Redis是一个典型的键值数据库,但是其本身比较复杂,如果直接开始对着Redis进行学习,可能比较困难
所以我们先拿一个简单的键值对数据库对Redis建立一个系统观的认识,然后再深入到具体的技术点
我们将拿个这个简单的键值对数据库名为SimpleKV
对于这个简单的键值对数据库,我们首先需要考虑的是,里面可以存储什么样的数据,以及对数据可以进行什么样的操作,本质上就是数据结构和操作接口
对于数据模型,对其,我们可以考虑原本使用关系型数据库存储的数据如何使用键值数据库进行存储,比如用户信息,原本是用户Id 姓名 年龄 性别等,而在键值数据库一般一个用户ID对应一个用户信息集合,这就是键值数据库的数据模型
而且除了键值数据库中的数据结构,我们还需要了解其提供的操作接口,了解键值数据库如何对数据进行操作的,举个简单的例子,键值数据库是无法对多个用户的年龄进行avg操作,这就和数据结构有关
于是乎,想要学习Redis,就需要学习其数据结构和操作接口,而这次我们介绍的SimpleKV,可以看做就是Redis的简单介绍
对于键值对数据库而言,可以存储什么类型的数据是需要首先考虑的
基本的模型是key-value,比如 “k”:”v” k就是key, v就是value 前面的k:v 中的value,很简单就可以看出来,是一个String类型,但在Redis中,除了String类型,还支持了哈希表 列表 集合等,和Memcached只支持String形成了鲜明的对比
虽然Memcahched只支持了String类型,但是复杂的数据结构会带来性能和空间效率上的差异,对于不同的存储数据类型,需要我们了解其原理,在SimpleKV中,我们先只支持String类型
其次是对应的操作,SimpleKV也只考虑提供一些简单的数据操作,先考虑三种简单的操作,即PUT,GET和DELETE
上述的操作,类似Java中Map提供的API,PUT负责插入和更新一个key-value
GET负责获取KEY对应的value,DELETE复杂根据KEY删除Key-value
当然,有些数据库中将PUT改名叫做SET
然后除了上面的操作,有时候还需要判断某些用户是否存在,就是判断用户的ID是不是作为KEY了,这时候就可以增加EXISTS的操作接口,判断某个键值是否存在,以及查询一个用户一段时间内的访问记录,这种操作属于SCAN操作, PUT/GET/DELETE/SCAN 是一个键值对数据库的基本操作集合
说完了数据库的数据模型和操作接口,我们接下来需要考虑的是,键值对的数据,是保存在内存还是外存
如果保存在内存中,虽然速度很快,但是会存在一个数据丢失的风险,而保存在外存,受限于磁盘的慢速读写,整体的性能并不会很高
对于数据存放的位置,是考虑键值数据库的主要应用场景的,比如缓存场景下的数据需要能够快速访问,所以还是放在内存中,和Redis保持一致
接下来,就是考虑如何让程序和使用者交互,即采用什么访问模式
可以考虑使用传统的函数库的调用方式来让外部程序使用,比如libsimplekv.so 就是动态链接库的方式供外部调用
或者采用Socket通信的形式来对外提供键值对操作,这种形式可以提供更为广泛的键值对存储服务
以网络框架的方式提供键值对存储服务,可以扩大键值数据库的受用面,也给键值数据库的性能,运行模型提供了不同的设计选择
比如使用网络发送一个请求 PUT “A”:”B”
客户端收到了这个网络包之后,根据相关协议进行解析之后,进行写入流程,直到写入完成
上述的流程在面临网络并发的情况之后,需要考虑,网络连接的处理,请求的解析,数据的存储处理,是使用一个线程还是多个线程呢?单个线程面临并发压力,多个线程面临着网络并发带来的资源竞争
Redis采用的是网络交互,于是设计了一套网络交互多线程,执行单线程的操作,我们将照着Redis进行模仿书写
那么我们就确定了数据结构 – 基本操作接口 – 数据存放位置,那么整体的内部架构如下
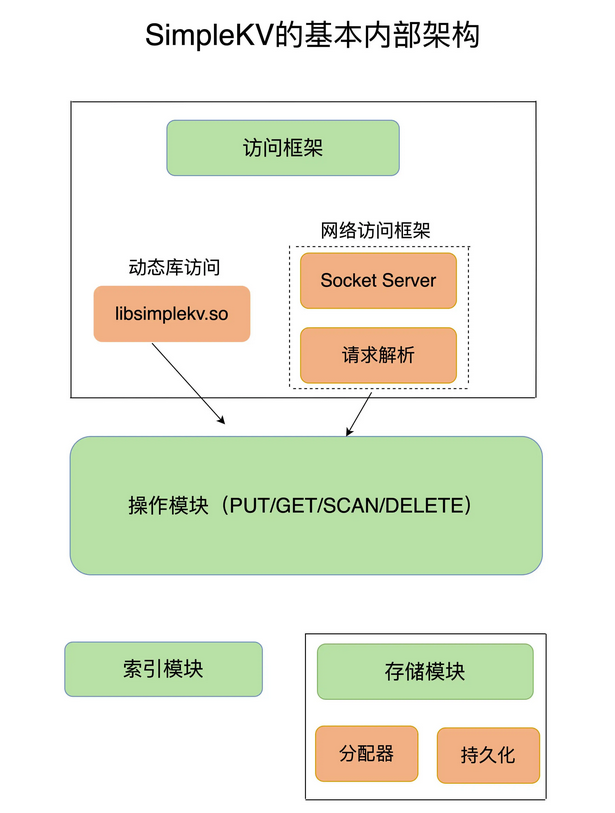
在上图中,还有这索引模块和存储模块两大模块我们还没有说明
索引模块,是为了让SimpleKV在收到客户请求之后,来查找请求的键,从而执行操作
索引的类型有很多,常见有哈希表 B+树 字典树等,不同的索引在性能 空间消耗 并发控制的方面不同控制
Redis采用的就是哈希表,而RocksDB采用的跳表作为内存中的索引
SimpleKV则一致选择哈希表作为索引数据结构,毕竟对于内存的高性能随机访问,哈希表很能将其表现出来
不过SimpleKV只需要找到Key对应的Value,而在Redis中,可能还需要根据value的不同数据结构,进一步找到需要的数据
然后在存储模块中分为分配器和持久化
常见的可以使用UNIX提供的glibc的malloc和free,作为内存分配的方式,但是glibc分配器在处理随机的大小内存块分配时候表现并不好,而且容易产生内存块碎片的问题
但是API相对简单
持久化,则是有着不同的落盘机制,比如对于每一个操作,都进行落盘保存,这样数据很可靠,但是性能必然有一定的影响
或者是将数据周期的进行落盘保存,这样就存在一个数据丢失的风险
对于持久化,Redis则进行诸多的机制和优化改进,也是接下来主要讲解的内容
今天的内容,我们设计了简化版的Redis,对于其和Redis的实际对比,
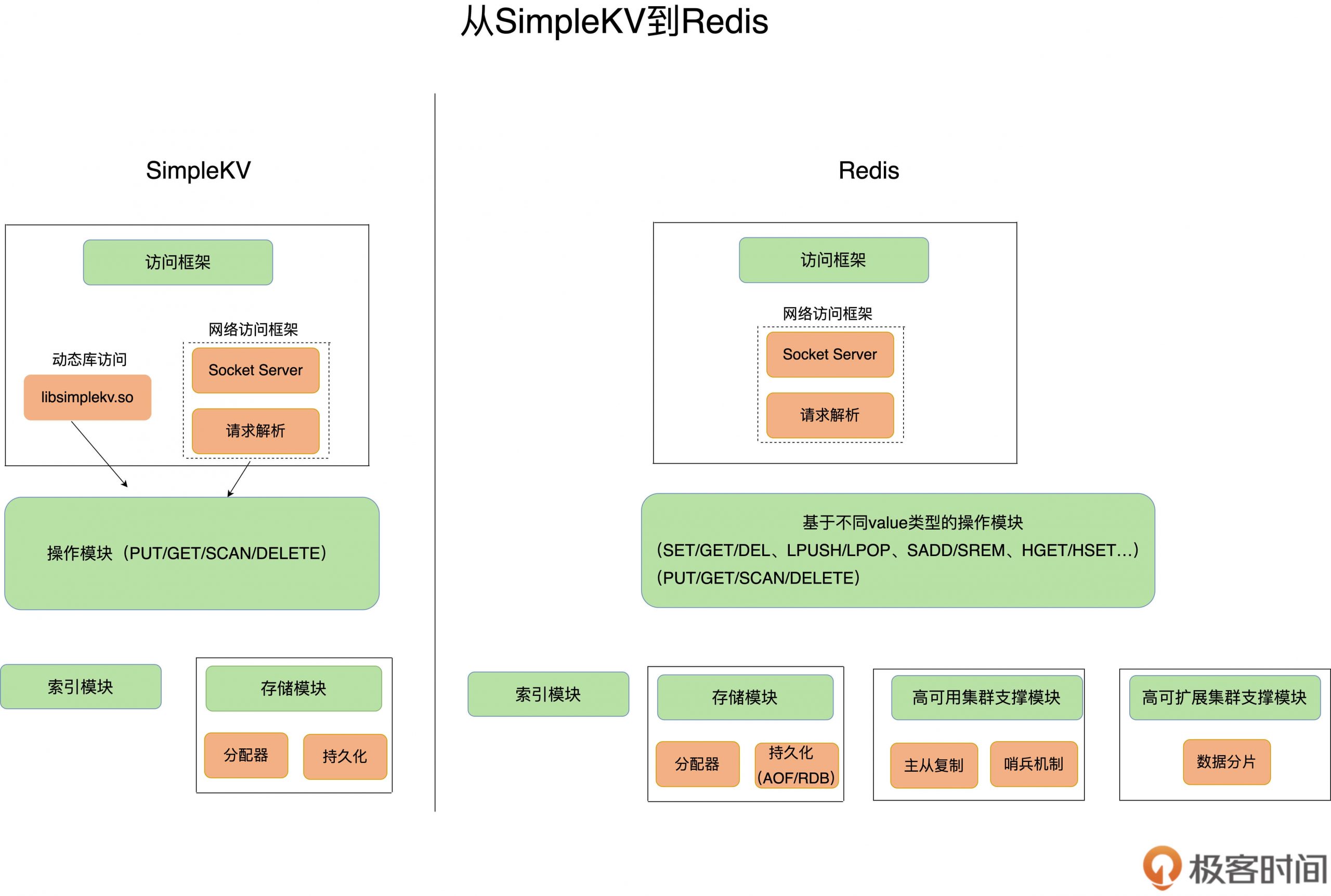
上面可以看出来,Redis有了更多的操作模块
数据结构也更加复杂
还支持了高可用集群支撑模块
最后,可以探讨一下SimpleKV和Reids相比,还差些什么
如果把SimpleKV看做一个单机版的,只支持动态库访问的键值对数据库,那么SimpleKV还缺少事务机制
其次补充一下为何glibc会产生内存碎片
因为我们使用高级编程语言来分配内存,比如malloc(),是利用glibc库作为中间媒介和底层系统通信,(以把glibc库看做一个接口,具体的实现不需要上层调用者关心)
在内存分配中,glibc根据内存分配策略,来选择mmap()/brk()两个函数中的任意一个,而可能导致内存碎片的就是brk(
因为brk是通过移动堆顶位置来分配内存的,所以内存释放后并不会立刻归还系统,而是缓存起来,重复使用,在系统繁忙的时候,可能会造成内存碎片