对于Redis的常见使用场景,就是在后端数据库之上,做一层缓存,避免直接访问给数据库带来的压力
但是Reids如果出现宕机等问题,内存中的数据丢失后,如何进行恢复?如果是直接从后端数据库再次读取,这样对数据库会造成不小的压力
所以Redis也支持直接从备份文件进行恢复,其数据持久化的方式主要有 AOF和RDB两种
我们首先说的是AOF机制
往常,在常见的结构化数据库中,进行日志备份的redolog 是利用的数据写入之前进行备份,从而方便故障的时候进行恢复,不过Reids相反,而是后置的日志
在写入数据之后,才进行记录日志
那么AOF这样做的理由在于什么呢?
一般来说,如果执行之前记录日志的话,那么需要确保此命令能够执行成功,如果放在Redis,就需要提前校验命令正确性,这就带来了额外的性能消耗
于是进行了后置日志的保存
而在,ReidsAOF中保存的日志格式,一般是进行了拆分后的
比如输入一个set testkey testValue
那么在AOF保存的日志,命令会有四个部分,第一部分是一个*3说明,有三个字段
然后每个字段前面加了$+数字 开头
数字是说明有多少个字节,上面命令在AOF中保存为

而且,在命令执行后记录日志,不会阻塞当前的写操作
不过AOF也因此带来的风险
如果AOF执行完成命令,没有记录日志就宕机了,那么就会有丢失的风险
而且AOF因为写入日志是在主进程中进行的,如果日志文件写入磁盘的时候,磁盘写的压力大,会导致磁盘写入慢,后续操作无法执行
于是AOF机制给我提供了不同配置的刷新选项
比如Always,同步写,每个命令执行完成,就立刻将其写入磁盘
Everysec,只会写入到缓冲区,然后每隔一秒将其写入磁盘
NO,只写入缓冲区,等待系统自己刷新
上面不同的写入时机,各有优缺点,总结如下
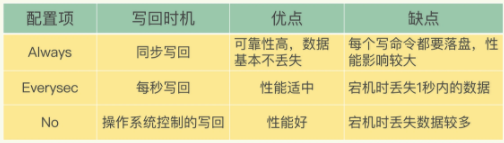
我们根据系统对高性能和高可靠性的要求,选择不同的写回策略,如果需要高性能,就选择No,如果高可靠,就Always,如果可以接受部分数据 丢失,就选择EverySec
解决了这个问题,还需要考虑,AOF是以文件的形式来记录命令,那么AOF文件会伴随着Redis命令执行,越来越大,文件大带来的性能降低问题,使我们需要考虑的,这就带来了AOF重写机制
简单来说,就是AOF文件达到一定程度,进行重写,读写数据库中所有的键值对,然后进行记录写入
比如读取键值对 testkey : testvalue 之后,重写机制会记录 set testkey testvalue
而且在写入的时候,是利用了内存,将旧日志文件中多条数据变为一条
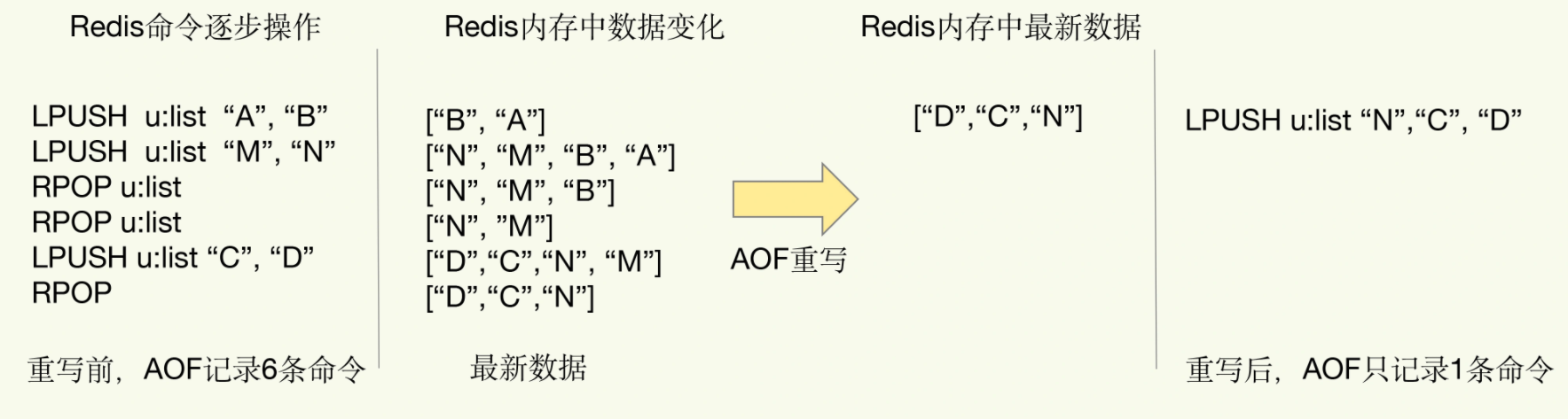
将 u: list最后数据录入为 N C D
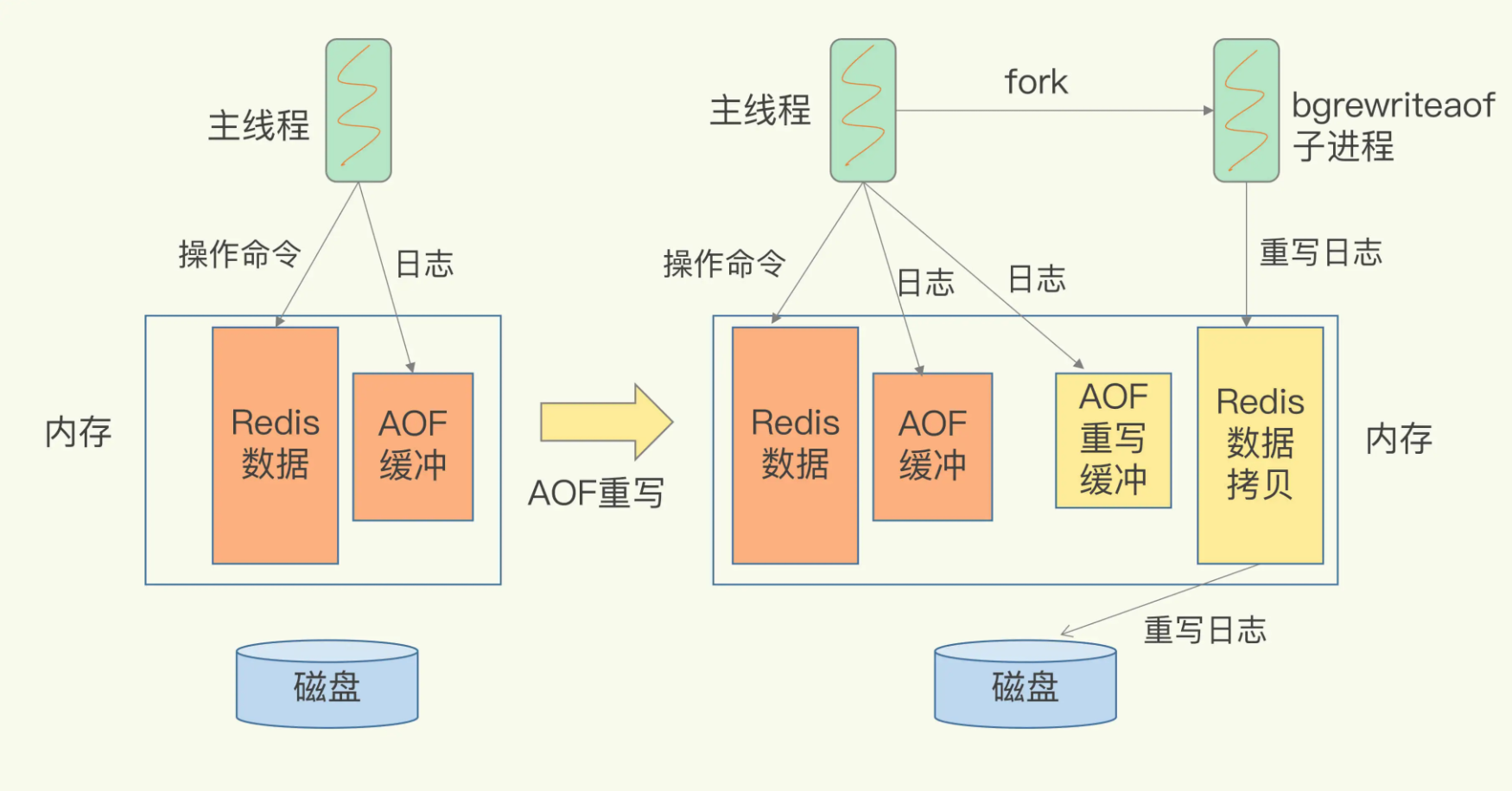
将之前的记录进行压缩,而且重写是一个额外的子进程完成的,可以避免阻塞主进程
在这个重写的过程中,需要将主进程 fork 出一个子进程给子进程,而且将内存拷贝一份
然后子进程将数据转换录入日志
对应的,在执行过程中,主进程在执行操作的时候,会同时将日志转发到自己和子进程中,写入两方的日志,避免重写过程中因为宕机导致的数据丢失,写入完成了,就可以使用新的AOF代替旧的AOF了
那么我们总结一下AOF相关知识
AOF是Redis避免数据丢失的方法,其提供了三种写回策略,分别是Always,Everysec和No
而且,为了避免日志过大,还提供了AOF重写机制
在此过程中,AOF写回策略体现了trade-off ,在不同的方面做取舍
那么,我们提一个问题
AOF重写的时候,是交由子进程完成的,有没有什么外的风险
其次AOF重写的时候有一个重写日志,为何不共享AOF本身日志
回答这个问题,我们得看下Unix中的父子进程的拷贝
在父进程调用fork之后,
Unix会进行以父进程为模板创建子进程
然后拷贝虚拟内存中的地址(虚拟内存和物理内存有一个映射关系,这是因为Unix维护了一个大一统的内存系统,将上层对内存的操作和实际的内存解耦)
然后fork分别返回,父进程获取到子进程的pid
上述流程,之所以只拷贝虚拟内存,是因为Unix采用了写时复制(早期Unix是深拷贝)
而AOF不涉及操作内存,故不会拷贝物理内存
但是由于Unix中,可能出现进程数不足,以及虚拟内存表拷贝失败等问题,到来的AOF重写失败的风险
还有就是在学习课程之前,我曾经猜测过AOF的重写机制,早期我给出的答案是模仿MQ的日志文件,只是操作日志,即依次读取日志,根据key来判断key最终是否需要写入到日志中,到了重写流程完成之后,才进行一个强制写盘的操作,现在看来,我还是对Unix系统玩的浅啊