如何写测试 九
我们之前说了,测试大致可以分为三种,单元测试,集成测试,系统测试。
针对这三种,其特点可以总结如下
- 单元测试,主要是针对一个单元的测试,涉及面积最小,执行速度最快,成本低,书写速度快。
- 集成测试,涉及面积相对较广,但是设置比较麻烦,还需要配置一些配置信息,成本高,速度慢一些,但是单个测试覆盖的面积大。
- 系统测试,测试更加的复杂,需要配置各类的信息,执行时间更长,成本高,速度慢。整体覆盖面积大。
对于单元测试,因为涉及的代码最少,那么其稳定性是最高的,因为只有当涉及的小部分代码修改了,才会出现影响。其是最适合铺开的测试类型
对于系统测试,相对脆弱。如果某一个组件出现了修改,整体都会收到影响。而且定位问题的时候需要排查的地方就比较多,比较难以定位问题。
那么在实际项目中,我们该以一种什么样的类型来配置测试比例呢?
这里我们引入行业常用的两种测试配比模型,一种是冰淇淋模型,一种是金字塔模型
我们先说金字塔模型。
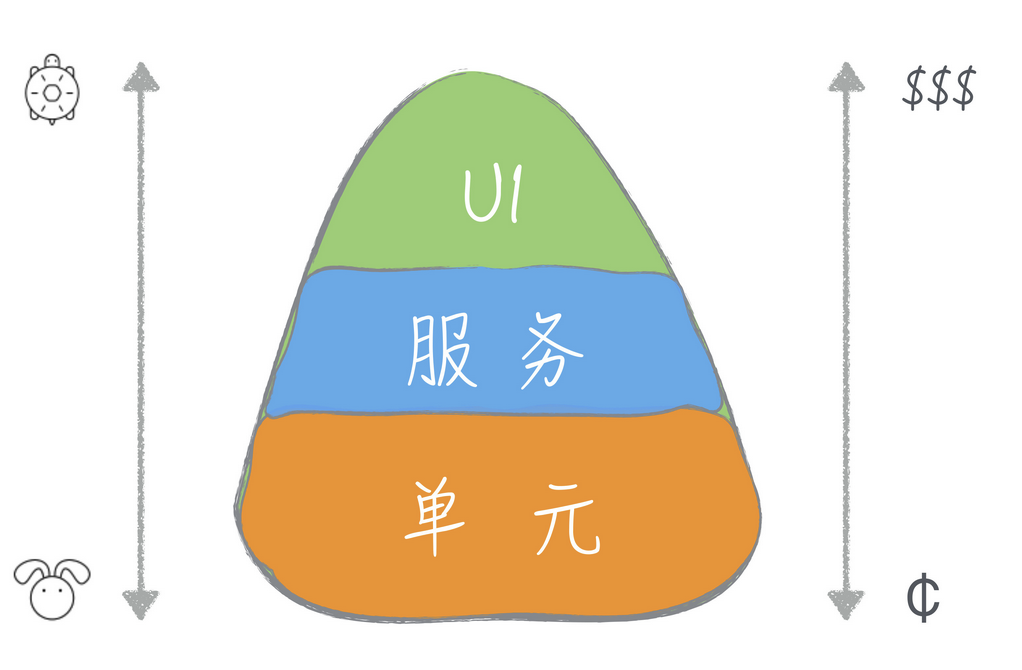
对于金字塔模型,其核心的概念是多写单元测试,越往上走测试数量越少
因为单元测试的成本低,速度快,而且最终整体覆盖面积广,所以要铺的多,铺的广。因为存在大量的单元测试,这样就可以在高层上进行一些单个测试大面积的系统和集成测试。
而冰淇淋模型则是相反
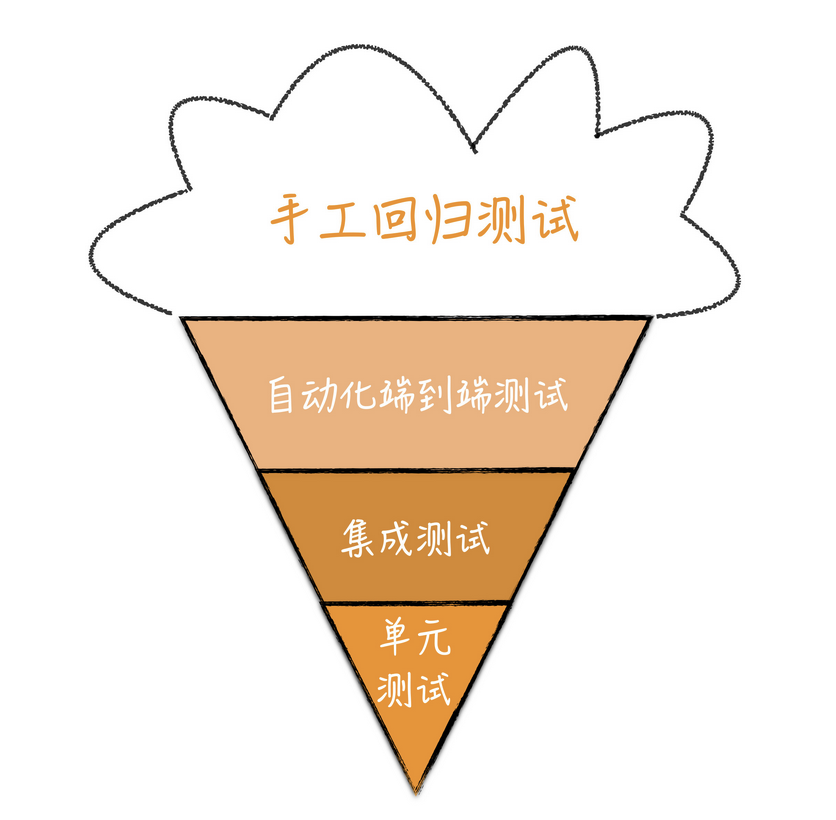
其提供了最少的单元测试,然后逐层向上,提供了更多的集成测试和系统测试。最后则是最多的手动测试。
其应该是从代码的覆盖面来考虑的,只要有一些系统测试,就可以覆盖系统的大部分情况。对于那些没法通过系统测试覆盖的代码和场景,就利用底层的单元测试来补完。
对于这两个测试,一般来说都会考虑使用金字塔模型进行测试,以单元测试为准,补完集成测试和系统测试。比如开始一个新项目,就可以以金字塔模型为准,一个功能进行拆分,然后一层层的书写代码。
那么冰淇淋模型该用到什么场景呢?
一般来说很多历史遗留的项目都是没有测试的,直到引入了某些质量审查。才开始补测试。
对于这类情况,冰淇淋模型就可以很好的建立其一个测试模型,毕竟是一个开发一定周期的系统了,那么从系统测试入手最快,补上一些集成测试。达到审查所需的基准线。
不过按照一个合理的项目来说,使用金字塔模型才是最为合适的。
那么除了介绍这样的一个测试配比模型,我们接下来还会说明,在一个遗留系统上,该如何进行测试
在给一个遗留系统,无论是写代码还是写测试,都是一个有难度的事情。
给遗留系统写测试,难度不在于测试,而是在于其代码。
因为遗留系统中进行测试,往往需要先了解这个从未写过测试的系统,如果这个系统的测试足够完善,那么只需要按照他人书写模板继续写下去即可。
但是对于一个没有测试的遗留系统,这里给出的第一个建议是,修改哪里,就给哪里写测试。
这里我们首先想到的是书写一个系统测试,但是伴随着测试的书写,测试的层次应该降低,能不写系统测试,就不写系统测试,能书写单元测试,就书写单元测试。
而给其加测试的过程中,往往也是重构原有代码的一个过程。
这里我们也是一个给遗留系统中单元书写测试的过程,来将对应的代码进行重构。
比如我们有一个单元代码,就是订单服务,其会在完成下单之后,发送一个通知消息给Kafka
|
public class OrderService {
private KafkaProducer producer; public void placeOrder(final OrderParameter parameter) { … this.producer.send( new ProducerRecord<String, String>(“order-topic”, DEFAULT_PARTITION, Integer.toString(orderId.getId())) ); } } |
这里直接依赖了Kafka进行消息的发送
这里我们如果想要测试,就需要注入Kafka这个服务器,那么就需要将Kafka从代码中解耦。
这里我们首先可以将这个send封装为一个函数
在placeOrder函数之中进行调用。
|
public class OrderService {
private KafkaProducer producer; public void placeOrder(final OrderParameter parameter) { … send(orderId); } private void send(final OrderId orderId) { this.producer.send( new ProducerRecord<String, String>(“order-topic”, DEFAULT_PARTITION, Integer.toString(orderId.getId())) ); } } |
然后就是将send函数进行抽象,将其放入一个叫做KafkaSender的类中作为一个函数存在。
|
class KafkaSender {
private KafkaProducer producer; public KafkaProducer getProducer() { return producer; } public void send(final OrderId orderId, OrderService orderService) { prouder.send( new ProducerRecord<String, String>(“order-topic”, DEFAULT_PARTITION, Integer.toString(orderId.getId())) ); } } class OrderService { … public void placeOrder(final OrderParameter parameter) { … kafkaSender.send(orderId, this); } } |
再之后就是就是将这个send方法进行抽象
提取出一个接口,这样这个发送就不会依赖于具体的Kafka服务,这样我们就封装一个Sender接口
|
public interface Sender {
void send(OrderId orderId); } public class KafkaSender implements Sender { @Override public void send(final OrderId orderId) { producer.send( new ProducerRecord<String, String>(“order-topic”, DEFAULT_PARTITION, Integer.toString(orderId.getId())) ); } } |
这样我们在书写测试的时候,只需要通过mock去模拟一个Sender接口的实现,然后进行发送就可以了。
|
class OrderServiceTest {
private OrderService service; private Sender sender; @BeforeEach public void setUp() { this.sender = mock(Sender.class); this.service = new OrderService(this.sender); } … } |
这样我们在书写测试的路上,完成了代码的重构,弥补了设计上的缺陷。
那么这里我们对于遗留系统的看法,就是先书写系统测试,然后逐渐降低书写的层级,书写单元测试,并对代码进行解耦。
将业务代码和具体实现分开,通过提取方法,将方法最终抽象为接口。