同步程序,来方便纠错和同步
然后我们改造一下DAO层
让业务写入的时候,支持写入新旧两个库,而且利用一个接口暴露开关,能够通过开关控制三种写状态,只写旧 只写新 同步双写
然后上线的订单服务,首先是读写旧库,不读写新库,新版服务稳定运行一到二周,验证订单库的数据是否正常,新版服务是否有问题,有问题就下线并切换到旧版本的订单服务
出现了同步上的问题,也要及时的记录在日志汇总,避免出现新库影响到现有的业务的可用性和数据准确性
然后切换到双写,注意双写过程,新库是否出现异常,也要记录日志,及时回滚
然后我们开启我们的对比和补偿的程序,比较旧库最近的数据库变化,架构如下
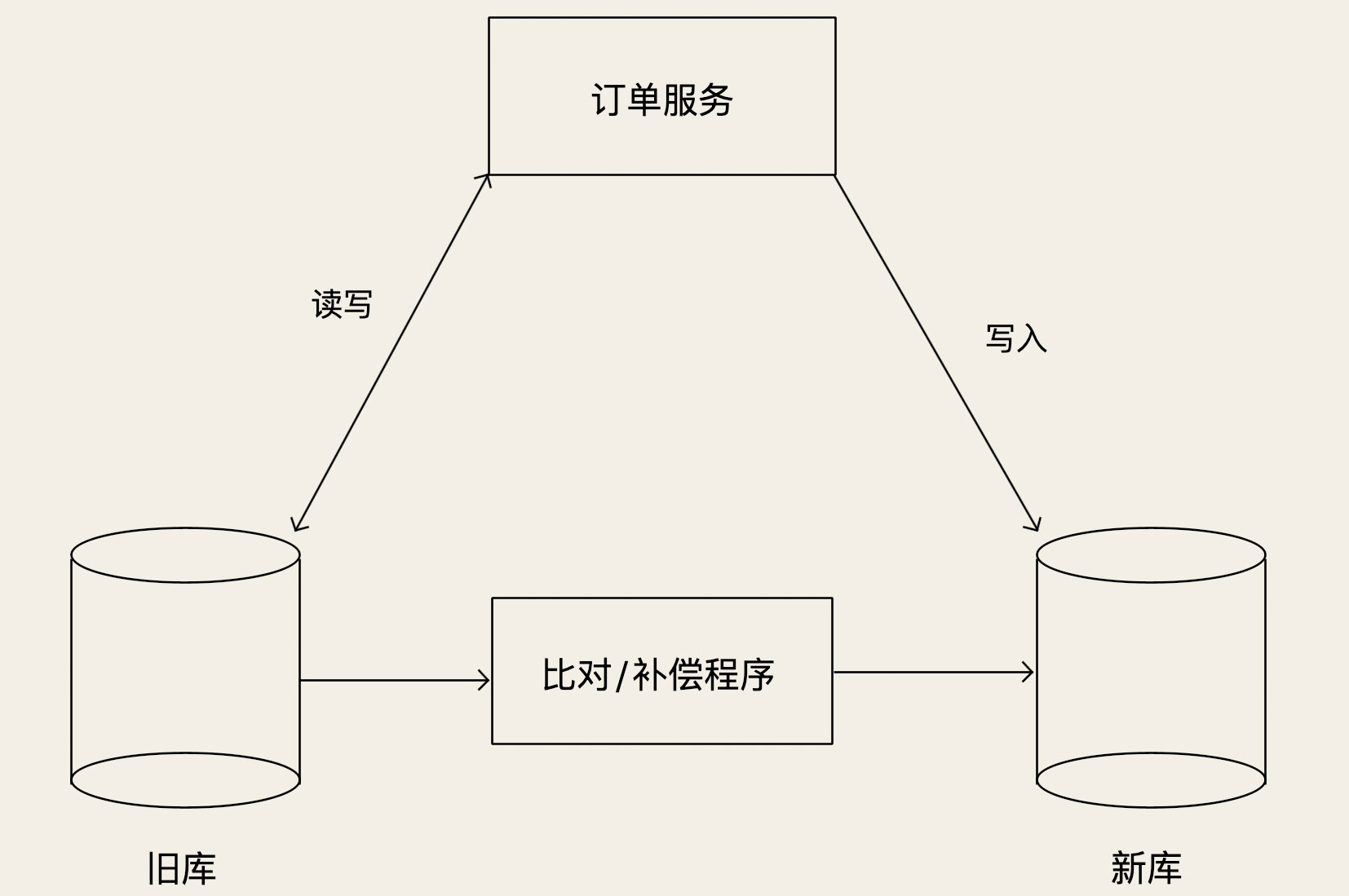
双写开启后,还需要运行一段的事件,检查是否出现新库读写失败的问题,以及数据库不一致的问题,没有出现这类问题后,就可以进行下一步 灰度发布的操作了,将读请求全部切换到新库上,这时候切换完成之后,就可以停掉对比的程序,将订单的写状态完全改为只写新库
这样就基本完成了更换数据库的全部操作
对于对比和补偿程序
我们如何实现一个对比和补偿的程序呢?我们需要对比两个随时都在变化的数据库中的数据,我们需要根据业务实际情况,针对性的实现对比和补偿,比如订单,可以根据订单完成时间,对比并补偿数据
但是像是商品信息这种数据,随时都可能变化,如果数据上有更新时间这个字段,可以利用这个更新时间,在旧库中取一个更新时间窗口内的数据,再新库上找到相同主键的数据进行对比,然后进行对比更新时间,如果新库数据更新晚于旧库数据,说明数据在比对过程中发生了二次的更新,于是先不进行修改,等待下一次时间窗口去继续对比,然后对于时间窗口的选择,最好选择早一点的时间,比如一分钟前,避免对比正在写入的数据
如果没有时间戳这种字段,只能去旧库上去读Binlog,然后进行对比和补偿
在设计一个在线切换数据的技术中,首先要确保安全性,保证每一个步骤都尽可能的可以回滚,然后保证数据在迁移过程中不会丢失数据
我们的整体的流程如下
首先上线同步的程序,从旧库中复制数据到新库中,然后保存同步
上线了双写的订单服务,先读写旧库
然后开启双写,停止同步程序
开启对比和补偿程序,确保新旧数据库数据完全一致
逐步切换读请求到新库上
下线对比补偿程序,关闭双写,读写都切换到新库上
下线旧库和订单服务的双写功能