众所周知,Reids是一个单线程的模型,这是指Reids的数据操作是由一个线程完成的,但是Redis的很多其他功能,比如持久化,异步删除,集群数据同步等,这些还是异步执行的
那么,我们就来说一下Reids的单线程设计机制和其多路复用的机制
1.Redis为何使用单线程处理数据
对于多线程的系统,可以增加系统吞吐量,但往往因为实际处理过程中,涉及一些公共资源的问题,需要进行共享资源加锁来确保访问正确,从而带来额外的开销
就好比,Redis假设是一个多线程的模型,现在有两个线程去操作一个List,一号线程对List执行LPUSH,使其增加一位数据,二号线程对其执行LPOP操作,使其减少一位,如果不进行并发控制,很可能得到错误的长度结果
为了避免一些并发导致的资源访问问题,Redis采用的单线程模式
2.Redis的单线程为何处理快
先上答案,Redis的单线程并不是完全的单线程,只有在数据操作的时候使用单线程,对于网络交互,采用IO多路复用,增加了吞吐量,避免了单线程的局限性
对于Socket的整体流程
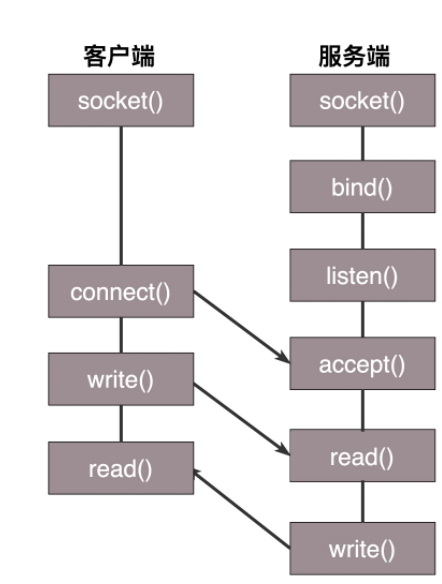
整体如上,需要服务器端,先bind端口,开启listen之后
才能和客户端建立连接,并尝试读取
那么,传统的 Block IO中,如果accept和read出现阻塞,那么就会阻塞服务器端
故,针对阻塞的问题,后来开发并出现了非阻塞的Socket
其就是在accept和send函数中,如果发现数据或者连接没有到达,那么会执行其他的操作,而不是一直阻塞等待
这样,就做到了一个端口,同时监听并处理多个套接字了,一旦有请求达到,就可以交给Redis线程处理
这样就实现了一个Redis线程处理多个IO流的效果,从而实现了高效的网络反应
而且Redis采用了epollde IO模型,一旦出现了网络事件,就会利用红黑树来找到对应的处理函数
从进行相关的处理
那么总结一下
我们简要介绍了Redis的单线程问题,Redis并不是严格的单线程,而是在数据操作方面,只有一个执行线程,而对于网络交互则是采用了高效的IO多路复用的模型
最后一个小问题.Reids基本IO模型图中可以看出,是否有哪些潜在的性能瓶颈
考虑到网络交互,可以采用UDP代替TCP,避免TCP自带的拥塞控制,可以模仿HTTP3.0
对于数据操作方面,单个执行线程必然会出现由于单个操作的内存过大,从而阻塞的问题
对此也没法去消除,只能尽可能的降低其影响,故可以按照数据结构来拆分为多个线程执行,每个数据结构对应着一个执行线程,从而加快执行效率