流和流 流与批
我们上节说了Structured Streaming建立在Spark SQL之上,可以使用Spark SQL的各种各样的算子,那么我们今天聚焦于其中的Join算子
关注Join的主要原因是在流处理中,因为存在着数据流失,时间窗口等问题,所以关联形式有所改变
首先可以说,在流计算中,数据关联的基本形式还是Inner Join,Left Join,Right Join,Semi Join,Anti Join 按照实现方式还可以是Nested Loop Join,Sort Merge Join,Hash Join
数据分发状态可以是Shuffle Join和Broadcast Join
但是从数据关联的角度来说,可以分为流批关联,双流关联
流批关联,其实就是一个数据流和另一个离线批数据关联的
而双流关联,就是参与关联的两个表都是来自不同的数据流
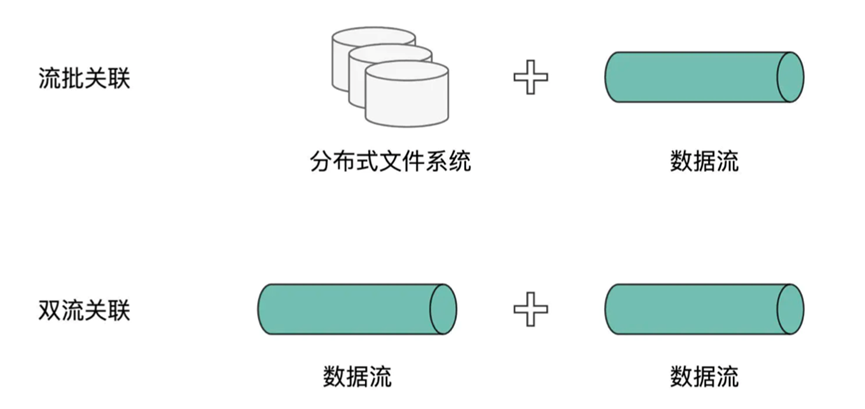
我们接下来就针对两者的不同使用和特性进行讲解
我们首先介绍流批关联
流批关联,我们可以这么理解,假设我们有一个数据流,比如用户的行为数据,这时候我们想要将用户元数据信息和数据流进行一个关联,用户的元数据信息就是常见的批数据获取方式的
这里我们直接进行演示,我们假设用户的信息存储在文件系统中
同样数据流的数据来源也设置为文件系统,我们使用相关的读取数据流的函数,设置监听某一目录,这样当有新的文件到来的时候,就会进入Spark流处理中,除此之外我们将用户的元数据放入到另一个目录中,方便查看
对于用户的元数据信息,包含以下几个字段
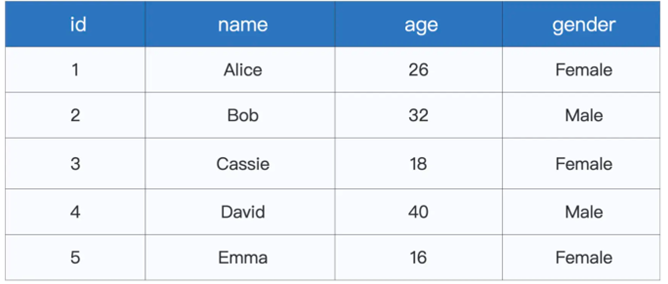
而用户的行为数据,则包含以下几个字段
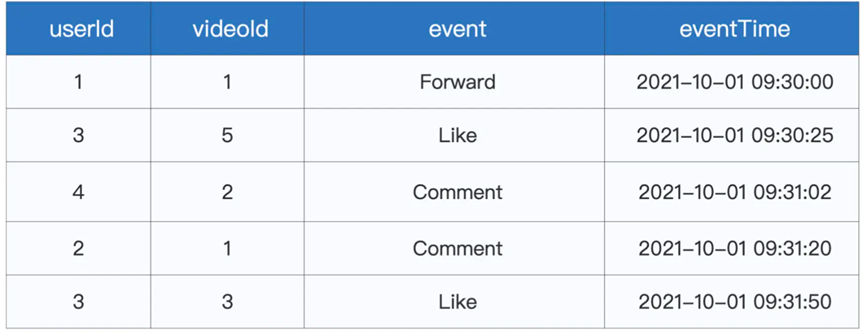
其中event是互动类型,还有视频编号,和事件时间
然后我们分别创建两个DataFrame
|
val staticDF: DataFrame = spark.read
.format(“csv”) .option(“header”, true) .load(s”${rootPath}/userProfile/userProfile.csv”) |
我们首先创建出了一个离线数据集
|
val actionSchema = new StructType()
.add(“userId”, “integer”) .add(“videoId”, “integer”) .add(“event”, “string”) .add(“eventTime”, “timestamp”) var streamingDF: DataFrame = spark.readStream // 指定文件格式 .format(“csv”) .option(“header”, true) // 指定监听目录 .option(“path”, s”${rootPath}/interactions”) // 指定数据Schema .schema(actionSchema) .load |
首先我们声明了一个schema供使用
然后创建了数据流,其中指定监听的目录
最后便是相关的join语句
streamingDF = streamingDF
.withWatermark(“eventTime”, “30 minutes”)
// 按照时间窗口、userId与互动类型event做分组
.groupBy(window(col(“eventTime”), “1 hours”), col(“userId”), col(“event”))
// 记录不同时间窗口,用户不同类型互动的计数
.count
/**
流批关联,对应流程图中的步骤5
可以看到,与普通的两个DataFrame之间的关联,看上去没有任何差别
*/
val jointDF: DataFrame = streamingDF.join(staticDF, streamingDF(“userId”) === staticDF(“userId”)
在流批关联之中,用法和DataFrame中的数据关联没有任何区别,如果流处理采用的Batch mode,那么每一个子批次都会触发一次扫描,这时候,我们只需要将离线数据集转变为广播数据集就可以了
这时候我们使用Console进行输出
jointDF.writeStream
// 指定Sink为终端(Console)
.format(“console”)
// 指定输出选项
.option(“truncate”, false) 6 // 指定输出模式
.outputMode(“update”)
// 启动流处理应用
.start()
// 等待中断指令
.awaitTermination()
除此之外就是双流关联,就比如用户创建了一条动态,这就有一条动态创建流,除此外其他用户可能对动态进行点赞,评论,这时候会有另一条流代表着动态互动流
我们这时候希望两条流可以进行合并,这就是双流合并
不过在流数据中,不能无限制的关联两条流,也就好比我们创建了一条动态,而这个动态的相关互动事件可能好几天后还有新事件,所以我们需要在关联条件中设置事件时间,以避免状态数据缓存过多的问题
我们直接贴上相关代码来查看
|
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.types.StructType // 保存staging、interactions、userProfile等文件夹的根目录 val rootPath: String = _ // 定义视频流Schema val postSchema = new StructType().add(“id”, “integer”).add(“name”, “string”).add( // 监听videoPosting目录,以实时数据流的方式,加载新加入的文件 val postStream: DataFrame = spark.readStream.format(“csv”).option(“header”, true) // 定义Watermark,设置Late data容忍度 val postStreamWithWatermark = postStream.withWatermark(“postTime”, “5 minutes”) // 定义互动流Schema val actionSchema = new StructType().add(“userId”, “integer”).add(“videoId”, “inte // 监听interactions目录,以实时数据流的方式,加载新加入的文件 val actionStream: DataFrame = spark.readStream.format(“csv”).option(“header”, tru // 定义Watermark,设置Late data容忍度 val actionStreamWithWatermark = actionStream.withWatermark(“eventTime”, “1 hours” // 双流关联 val jointDF: DataFrame = actionStreamWithWatermark .join(postStreamWithWatermark, expr(“”” // 设置Join Keys videoId = id AND // 约束Event time eventTime >= postTime AND eventTime <= postTime + interval 1 hour “””)) |
我们首先创建了两个数据流,分别设置了水位线,最后设置了关联代码
我们不仅设置了关联主键,还对两个表的事件时间进行了约束,声明只关心一小时内的数据
那么我们总结一下
本章我们说了两个不同的关联模式,分别是流批关联和双流关联
流批关联和普通的DataFrame关联类似,直接用join完成
而在双流关联中,我们一般设置了Watermark和关联条件的时间适用范围,双保险来避免出现系统性能问题