在整个LangChain之中,核心中的核心就是大模型
我们之前在演示之中使用的是OpenAI的API,而在一个商业化应用开发之中,我们常见的是使用一个自己从头训练的模型。
那么我们就简单说下如何使用使用自己的模型,以及顺便说下如何微调一个属于自己的模型。
如何获取一个属于自己的模型?
一般来说,如果自己从头训练一个模型,一次训练的费用可能达到几百万美元,这种消费只有顶级的大厂才能消费的起

所以针对个人的开发工程师,如果希望使用大模型,一般都会考虑使用大型预训练模型。开发人员只需要对头部或者部分参数按照自己的需求进行一些调整就可以。
这就是预训练模型的微调,比从头训练一个模型快的多,需要的数据集也更少
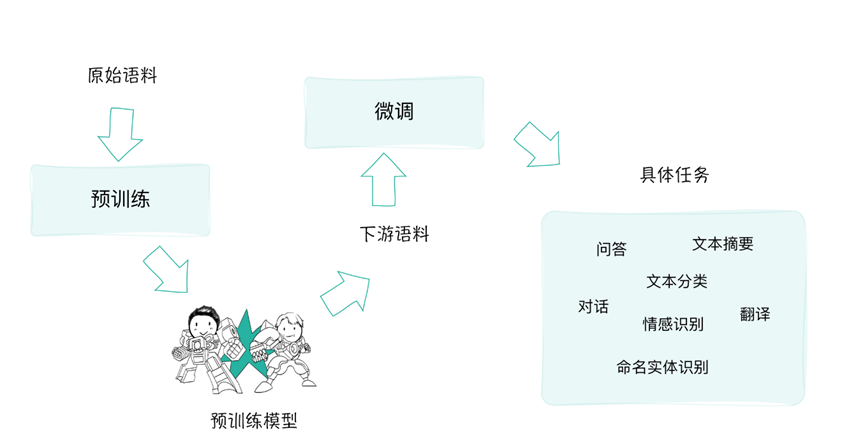
从而让我们自定义开发的应用更加容易落地
上面图中就可以分为
预训练,提供一个通用的、丰富的语言表示基础模型
微调,利用自己的领域知识,对开发模型进行垂直领域的调整。
这种1+1的模式下,做到了不需要自己寻找语料库,从头开始训练大模型,这减少了训练时间和数据需求;其次,微调过程可以快速地根据特定任务进行优化,简化了模型部署的难度;
这里我们以Meta的LIama2为例,先展示如何调用自己的大语言模型。
我们利用HuggingFace下载并导入模型。
首先是HuggingFace的使用
获取一个Token
利用pip install transformers 安装HuggingFace Library。
命令行运行 huggingface-cli login,设置你的API Token。
其次就是尝试使用HuggingFace中的meta-llama/Llama-2-7b
| # 导入HuggingFace API Token
import os os.environ[‘HUGGINGFACEHUB_API_TOKEN’] = ‘Your HuggingFace API Token’ # 导入必要的库 from transformers import AutoTokenizer, AutoModelForCausalLM # 加载预训练模型的分词器 tokenizer = AutoTokenizer.from_pretrained(“meta-llama/Llama-2-7b-chat-hf”) # 加载预训练的模型 # 使用 device_map 参数将模型自动加载到可用的硬件设备上,例如GPU model = AutoModelForCausalLM.from_pretrained( “meta-llama/Llama-2-7b-chat-hf”, device_map = ‘auto’) # 定义一个提示,希望模型基于此提示生成故事 prompt = “请给我讲个玫瑰的爱情故事?” # 使用分词器将提示转化为模型可以理解的格式,并将其移动到GPU上 inputs = tokenizer(prompt, return_tensors=”pt”).to(“cuda”) # 使用模型生成文本,设置最大生成令牌数为2000 outputs = model.generate(inputs[“input_ids”], max_new_tokens=2000) # 将生成的令牌解码成文本,并跳过任何特殊的令牌,例如[CLS], [SEP]等 response = tokenizer.decode(outputs[0], skip_special_tokens=True) # 打印生成的响应 print(response) |
利用AutoTokenizer导入了相关模型的分词器,分词器会将文本转换为模型可以理解的数字格式
然后利用AutoModelForCausalLM(加载模型的工具)
提供的from_pretrained方法来加载预训练的模型 device_map是设置模型加载到哪个设备上,比如GPU,CPU
之后利用分词器的分词功能,将输入转换为模型可以理解的格式
后面的to则是GPU格式输入转换,因为是用的GPU,需要额外的转换。
之后就是利用模型的generate方法进行响应的生成,其中max_new_tokens=2000限制文本的长度,并且用.decode() 方法转换为文本
之后就可以获取到response之中
只不过上面我们使用的模型对中文支持不好,可能得不到理想的答案
这是最为简单的调用
如果希望和LangChain进行整合的话,可能会使用起来比起上面代码更为简单
| import os
os.environ[‘HUGGINGFACEHUB_API_TOKEN’] = ‘Your HuggingFace API Token’ # 导入必要的库 from langchain import PromptTemplate, HuggingFaceHub, LLMChain # 初始化HF LLM llm = HuggingFaceHub( repo_id=”google/flan-t5-small”, #repo_id=”meta-llama/Llama-2-7b-chat-hf”, ) # 创建简单的question-answering提示模板 template = “””Question: {question} Answer: “”” # 创建Prompt prompt = PromptTemplate(template=template, input_variables=[“question”]) # 调用LLM Chain — 我们以后会详细讲LLM Chain llm_chain = LLMChain( prompt=prompt, llm=llm ) # 准备问题 question = “Rose is which type of flower?” # 调用模型并返回结果 print(llm_chain.run(question)) |
上面指定了模型名称就可以直接下载并使用模型
初始化LLM,创建模板,生成提示即可。
当然我们使用的模型比较古早,因此也没这么智能
顺带的我们说下HuggingFace Pipeline
其简化了NLP任务的使用流程,可以不需要深入理解模型细节
| model = “meta-llama/Llama-2-7b-chat-hf”
# 从预训练模型中加载词汇器 from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained(model) # 创建一个文本生成的管道 import transformers import torch pipeline = transformers.pipeline( “text-generation”, model=model, torch_dtype=torch.float16, device_map=”auto”, max_length = 1000 ) # 创建HuggingFacePipeline实例 from langchain import HuggingFacePipeline llm = HuggingFacePipeline(pipeline = pipeline, model_kwargs = {‘temperature’:0}) # 定义输入模板,该模板用于生成花束的描述 template = “”” 为以下的花束生成一个详细且吸引人的描述: 花束的详细信息: “`{flower_details}“` “”” # 使用模板创建提示 from langchain import PromptTemplate, LLMChain prompt = PromptTemplate(template=template, input_variables=[“flower_details”]) # 创建LLMChain实例 from langchain import PromptTemplate llm_chain = LLMChain(prompt=prompt, llm=llm) # 需要生成描述的花束的详细信息 flower_details = “12支红玫瑰,搭配白色满天星和绿叶,包装在浪漫的红色纸中。” # 打印生成的花束描述 print(llm_chain.run(flower_details)) |
其中我们指定了类型为text-generation 文本生成
torch_dtype=torch.float16 指定计算精度
device_map 指定了模型使用的设备,这里auto为自动选择
max_length 为生成的长度
之后就可以正常使用了。
最后我们看下如何调用自定义的模型
这里我们定义了LLM的衍生类,利用from langchain.llms.base import LLM语句导入。
需要实现
_call方法:用于接收输入字符串并返回响应字符串
可选为
_identifying_params方法:用于帮助打印此类的属性
| from llama_cpp import Llama
from typing import Optional, List, Mapping, Any from langchain.llms.base import LLM # 模型的名称和路径常量 MODEL_NAME = ‘llama-2-7b-chat.ggmlv3.q4_K_S.bin’ MODEL_PATH = ‘/home/huangj/03_Llama/’ # 自定义的LLM类,继承自基础LLM类 class CustomLLM(LLM): model_name = MODEL_NAME # 该方法使用Llama库调用模型生成回复 def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str: prompt_length = len(prompt) + 5 # 初始化Llama模型,指定模型路径和线程数 llm = Llama(model_path=MODEL_PATH+MODEL_NAME, n_threads=4) # 使用Llama模型生成回复 response = llm(f”Q: {prompt} A: “, max_tokens=256) # 从返回的回复中提取文本部分 output = response[‘choices’][0][‘text’].replace(‘A: ‘, ”).strip() # 返回生成的回复,同时剔除了问题部分和额外字符 return output[prompt_length:] # 返回模型的标识参数,这里只是返回模型的名称 @property def _identifying_params(self) -> Mapping[str, Any]: return {“name_of_model”: self.model_name} # 返回模型的类型,这里是”custom” @property def _llm_type(self) -> str: return “custom” # 初始化自定义LLM类 llm = CustomLLM() # 使用自定义LLM生成一个回复 result = llm(“昨天有一个客户抱怨他买了花给女朋友之后,两天花就枯了,你说作为客服我应该怎么解释?”) # 打印生成的回复 print(result) |
上面我们利用了一个HuggingFace线上模型
https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/tree/main
将其llama-2-7b-chat.ggmlv3.q4_K_S.bin文件保存为在了本地
我们利用的是他人训练好的量化模型
其将模型的权重简化到较少的位数,以减少模型的大小和计算需求,让大模型甚至能够在CPU上面运行。
当你看到模型的后缀有GGML或者GPTQ,就说明模型已经被量化过,其中GPTQ 是一种仅适用于 GPU 的特定格式。GGML 专为 CPU 和 Apple M 系列设计
不过希望真正运行代码的话,需要先安装pip install llama-cpp-python的包
总结一下,如果希望在本地微调自己的大模型的话,需要安装特定的包,并选择合适的大模型文件,利用其进行运行
如果希望深入学习大模型
可以考虑继续学习
PyTorch是一个流行的深度学习框架,常用于模型的训练和微调。
并辅佐HuggingFace和LangChain