我们将应用程序的监控,分为了指标监控和日志监控两个大块
指标监控,主要是对一定时间段的性能指标进行测量,然后通过时间序列,进行告警,查询
日志监控,则是提供更加详细上下文信息,进行图形化展示
跨不同应用的复杂业务中,可以构建全链路跟踪系统,就可以动态的跟踪各个组件的性能,生成整个应用的调用拓补图,加快定位复杂为题的能力
说完了上面的监控,我们今天说一下性能分析的常见思路
还是将其分为了系统资源和应用程序
而系统资源之中,可以使用USE法,使用使用率 饱和度 错误率进行衡量,内部分为了硬件资源和软件资源
硬件有CPU 内存 磁盘和文件系统 网络等
软件有 文件描述符数 链接跟踪数 套接字缓冲区大小,则是典型的软件资源
首先是CPU的性能分析
整体的一张图如下
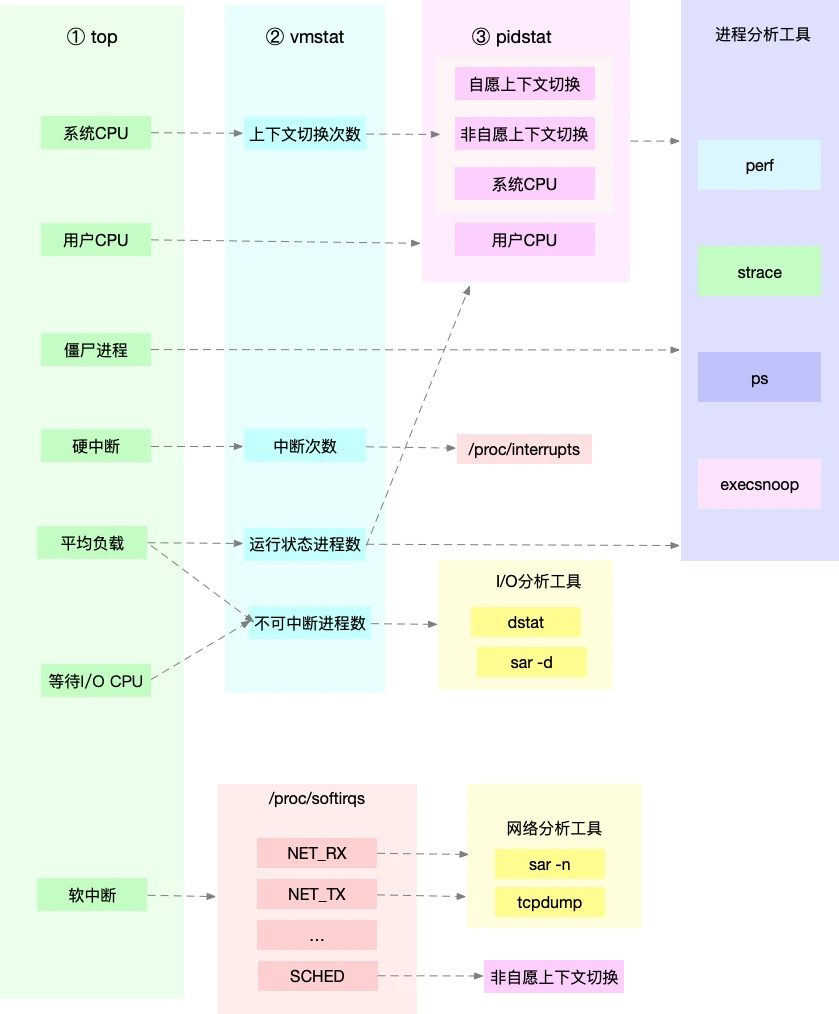
实际上,top pidstat vmstat这类的工具汇报的CPU性能指标,源自/proc文件系统
我们可以直接监控/proc文件系统,以及分别查看系统级别的CPU过高和进程级别的CPU过高
然后是内存分析,对于内存分析,首先定位整体内存瓶颈,然后进行进程级别的内存使用 分配 泄露,找出问题根源
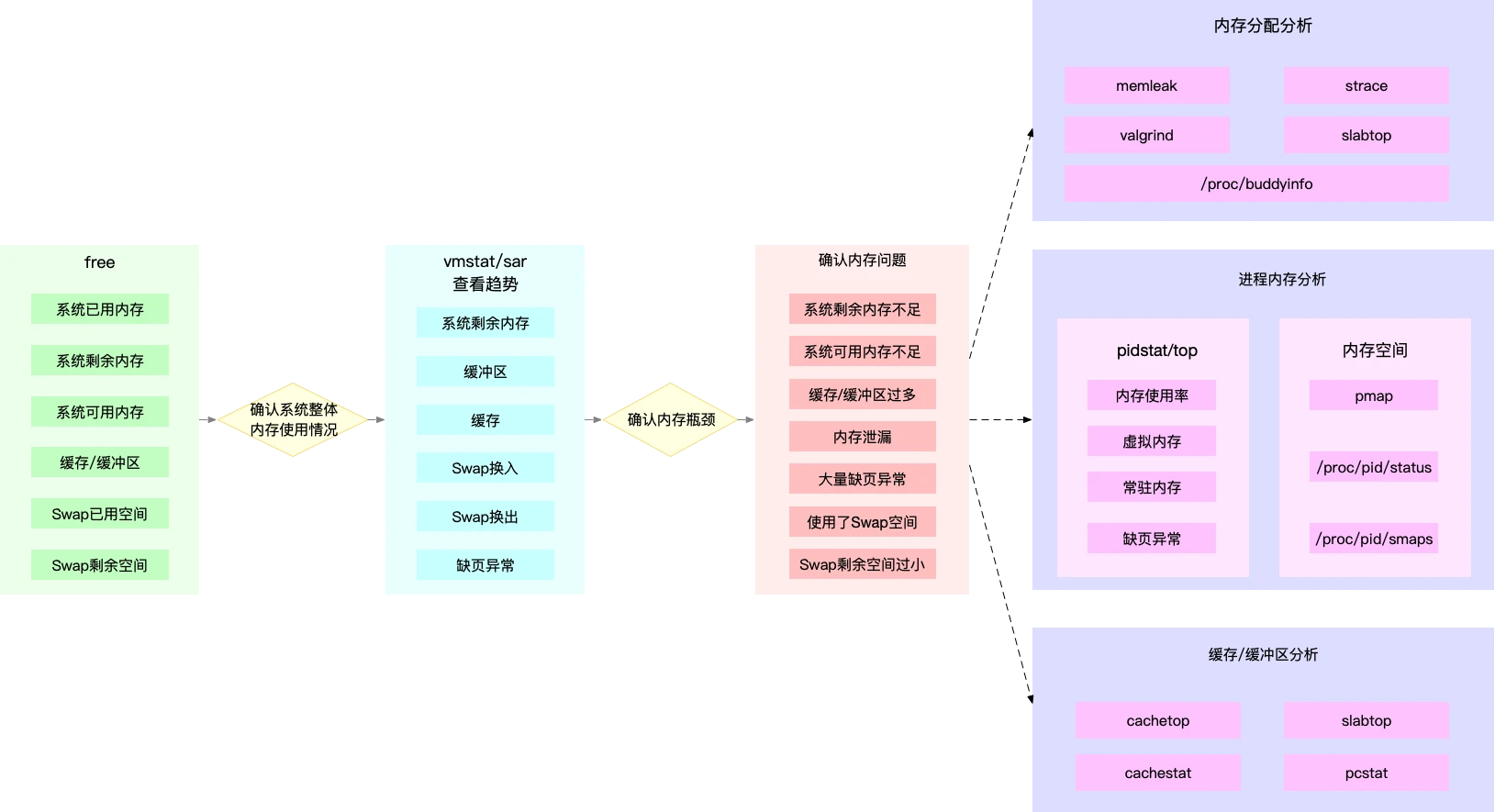
如同CPU性能一样,很多内存的性能指标,都来源于/proc文件系统 /proc/meminfo /proc/slabinfo进行监控告警,加快问题定位
接下来,就是磁盘和文件系统的IO性能分析
关于磁盘和文件系统的IO性能分析,之前也有说过
可以先使用iostat查询磁盘IO的性能瓶颈,然后通过pidstat vmstat确认IO来源
根据来源的不同,进一步的分析文件系统和磁盘的使用率,缓存以及进程IO等
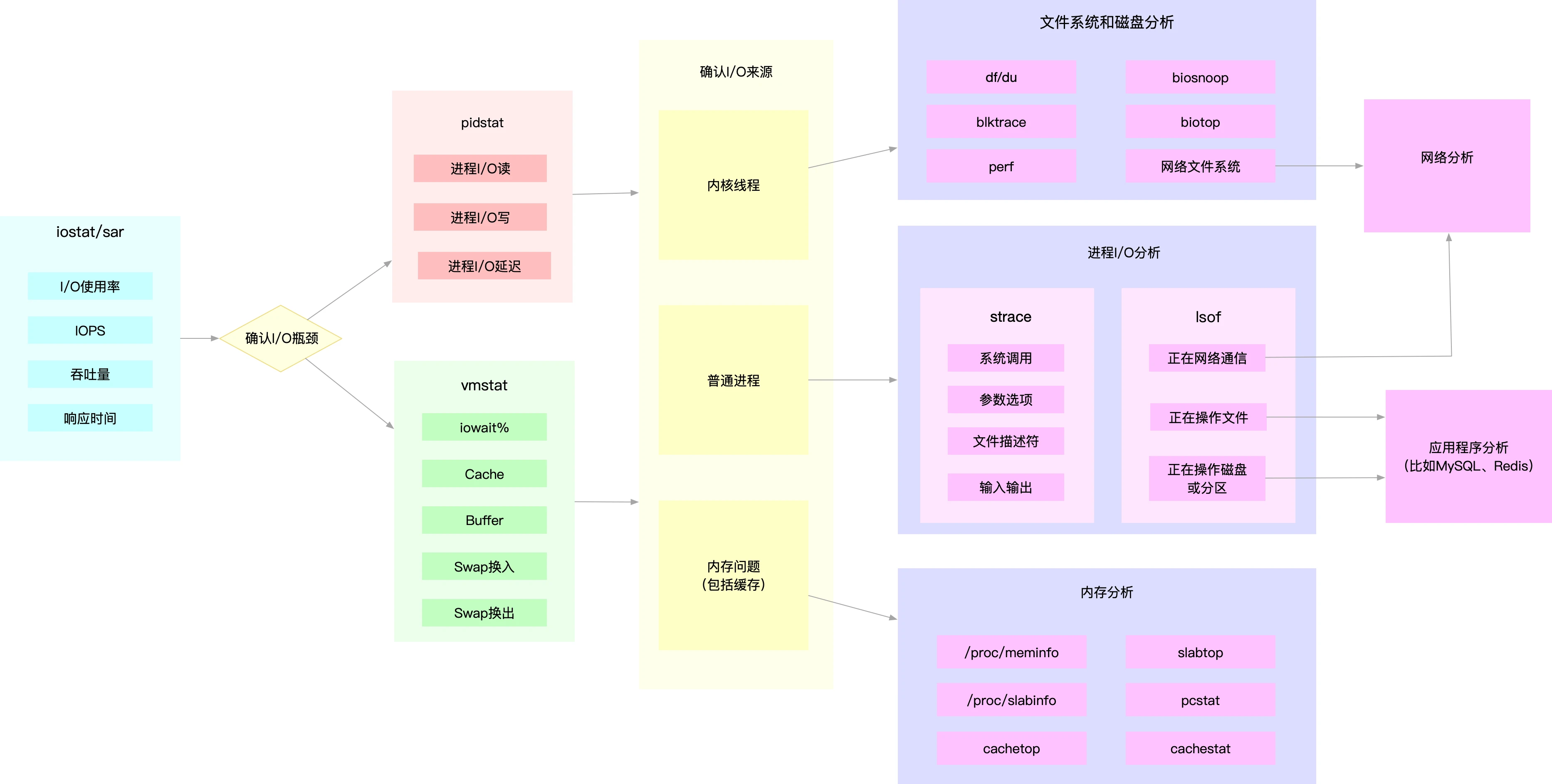
同CPU和内存性能类似,很多磁盘和文件系统的来源都是/proc /sys文件系统
同样可以进行监控,然后进行判断,首先从监控系统中,找到IO最多的进程,然后分析进程的IO行为
网络性能分析
最后的网络性能,包含两类资源,分别是网络接口和内核资源,网络性能的分析,从Linux网络协议栈的原理来切入,下面的图,就是Linux网络协议栈的基本原理,包括应用层,套接字接口,传输层
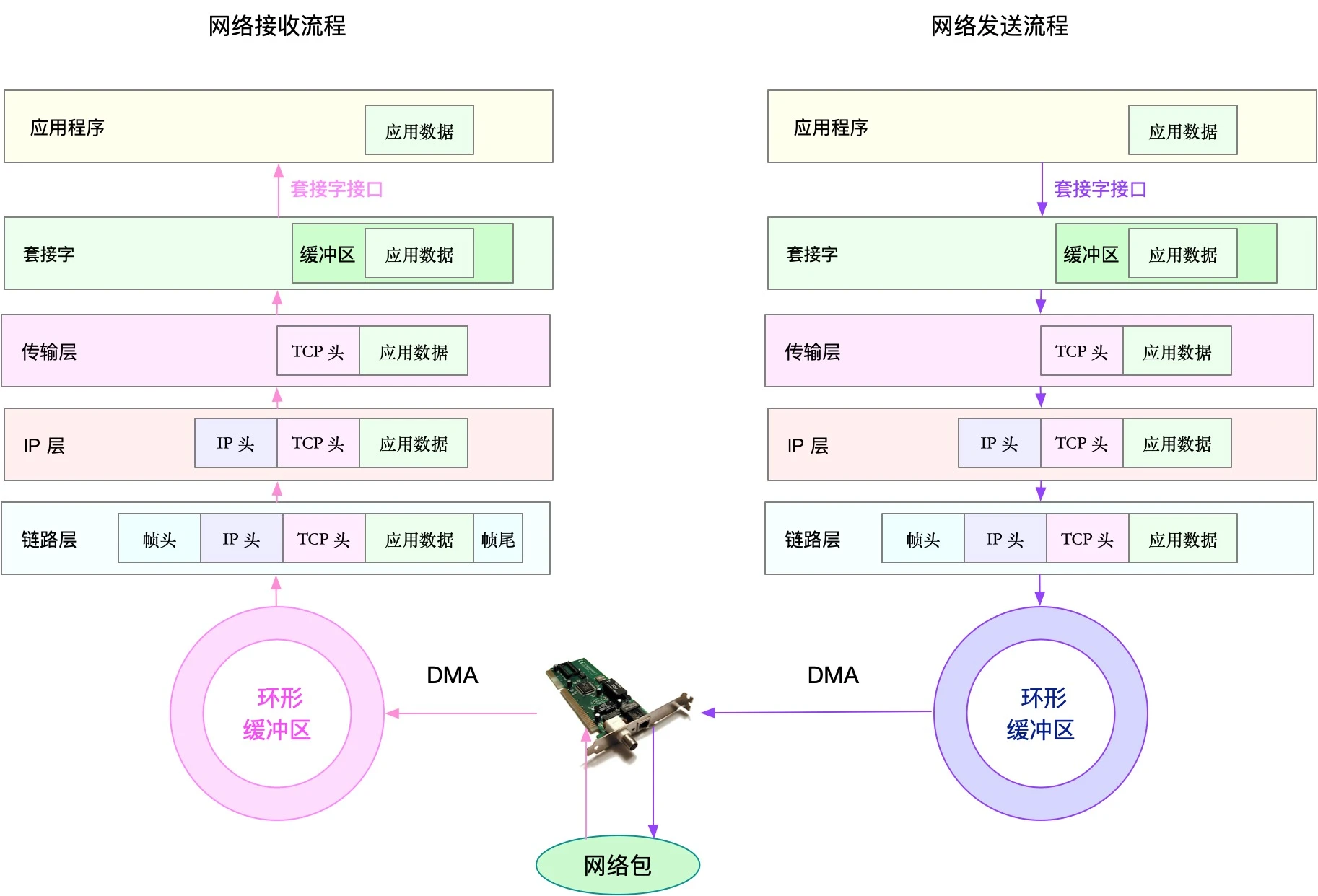
链路层,可以从网络接口的吞吐量 丢包 错误 以及软中断和网络功能卸载进行分析
网络层 从路由 分片 叠加网络等角度分析
传输层,从TCP UDP等原理出发,从连接数 吞吐量 延迟 重传等角度分析
应用层,从应用层协议 请求数 套接字缓存等角度分析
网络的性能指标来源于内核,包括/proc文件系统 网络接口以及conntrack内核模块,也需要被监控,这样,当收到网络告警的时候,可以更快的定位出问题
当收到网络不同的告警的时候,可以查找各个层次的丢包指标,确认所在协议层,确认网络带宽 缓冲区 跟踪数等软硬件,然后分析网络的收发数据,确认问题
说完了系统资源,说一下应用程序的相关瓶颈
对于应用程序的瓶颈,评判标准可以有吞吐量 下降 错误率升高和响应时间增大
对于出现的问题,可以分为资源瓶颈 依赖服务瓶颈 应用自身瓶颈
第一种资源瓶颈,指的是提到CPU 内存 磁盘和文件系统IO 网络以及内核资源软硬件进行了瓶颈,从而导致的应用程序受限
第二种,依赖服务瓶颈,诸如数据库 分布式缓存 中间件等应用程序,直接或者间接的服务出现了性能问题,导致的应用程序响应变慢,错误率升高,说白了就是跨应用的性能问题,使用全链路系统,可以定位这个根源
第三种,应用程序自身的性能问题,包括多线程处理不当,死锁,业务算法复杂度等,这需要我们暴露出对应的日志,方便查看
出现报警之后,利用这些手段查找出瓶颈,可以利用系统资源模块来进行分析定位,比如
strace,观察系统调用
使用perf和火焰图 分析热点函数
使用动态跟踪,分析进程状态
最后总结一下,
系统资源和应用程序是密不可分的,很多资源瓶颈,是由程序自身运行导致的,进程的内存泄露,会导致内存不足,进程过多的IO,拖慢系统整体IO请求