我们来说下共识算法的Raft算法
Raft算法属于Multi-Paxos算法,其中的特性有日志必须是连续的,只支持领导者 跟随者 候选人 三种状态,理解和算法上实现相对容易的多
Raft算法是现在分布式系统开发的首选共识算法,这个算法,可以帮助你去得心应手的处理大部分的容错和一致性需求
而Raft的本质,就是一切以领导者为准,实现一系列值的共识和各个节点日志的一致性
那么问题就很简单看出了,即领导者选举,日志复制,成员变更为核心,讲解Raft算法的原理
我们先来看一个简单的场景示例
假设我们有一个有A B C组成的Raft集群,那么如何去选举这个集群之中的领导者呢?
成员身份,又是服务器节点状态,Raft支持领导者 跟随者 候选者三种状态,任何时候,任何一个节点都是处于这三个状态中的一个

跟随者,就是普通群众,默默的接受着领导者的消息,等待领导者的心跳信息,如果超时了,就自我推荐为候选人
候选人,候选人对其他节点发送请求投票RPC消息,通知其他节点来进行投票,赢的多数投票后,就升为领导者
领导者,负责处理写请求,并且将自己的日志复制给跟随者,然后发送心跳消息
这里面只需要保证只能有一个Raft领导者模型就行了
那么是怎么选举的呢?
首先在初始的状态下,集群中所有的节点都是跟随者的状态
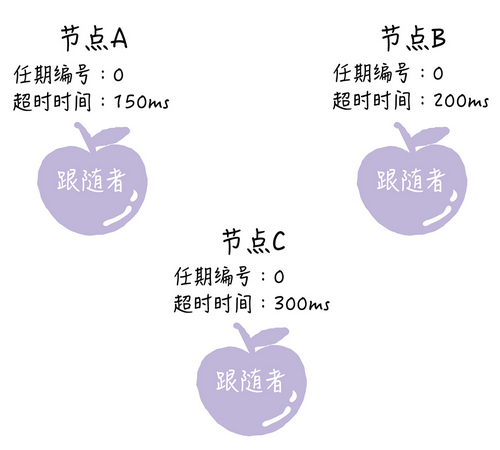
Raft算法利用随机的超时时间的机制,让每个节点都等待领导者节点的心跳信息的超时是随机的,集群中没有领导者,节点A的等待超时时间最小150ms,所以A会先超时,触发选举
这个时候A 会先增加自己的任期编号,然后推举自己为候选人,给自己投上一张票,然后发动投票请求
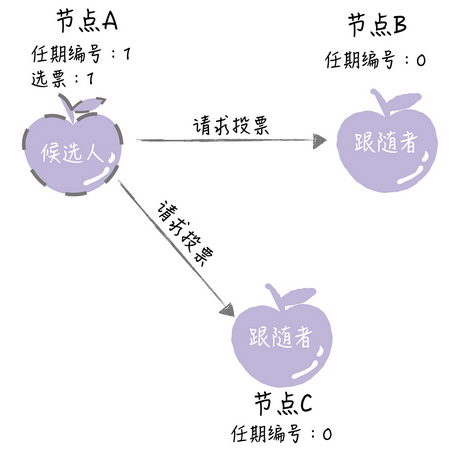
如果其他的节点收到了A节点的候选人投票请求的时候,在编号1的这届任期,还没有投过票,于是将自己的票给A,然后增加任期编号
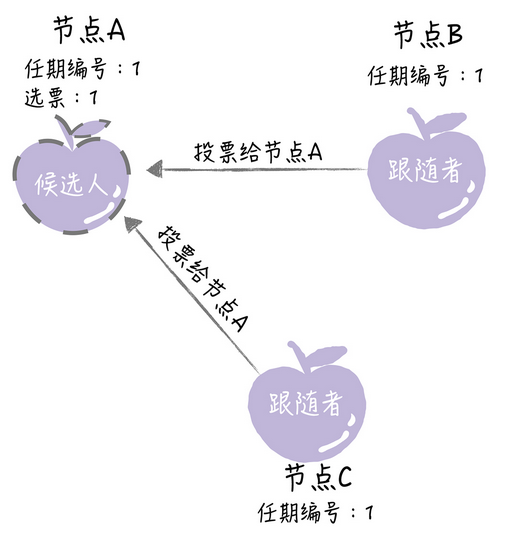
这样节点A就在选举时间内获得了大多数的选票,成为领导者了
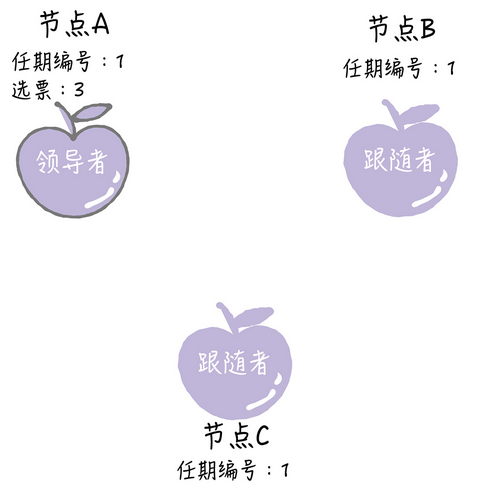
当节点A当选领导者的时候,周期性的发送心跳消息,通知其他服务器
那么接下来选举完成了,我们需要看一些细节,
节点之间如何通信的呢?
什么是任期呢?
选举有什么规则呢?
随机超时时间是什么呢?
我们一个个看这些细节问题
1.在Raft算法中,服务器节点之间的沟通联络用的是远程过程调用RPC,常见的RPC分为两类,请求投票RPC 选举期间发起的,通知各个节点进行投票
日志复制RPC,复制日志和进行心跳请求
2.任期,任期是领导者的负责时间,一般不会任期超时,只有不称职,就是离线的时候,让任期由单调递增的数字进行标识的,比如节点A的任期编号为1,任期编号是随着选举的进行而变化的
每个任期的标识数字是单调递增的数字标识的
跟随者在等待领导者心跳信息超时后,推举自己为候选人,会增加自己的任期号,比如节点A的任期编号为0,推举自己为候选者时候,会将自己的任期编号增加为1
如果一个服务器节点,发现自己的任期编号比其他的节点小,会更新自己的编号为较大的编号,比如节点B的任期编号是0,发现有个来自A的请求投票的RPC消息时候,消息中包含了节点A的任期编号,编号为1,那么节点B会将自己的任期编号更新为1
Raft算法中还约定好了,如果一个候选人或者领导者,发现自己的任期编号比其他的节点小,比如任期编号为3的候选人,发现收到了新领导的B,任期编号为4的心跳请求,就会重新将自己恢复为跟随者状态
还约定了,如果一个节点收到了一个包含较小任期编号值的请求,会直接拒绝这个请求,节点C的任期编号为4,收到了一个任期编号为3的投票请求,直接拒绝
3.选举的规则
(1) 领导者周期性的向所有跟随者发送心跳消息,通知大家我是领导者,组织跟随者发起新的心跳请求
(2)如果指定的时间内,没有收到来自领导者的消息,就认为当前没有领导者,推举自己为候选人,发起领导人选举
(3)一次选举中,赢得大多数选票的候选人,升为领导者
(4)一个任期内,直到发生,宕机,网络延迟没有发出心跳之前,都是会是领导者
(5)每一个服务器节点会对一个任期编号投出一个选票,并且按照先来先服务的原则,比如节点C的任期编号为3,收到了一个包含任期编号为4的投票请求,那么会将票给出去,然后又收到一个包含任期编号为4的投票请求,那么因为没有选票可以投了,故放弃投票
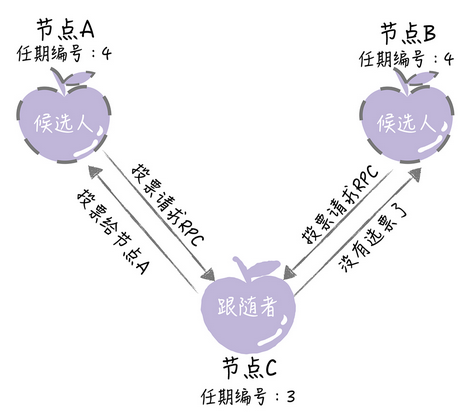
(6)日志完整读高的跟随者,拒绝投票给日志完整度低的候选人,比如节点B的任期编号为3,节点C的任期编号为4,但是节点B的最后一条日志 对应的编号为3,节点C是2,那么节点C请求节点B投票给自己,节点B拒绝投票

这样的条件保证下,可以保证集群成员半数以上投出来的节点,一定是比较新的,且只会投出来一个节点
4.因为同时发起选举,可能导致选举的票被瓜分了,从而选举失败,于是使用了随机超时时间的机制
Raft算法巧妙的使用了随机选举超时的方法,将超时时间进行了分散,大多数的情况下只有一个服务器节点先发起选举,而不是同时发起选举,从而减少因为同时选举而选票瓜分的情况
这个随机时间体现在两处
1.跟随者等待领导者的心跳信息超时的时间间隔,是随机的
2.候选人在一个随机时间间隔内,没有赢得半数的票,那么就选举失败了,再次发动选举的等待时间是随机的
我们看了Raft算法的特点之一领导者的选举
Raft算法和Multi-Paxos的不同有两处,首先Raft之中,不是所有的节点都能当选领导者,而是只有日志比较完整的节点,才能当选领导者,日志必须是连续的
Raft算法通过任期,领导者心跳消息,随机选举时间,先来先服务的原则,保证了任期内只有一个领导者
本质上,Raft算法以领导者为中心,选举出的领导者,一切以我为准,达成值的共识,实现各个节点日志的一致
课后思考
一切以我为准,这个领导者节点模型,会有限制或者巨像呢?
从早晨将这节课的文章读完,到在午休时候又品了一边,现在看来Raft暴露的’一切以我为准’还是没有跳脱Chubby的只有主节点能服务的限制,没有实际的增加吞吐量,相当于一个只保证了可用性的单机系统