Redis的快,体现到接收到一个键值对操作之后,能够以微妙级别的速度找到数据,并完成操作
那么这个快的原因,取决于两个方面,一是所有的操作都在内存中完成,二是归功于其数据结构.在这一次的学习中,我们先抛开内存读写,而主要讲述其数据结构.
Reids的数据结构从表面上来看,具有String / List / Hash / Set / Sorted Set 这几个是其数据结构的外在表现,底层的数据结构,则是由 简单字符串 / 双向链表 / 压缩列表 / 哈希表 / 跳表 / 整数数组
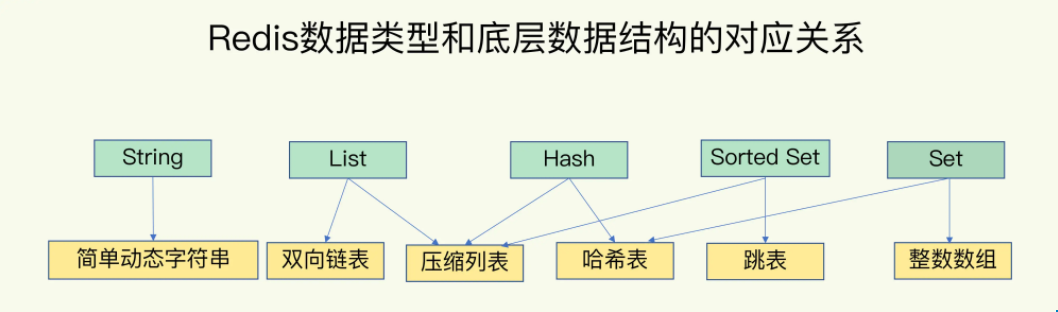
按照上图,我们总结几个问题来探讨
1.键与值是通过结构组织的?
对于键值的保存,Reids会使用哈希表来保存
而一个哈希表,其实就是一个数组,数组内的每一个元素都被称为哈希桶,每个哈希桶中都包含了键值对
对于上面的复杂数据结构,诸如 Hash和List,哈希桶中保存的则是数据指针,指向实际的数据
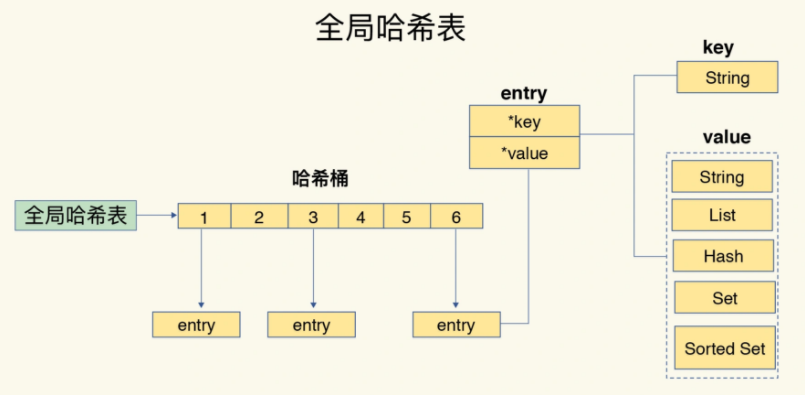
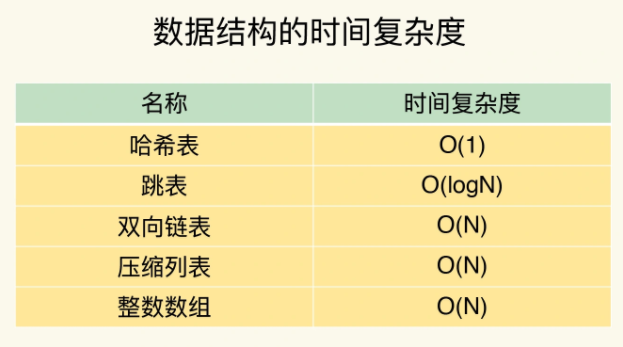
从数据结构来看,哈希表对于查询速度很快,基本为O(1),但是存在着哈希冲突问题
对于哈希冲突,Redis提供了rehash进行解决操作
哈希冲突,是因为多个key对应的hash值一致,导致Redis上的哈希桶上有多个键值对,形成了一个数据链
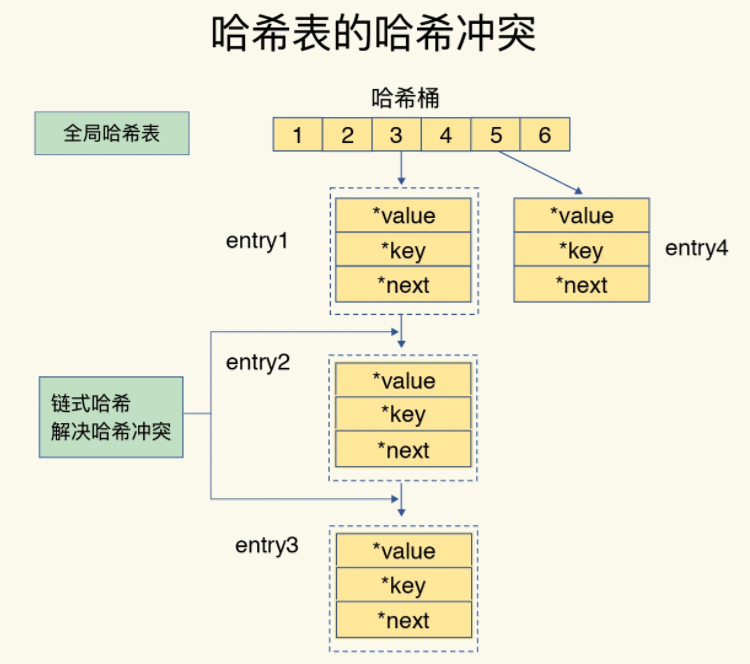
上面可以看出
在数据量越来越多的情况下,会导致链表越来越长,速度越来越慢
于是,Redis引入了rehash操作,rehash操作会增加现有的哈希桶数量,重新分配桶
在rehash的过程中,Redis会增加现有哈希桶
Reids默认使用了全局哈希表,分别是哈希表1和哈希表2,一开始默认使用哈希表1,哈希表2并没有分配空间,伴随着数据逐渐增加
Redis开始了rehash,分配创建了哈希表2
给hash表2分配了更大的空间
将hash表1中的哈希桶重新映射,分配到了哈希表2 中
而如果全拷贝的话,则有一个数据量过大线程阻塞的风险
于是Redis采用了渐进式 ,在第二步拷贝数据的时候,Redis仍能拷贝客户端请求,每处理一个请求,就将处理的哈希桶中的键值对重分配到第二个哈希表中
从而避免了大量的消息重哈希,带来的阻塞问题
根据上面说的哈希桶存储,String类型的存储,只需要找到哈希桶就能直接增删改查了,哈希桶O(1)的复杂度就是其复杂度
然后是其他的复杂数据结构
因为复杂的数据机构都是在哈希表中找到对应的哈希桶位置,然后根据哈希桶中的value指针找到数据位置,从而进行修改
复杂数据机构包含 整数数组 双向链表 哈希表 压缩列表 跳表
其中 整数数组和双向链表很常见 其特征都是顺序读写,根据数组下标或者链表指针来进行访问,操作复杂度都是O(N),效率较低
压缩列表,则是类似数组的数据结构,不过在表头上保存了一些额外的字段,比如 zlbytes,zltai,zllen,表示列表长度 列表尾部偏移量,entry的个数,在尾部还有zlend,表示列表结束

在部分数据位置的查找,相当高效,比如开头和结尾
对于跳表,则是一个好玩的数据结构
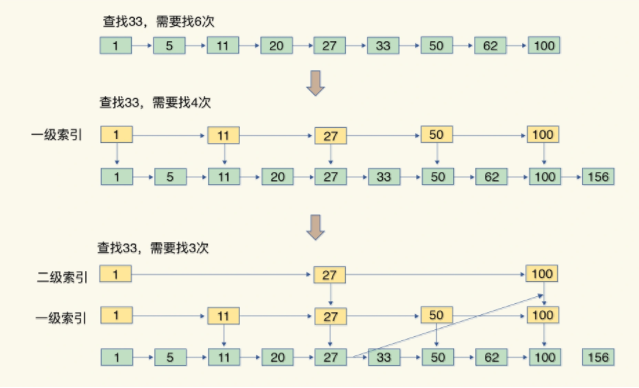
根据维护了多级索引,从而根据不同级别的索引,做二分查找法,从而快速的实现了数据定位
比如查找索引为33的数据,只需要二级列表找一次,一级列表找一次,数组上找一次就完成了查找,虽然复杂度为O(logN),但要求数据有序
对于上述的操作,继续查看集合元素的性能
如果单个元素的差好啊,比如Hash的HGET HSET HDEL 等,都是对Hash表作为操作,复杂度都是O(1)
但是对于范围操作,比如集合中的遍历操作,比较耗时,尽量避免比如LRANGE ZRANGE,复杂度都是O(N)
除此外,比如统计个数的操作,因为数据结构中都维护了个数统计,可以高效的完成操作
而且如果是压缩列表这样的记录了表头表尾偏移量的,查找头尾,以及在头尾增删元素,都可以通过偏移量直接定位,复杂度只有o(1),实现快速操作
本次我们说了Redis的底层数据结构,包含双向链表 压缩列表 整数数组 哈希表 跳表这几个数据而机构
我们需要掌握数据结构的基本原理,理解其不同的复杂度,并进行合理的选择
最后,整数数组为何会被Redis作为底层的数据结构呢?
毕竟整数数组在创建的时候,往往会在内存中分配一个连续的大空间,在进行遍历的时候,CPU可以将其大量读入CPU缓存,避免了内存地址多次查找映射