之前我们实现过一个基于本地文档的QA系统,这就是所谓的RAG应用。
其全称为Retrieval-Augmented Generation 也就是检索增强生成,将文档检索和回答生成结合,可以给大模型赋予外部文档数据库查询的能力,在进行回答的时候,可以利用外部数据库进行查询,从而生成合适的回答。这也是当今企业实际中最常见的需求。
RAG的工作过程可以分为
对文档进行检索,这一步往往是将输入文本向量化后和文档向量进行匹配。
然后是上下文编码,根据文档进行一起编码。
最后是生成,使用编码的上下文,一同计算后输出答案。
那么我们看下RAG在LangChain中相关的组件。
1. 文档加载
这一部分很简单,直接使用由LangChain提供的不同种类的文档加载器。

https://python.langchain.com/docs/modules/data_connection/document_loaders/
2. 文档转换
基本上就是将长文档转换为更小的块,从而方便模型的加载。
https://python.langchain.com/docs/modules/data_connection/document_transformers/
其就是将文本切分为小的块
然后将这些小的块组合为一个更大的块,在组合的过程中会加入一些上个块的文档,从而保持块之间的上下文。
对于实际的切分,可以由分隔符,或者有特殊结构体,或者是根据LLM的令牌进行分割。
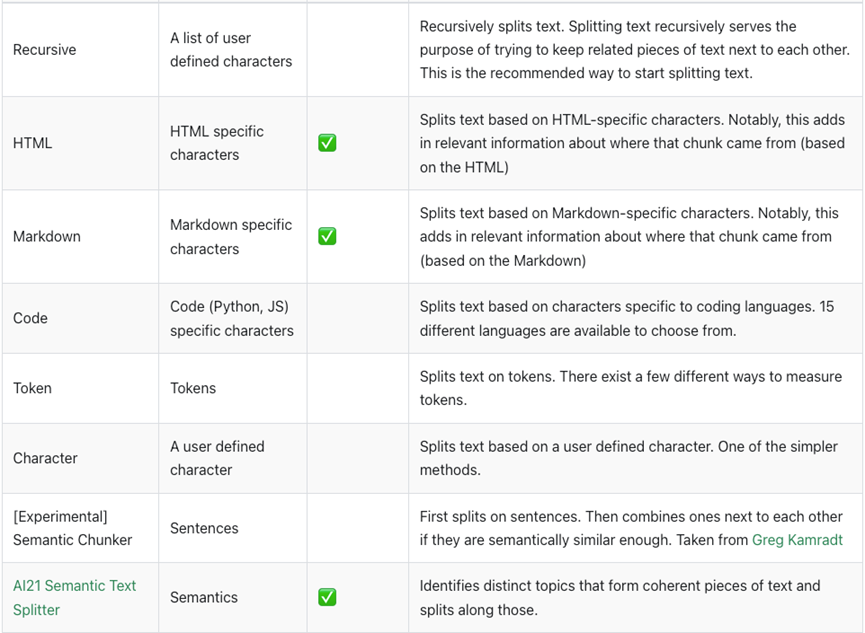
比如支持分隔符,或者html,markdown中标签,标题
或者token,主要是为了兼容token的长度。
关于不同的长度选择,也可以参考任务类型,比如任务需要比较细致的情感分析,可以考虑较小的块,如果需要全面了解文本,那么可以考虑较大的块。
除此外还有些配合文本转换的工具
比如过滤冗余的文档,使用EmbeddingsRedudantFilter工具来识别相似文档并过滤
比如利用doctran进行文档翻译
比如提取元数据信息
3. 文档嵌入
利用LLM进行嵌入,可以将文本转换为数值表示。可以在得到用户输入的时候,尽快搜索到合适的文本
如何获取一个Embedding类,如何利用其将文本块转换为向量,这些其实都在之前有使用过。
这里我们重复展示下
|
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key=”…”) |
其具有两个方法
一个是embed_documents 为文档创建嵌入,接收多个文本作为输入,并获取其向量表示。
另一个是embed_query 为查询创建嵌入,只接收一个文本作为输入
https://python.langchain.com/docs/modules/data_connection/text_embedding/
|
embeddings = embeddings_model.embed_documents(
[ “Hi there!”, “Oh, hello!”, “What’s your name?”, “My friends call me World”, “Hello World!” ] ) len(embeddings), len(embeddings[0]) |
| (5, 1536) |
|
embedded_query = embeddings_model.embed_query(“What was the name mentioned in the conversation?”)
embedded_query[:5] |
|
[0.0053587136790156364,
-0.0004999046213924885, 0.038883671164512634, -0.003001077566295862, -0.00900818221271038] |
在计算嵌入完成之后,为了减少每次计算带来的性能消耗,可以对计算的存储进行缓存,也可以直接进行存储
对于缓存,我们不多说,简单说可以直接使用CacheBackedEmbeddings
对于存储,则是使用Vector Store来进行保存。也就是所说的向量数据库
这里常见的有Chroma FAISS Lance等
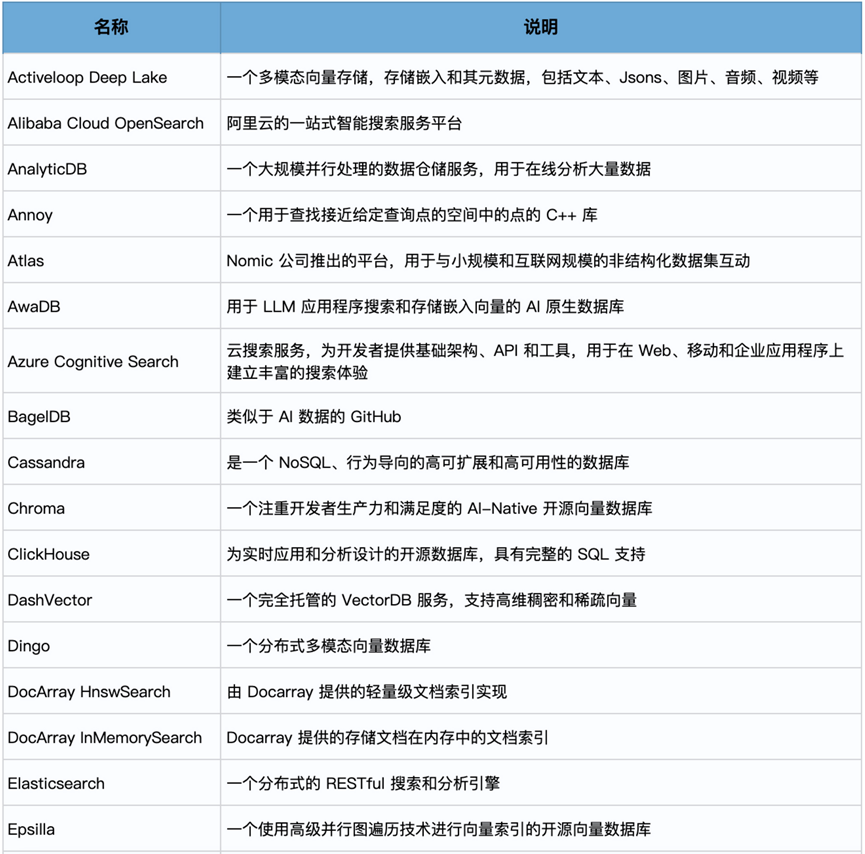
针对上述的向量数据库,我们需要根据需求进行选型。
根据数据的规模,成本,社区规模,特性来进行具体的选型。
4. 向量检索
最后我们要说的是根据向量去检索其他的向量,也就是根据用户输入检索我们向量数据库中的数据。
在LangChain中,向量检索器是封装程度相当之高的。
|
# 设置OpenAI的API密钥
import osos.environ[“OPENAI_API_KEY”] = ‘Your OpenAI Key’ # 导入文档加载器模块,并使用TextLoader来加载文本文件 from langchain.document_loaders import TextLoaderloader = TextLoader(‘LangChainSamples/OneFlower/易速鲜花花语大全.txt’, encoding=’utf8′) # 使用VectorstoreIndexCreator来从加载器创建索引 from langchain.indexes import Vectorstore IndexCreatorindex = VectorstoreIndexCreator().from_loaders([loader]) # 定义查询字符串, 使用创建的索引执行查询 query = “玫瑰花的花语是什么?” result = index.query(query) print(result) # 打印查询结果 |
其使用相对简单,但内部还是调用了不同的Vector Store存储,以及相关的模型进行向量解析。
https://python.langchain.com/docs/modules/data_connection/retrievers/
5. 索引
最后是索引,其本质上就是避免重复内容,提高查询效率的组件
LangChain利用记录管理器(RecordManager)来跟踪文档是否被写入了向量存储
https://python.langchain.com/docs/modules/data_connection/indexing
如果一个文档已经保存完成了,相关信息就会被记录在记录管理器中
其中包含文档哈希 写入时间等信息。
从而确保其被正确的管理和索引了。
那么我们总结一下,我们说了RAG的基本使用
对于这类非结构化的数据,需要进行向量生成,并根据向量进行搜索。
所以分为了文本加载,文本分割,向量解析,向量搜索等步骤
那么这里我们说完了非结构化文档的搜索
我们将在下一章说下如何对结构化数据进行搜索。