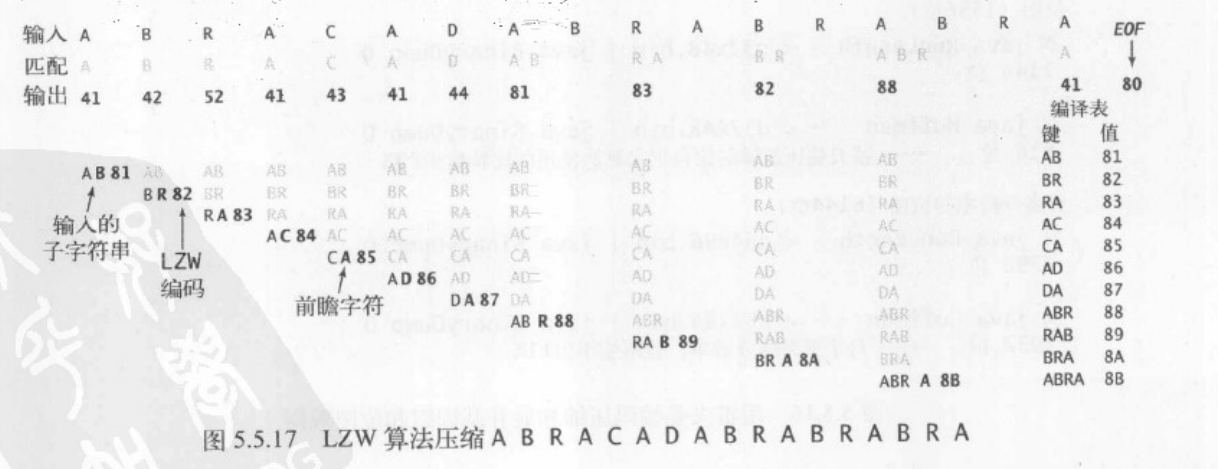
对于LZW算法,为输入中的变长模式生成一个定长的编码编译表,神奇的却是不用附上这张编译表
首先是调用了7位编码表,A为41,R为52,80保留为文件结束的值并且循环将81以后到FF之间赋予更大的值
为了制作出这样的一张表
找出未处理的输入在符号表中最长的前缀字符串s
输入s的8位值(编码)
继续扫描s之后的一个字符c
在符号表之中将s+c的值设置为下一个编码值
同样需要创建一个单词查找树
LZW的单词查找树
要查找最长的前缀匹配,先从根节点开始遍历树,按照结点的标签和输入字符匹配
从根节点开始遍历树 按照结点的标签和输入字符相匹配
在添加时候,先创建一个用新编码和前瞻字符标记的结点并将其和查找结束的结点相关联
他和霍夫曼算法最大的不同就是 霍夫曼算法任意字符都不是其他编码的前缀,但是LZW,每个由输入字符串的键的前缀也是字符串的一个键
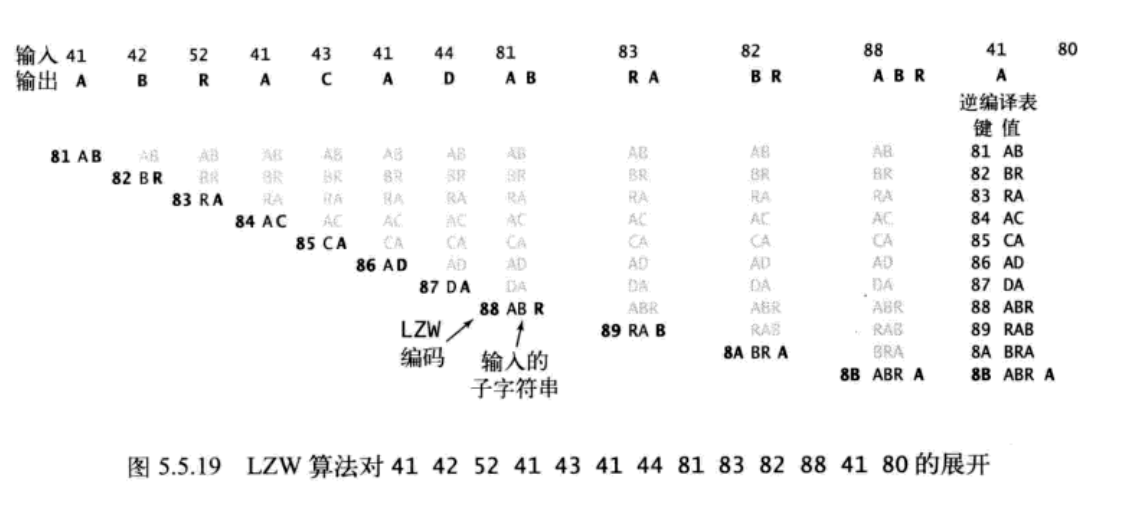
数据的展开
首先维护一张符号表,在这个表添加进入00到7F之间的ASCII的字符的关联条目
然后将第一个为关联的编码值设为81,(80为结束的标记)
保存当前字符串的val设为含有第一个字符的字符串,遇到80之前不断进行
1.输出当前字符串val
2.从输入中获取一个编码x
3.在符号表中将s设为和x相关联的值
4.在符号表将下一个未关联编码值分配为val+c ,c为s的首字母
5.将当前字符串val设为s
那么,首先是对应的压缩接口

然后是对应的解压手段
