我们介绍了很多性能的测试工具,但是在实际的性能分析中,一个常见的问题,就是等登录到服务器中进行排查的时候,瓶颈却消失了
面对这种情景,我们介绍的各种方法都失效了,也不能不管,毕竟涉及到了用户的体验
这种情况下,就需要搭建监控系统,将系统和应用程序的运行状态监控起来
在发生问题的时候,第一时间通知
那么系统,可以分为系统和应用两个方面
从系统的层面来看,监控系统要涵盖整体资源使用,包括CPU 内存 磁盘 和文件系统 网络等资源
应用程序,需要涵盖程序内部的运行状况,包括进程CPU 磁盘IO 等运行情况,包含接口的调用耗时,执行过程中的错误,链路跟踪
首先是系统级别的监控
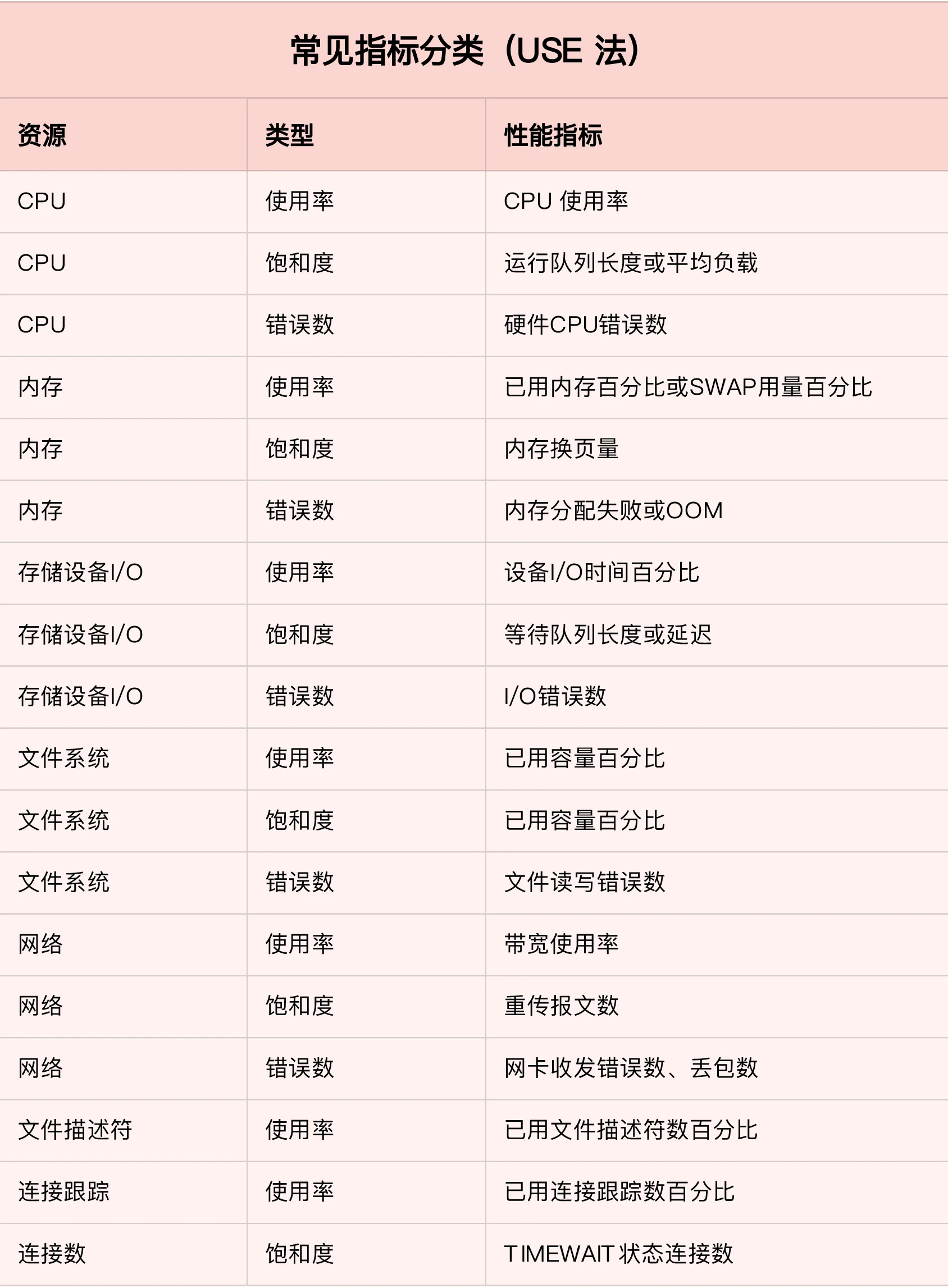
1.在系统级别的监控,有两种监控的衡量方式,一种是USE法,一种是RED法
这里主要用USE法,包含使用率,饱和度/错误数
上面的三个类别的指标,涵盖了系统资源的常用性能瓶颈,常用于快速定位系统资源瓶颈
包含但不限于 CPU 内存 磁盘和 文件系统 网络等硬件,文件描述符 连接数 链接跟踪数等软件资源
整理如下
对应的监控方法是接下来需要关心的
我们需要建立一个监控系统,来保存指标,然后根据状态,来分析和定位大致的瓶颈来源,最后通过告警,将问题汇总汇报
分为了数据采集 数据存储 数据查询 告警及可视化等模块
常见的开源的监控工具有 Zabbix Nagios Prometheus
比如Prometheus
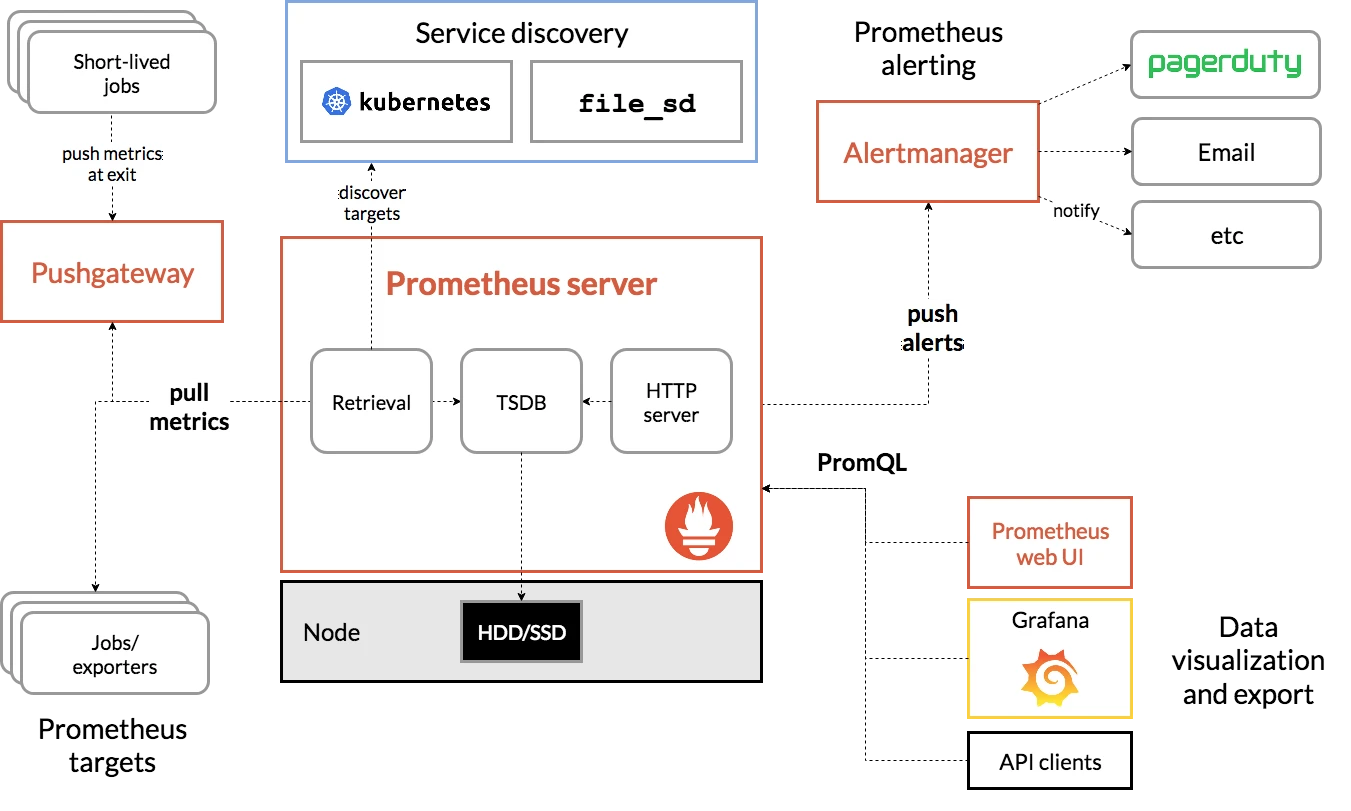
对于数据采集,分为了Push和Pull两种采集模式
Pull模式,服务器端的采集模块进行轮询采集,需要目标提供采集的HTTP接口
Push模式,各个采集目标主动向GateWay推送
然后是数据存储在一个TSDB模块,将数据持久化到SSD等磁盘中,一种专门为时序数据设计的数据库,以时间为维度,方便查询
查询模块,则是利用TSDB进行相关的查询,也是告警和可视化的基础
告警模块,通过告警规则来判断是否符合告警规则
最后是可视化界面,利用TSDB进行查询,然后配合一些可视化组件,诸如Grafana,进行可视化
2.这就基本总结了系统监控的大概思路,然后是应用程序相关的监控,往往来说,应用程序的监控也是必不可少的
对于应用程序相关的监控,并不能粗暴的分为使用率 错误数等,我们需要考虑应用程序的响应速度
应用程序的核心指标,不再是资源的适用,而是请求数 错误率 响应时间这些程序相关的指标
除上面的指标外,还应该有 应用程序的资源使用情况(诸如CPU 内存 磁盘IO等),应用程序之间的调用(彼此依赖的应用程序耗时),应用程序内部的核心逻辑运行情况(将关键环节的耗时 执行过程的错误进行暴露出来)
在之前建立的Prmetheus中,纳入这些监控指标,方便进行统计
对于其中的调用链的统计,可以考虑使用ZipKin Jaeger Pinpoint等开源工具,构建全链路跟踪系统
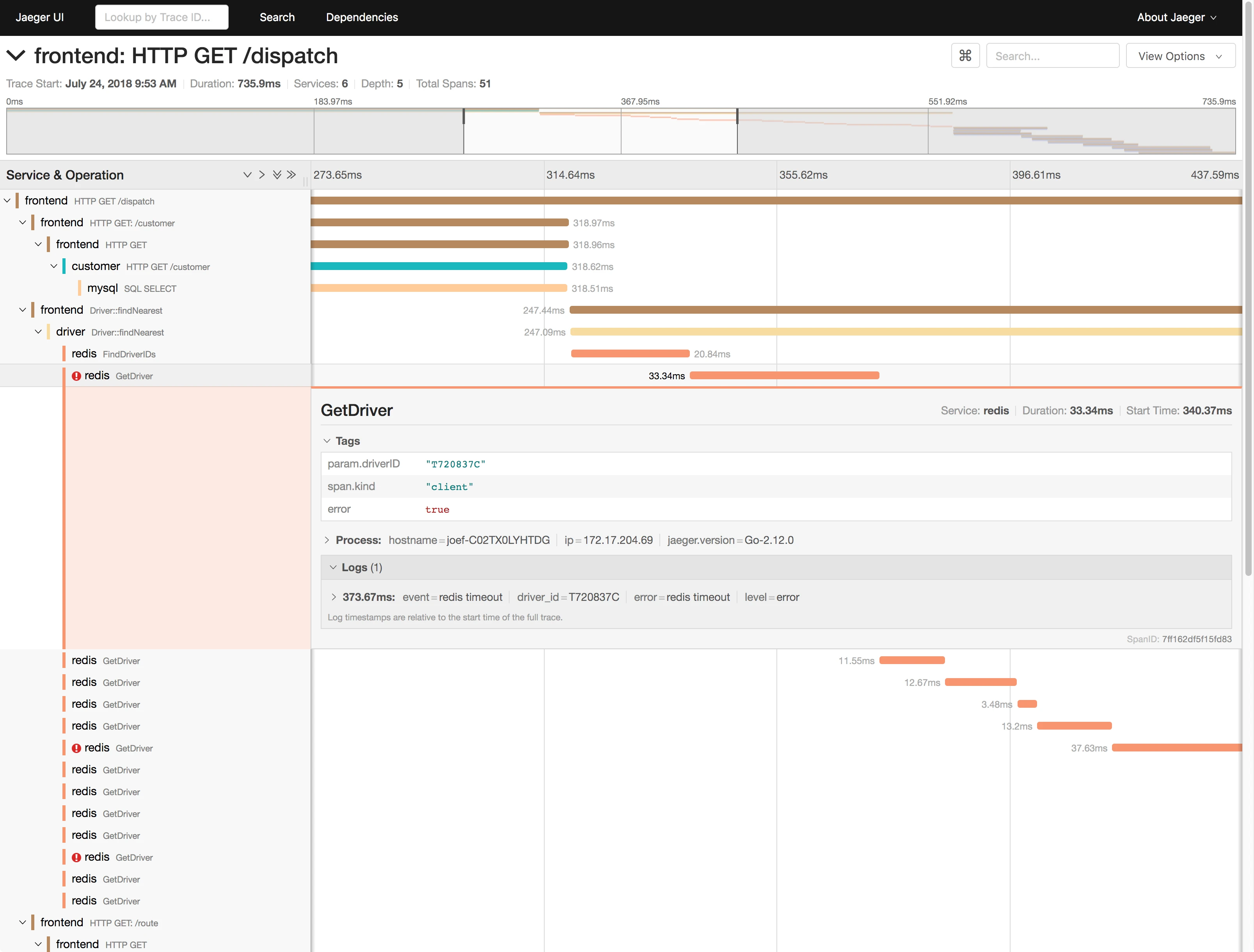
常见的Jaegar如下
上面可以清楚地看出,是Redis超时导致的
除了链路追踪之外,还有着日志监控,日志中的监控,可以迅速的定位发生瓶颈的位置,对于异常问题,可以利用上下文进行监控,日志正是这些上下文的最佳来源
对比来看,
指标是特定时间段的数值监控数据,负责实时监控
日志则是某个时间点的字符串信息,需要利用搜索引擎搜索后,才能进行查询
日志常用的套件就是ELK技术栈,分别使用Elasticsearch Logstash Kibana进行组合
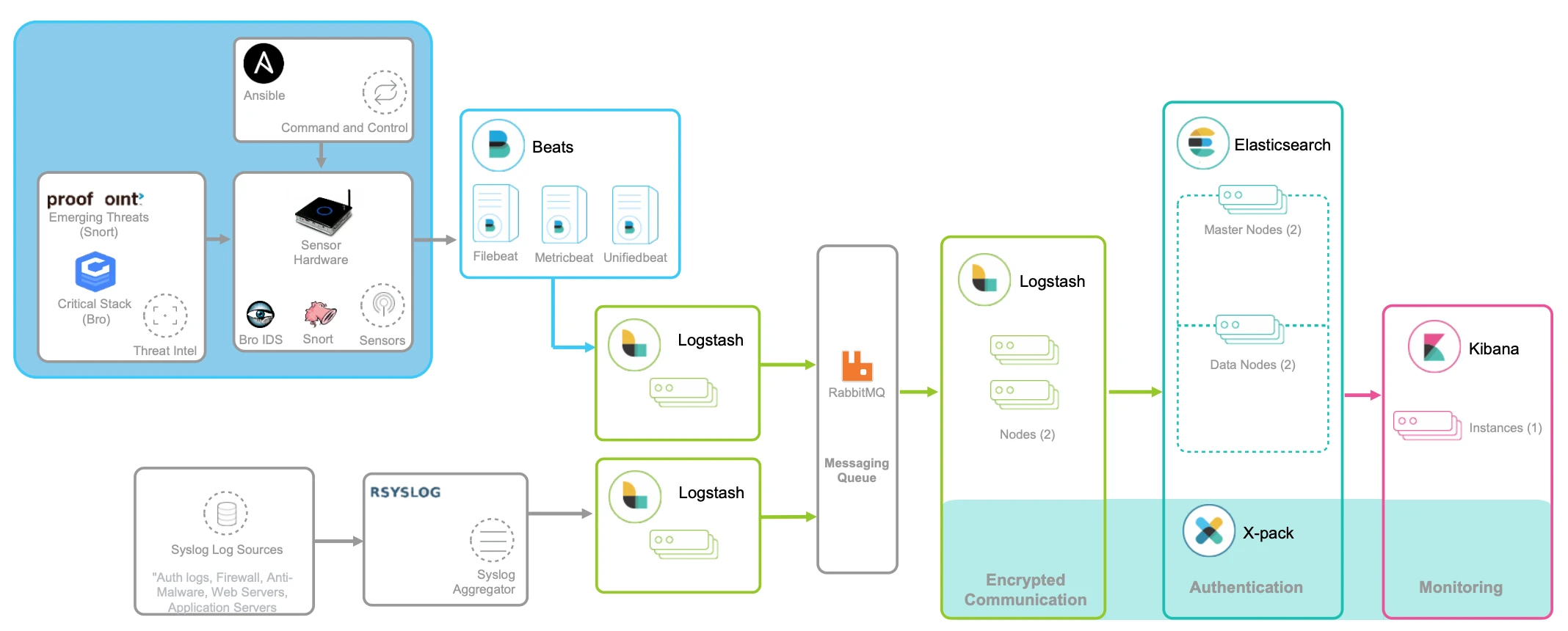
Logstash负责采集日志,然后进行预处理
Elasticsearch负责对日志进行索引,并提供一个完整的搜索引擎,方便进行检索
Kibana负责可视化的展示,包括日志搜索,处理等
ELK的技术栈的Logstash消耗比较大,资源紧张的时候,可以考虑使用资源消耗更低的Fluentd,代替Logstash
那么总结一下,对于应用程序的监控,可以分为指标监控和日志监控
指标监控主要是对一定时间段内的性能指标进行测量,通过时间排序进行存储告警
日志监控则是提供更为详细的上下文,通过ELK技术栈进行收集,索引 图形化展示
除此外,还可以构建全链路跟踪系统,方便动态的跟踪调用各个组件的性能