这一章,也是最后一章。我们看下如何开发一个聊天机器人,用于针对用户,以及客服部门的员工,根据他们的问题,支持查询文档或者查询订单信息
在LangChain之中,聊天机器人的开发是一个核心目标,很多人学习LangChain,其就是希望开发出更加符合用户意图的聊天机器人
那么一个聊天机器人,应该包含一些核心的组件,比如最为核心的聊天模型,相关的提示模板,和用户对话的上下文信息,外部文档或者数据库作为检索器。
那么在我们的聊天机器人之中
我们需要通过ConversationChain,配合ChatModel.来实现一个基本的聊天对话工具
然后增加上记忆能力
之后增加外部搜索能力
最后部署这个聊天机器人
那么我们就一步步的走,首先开发一个简单的聊天机器人
首先是定义一个机器人的基本类
| class ChatbotWithMemory:
def __init__(self): # 初始化LLM self.llm = ChatOpenAI() # 初始化Prompt self.prompt = ChatPromptTemplate( messages=[ SystemMessagePromptTemplate.from_template( “你是一个花卉行家。你通常的回答不超过30字。” ), MessagesPlaceholder(variable_name=”chat_history”), HumanMessagePromptTemplate.from_template(“{question}”) ] ) # 初始化Memory self.memory = ConversationBufferMemory(memory_key=”chat_history”, return_messages=True) # 初始化LLMChain with LLM, prompt and memory self.conversation = LLMChain( llm=self.llm, prompt=self.prompt, verbose=True, memory=self.memory ) # 与机器人交互的函数 def chat_loop(self): print(“Chatbot 已启动! 输入’exit’来退出程序。”) while True: user_input = input(“你: “) if user_input.lower() == ‘exit’: print(“再见!”) break response = self.conversation({“question”: user_input}) print(f”Chatbot: {response[‘text’]}”) |
通过不断的进行对话,然后存储在内存中,实现了对话的基本的记忆,也就是不断轮询,且记住了上下文。
然后我们增加检索机制,让其可以查询相关的文档库
这一部分我们之前就已经讲过,其实就是文档加载,文档分割,向量话,传入给llm
| # 加载Documents
base_dir = dir # 文档的存放目录 documents = [] for file in os.listdir(base_dir): file_path = os.path.join(base_dir, file) if file.endswith(‘.pdf’): loader = PyPDFLoader(file_path) documents.extend(loader.load()) elif file.endswith(‘.docx’) or file.endswith(‘.doc’): loader = Docx2txtLoader(file_path) documents.extend(loader.load()) elif file.endswith(‘.txt’): loader = TextLoader(file_path) documents.extend(loader.load()) # 文本的分割 text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=0) all_splits = text_splitter.split_documents(documents) # 向量数据库 self.vectorstore = Qdrant.from_documents( documents=all_splits, # 以分块的文档 embedding=OpenAIEmbeddings(), # 用OpenAI的Embedding Model做嵌入 location=”:memory:”, # in-memory 存储 collection_name=”my_documents”,) # 指定collection_name # 初始化LLM self.llm = ChatOpenAI() # 初始化Memory self.memory = ConversationSummaryMemory( llm=self.llm, memory_key=”chat_history”, return_messages=True ) # 设置Retrieval Chain retriever = self.vectorstore.as_retriever() self.qa = ConversationalRetrievalChain.from_llm( self.llm, retriever=retriever, memory=self.memory ) |
接下来我们需要将这个机器人进行部署
我们将利用Gradio来部署机器人,这是一个非常适合展示机器学习模型的框架,只需要定义少量的变量就可以展示一个模型,供用户调用
首先是安装这个包
pip install gradio
然后是相关的使用
| import gradio as gr
if __name__ == “__main__”: folder = “OneFlower” bot = ChatbotWithRetrieval(folder) # 定义 Gradio 界面 interface = gr.Interface( fn=bot.get_response, # 使用我们刚刚创建的函数 inputs=”text”, # 输入是文本 outputs=”text”, # 输出也是文本 live=False, # 实时更新,这样用户可以连续与模型交互 title=”易速鲜花智能客服”, # 界面标题 description=”请输入问题,然后点击提交。” # 描述 ) interface.launch() # 启动 Gradio 界面 |
我们将上面的代码封装为一个类
然后在gr之中声明了调用函数为bot.response
输出和返回格式都是文本
live为false声明不进行实时更新
最后通过launch启动,其会在端口7860上进行启动。
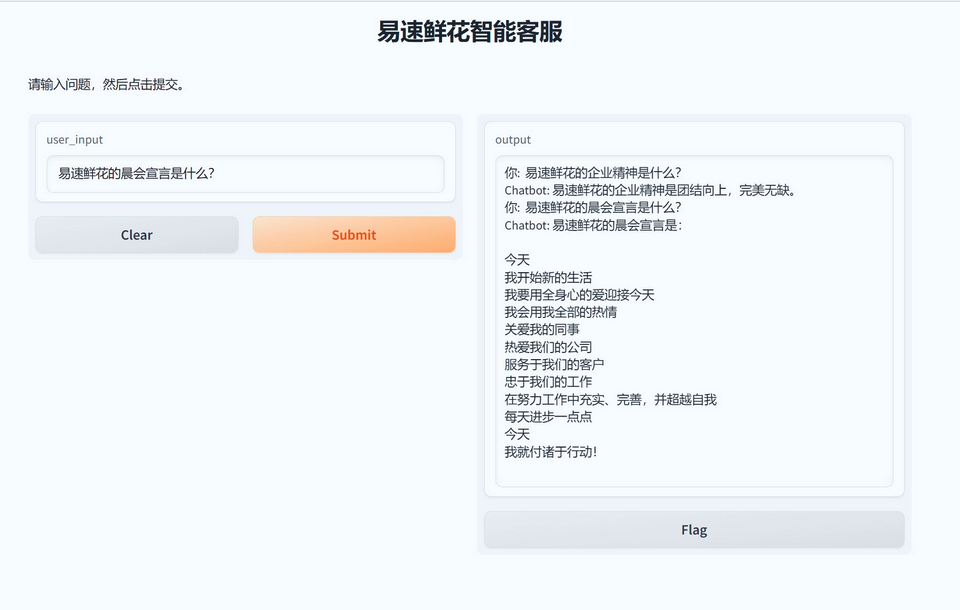
那么总结一下,我们利用LLM,记忆功能,文档搜索,开发出了一个LangChain应用,并且利用Gradio进行了部署,进行了Web交互。