对于数据分片后,我们对于数据的查询就没有那么自由了,订单表按照用户ID作为Sharding Key来分片,只能按照用户维度来查询,如果是一个商家,就没法按照商家进行查询了,那么是不是需要存一个备份到商家的订单库,专门供商家查询订单
所以,对海量的核心数据的处理,都是根据业务实际的需求,选择数据库和数据结构,而且会分散备份存储到不同的数据库中
多数据库中同步存储如何保持的呢?
我们可以利用本地消息表传递给另外一两个数据库,但是这种方式还是对业务有侵入性,因此,介绍一种常见的解决方案
利用Binlog和MQ去构建实时的数据同步系统
早期时候,很多时候采用的都是ETL工具去定时的同步数据,这就是对实时查询的一个让步,所以这种方式逐渐的被近实时同步取代了
我们可以首先让业务直接将数据存入MySQL中,然后利用Canal将Binlog获取到,然后利用一个MQ进行相关的解耦上下游的工作
Canal从MySQL收到Binlog并解析为结构化后,写入到MQ的一个订单Binlog主题,然后不断消费解析后的Binlog数据
这个MQ的作用不必说,因为Binlog数据不能直接去写下游这么多的数据库,所以需要增加一个MQ来解耦上下游
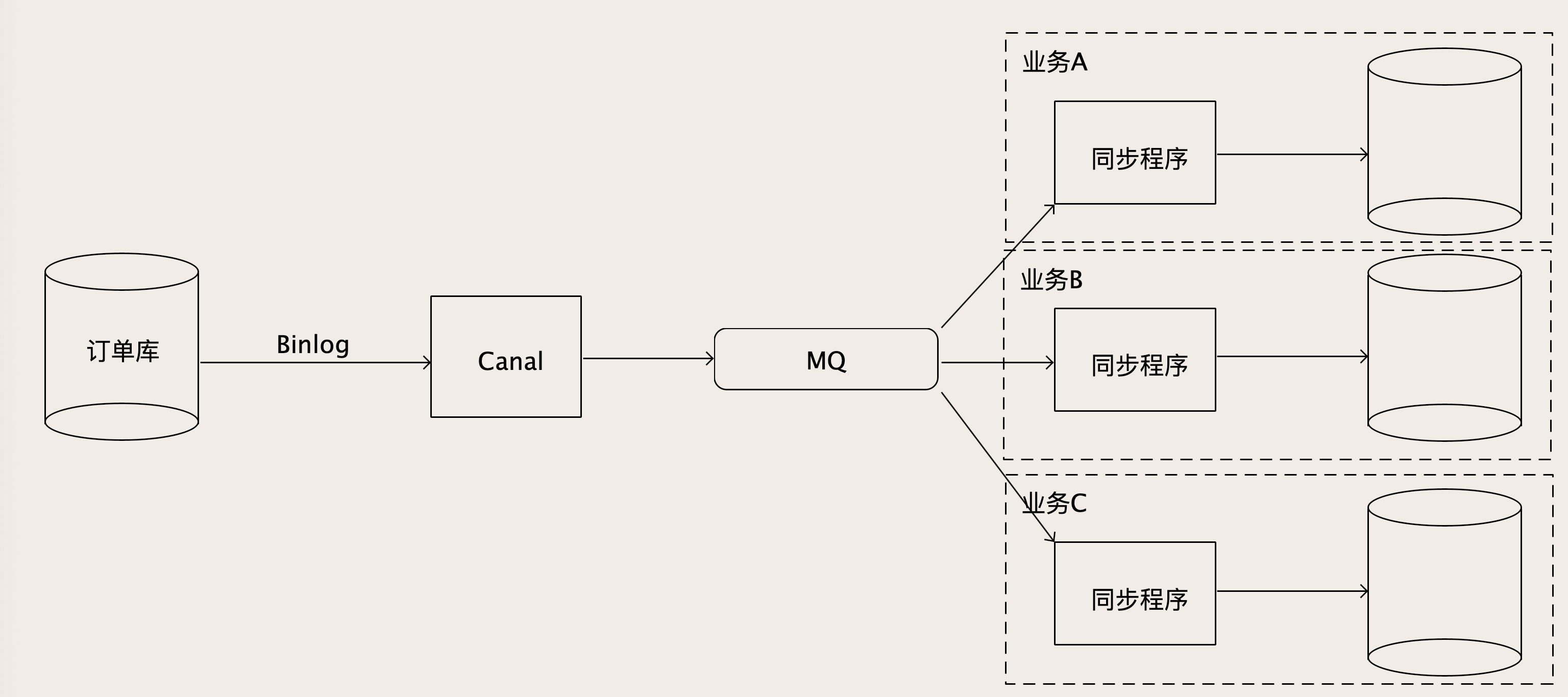
这样每个消费者在自己的同步程序就可以订阅MQ的主题,解析后,在自己的同步程序中,直接入库,或者做些数据转换后入库
这样数据实时性就有了一定的保证,但是,消费者是同步链条中重要的一环,我们必须要跟上处理的速度
所以MQ的消费者,可能成为性能的瓶颈
里面的同步程序都有一些业务逻辑,下游的数据库跟不上,就会将消息积压在MQ中
对于这种没法简单的通过增加实例数来解决的问题,我们该如何办?
毕竟MySQL在主从同步Binlog的时候,是一个单线程的同步过程,因为一个业务相关的数据,必然是由先后顺序的,对于其的解决方案,我们可以利用MQ的分区主题来进行解决,加入我们有A和B两个不同的订单,彼此不产生干扰,我们可以将这两个分到两个不同的MQ主题下执行,从而保证数据有序性的同时增加数据的处理速度
具体的操作如下