上一节我们说了在流处理过程中,涉及的处理模式,比如Batch mode和Continuous mode
这两者虽然运行的模式不同,但是最终都建立在了Spark SQL之上,在编写完成都是交付给Spark SQL和Spark Core进行执行
不过除了基本的数据处理能力之外,在Continuous mode还有着一些专门针对流处理的能力,比如Window操作和Watermark配合延迟数据处理
我们就说下在其中的特殊操作
首先是Window操作,其是Structured Streaming引擎会基于一定时间,形成一个窗口,包含一批数据,让数据流对这一批数据进行消费处理
在此之中,我们需要了解两个概念,Event time和Processing Time,和Flink一样,指的是事件时间和处理时间
事件时间对应的是消息生成的时间,一般从消息中直接取
处理时间则是消息到达Structured Streaming 引擎的时间,也被称为到达时间
Window同时支持两种时间,而且还支持不同的窗口划分方式,分别是Tumbling Window和Sliding Window。对于Tumbling Window,划分的窗口不会出现重叠,对于Sliding Window,则可能会出现重叠,以及出现遗漏
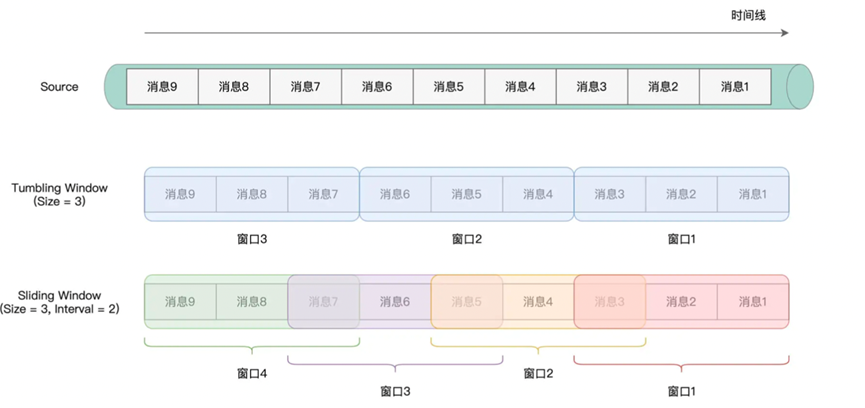
我们直接拿一个实例进行展示,其中涉及的Window操作
|
df = df.withColumn(“inputs”, split($”value”, “,”))
// 提取事件时间 .withColumn(“eventTime”, element_at(col(“inputs”),1).cast(“timestamp”)) 4 // 提取单词序列 .withColumn(“words”, split(element_at(col(“inputs”),2), ” “)) // 拆分单词 .withColumn(“word”, explode($”words”)) // 按照Tumbling Window与单词做分组 .groupBy(window(col(“eventTime”), “5 minute”), col(“word”)) // 统计计数 .count() |
这里我们的输入数据如下
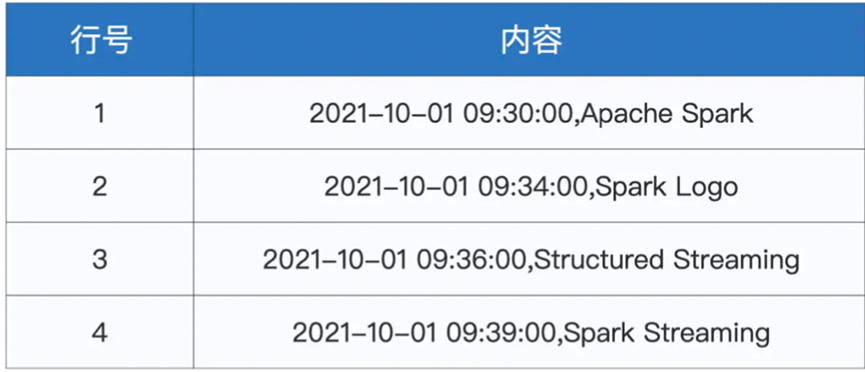
我们首先进行了分割,然后取第一个座位eventTime,然后拆分了Word,
之后创建了Tumbling Window
这里指定了窗口需要的字段,以及分割的窗口大小
如果希望修改窗口大小,则直接添加第三个参数,也就是窗口间隔
之后便是Late data和Watermark
对于Late data,指的是事件时间和处理时间不一致的消息,常见的就是迟到消息
为了解决 Late data 的问题,Streaming 采用Watermark的机制,其中包含着两个概念,水印和水位线
当有新消息到达系统的时候,Streaming会首先判断其的时间,是否大于水印,如果大于水印,则进行更新水印和水位线
如果消息在当前水印之下,那么就判断Watermark时间窗口下沿,也就是未过期的时间窗口的起始时间和当前的消息携带时间,如果大于了窗口下沿,就参与这个窗口的计算
不然就进行抛弃
而要设置容忍度,只需要给dataFrame设置
WaterMark即可
withWatermark(“eventTime”, “10 minute”)
这样,我们就设置了对应的水位线
从而增加了容忍10分钟的迟到数据