我们越过了Spark中关于机器学习的一部分,开始正式入门Spark的另一框架,Spark的流处理框架Structured Streaming
我们仍然拿一个类似WorkCount的任务,来展示Spark相关的流计算框架使用
我们这一次为了方便使用,先使用本地的Spark进行演示,在演示的时候需要一个启动Spark-Shell,另一个用于开启Socket端口来输入数据,使用netcat, nc -lk 9999
准备好了之后,我们就可以进行Word Count的查看
在流计算框架中,使用的仍然是DataFrame进行数据的处理,而框架整理的过程可以和Flink一样,分为输入算子,处理算子和输出算子
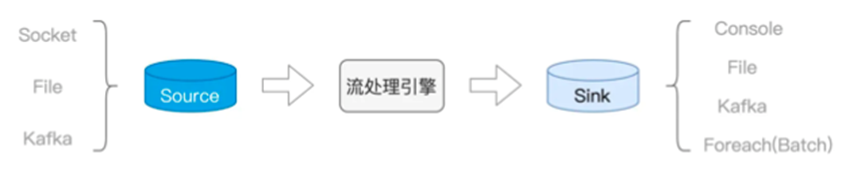
那么我们先准备输入算子
val host: String = “127.0.0.1”
val port: String = “9999”
var df: DataFrame = spark.readStream
.format(“socket”)
.option(“host”, host)
.option(“port”, port)
.load()
整体流程和Spark Session的readAPI类似
都是声明读取的模式,声明相关参数,最后进行load
其中format函数就是我们指定读取模式的函数,可以支持读取Socket,File以及Kafka
Socket用于监听某一端口作为输入数据源,方便测试
File则是文件系统,监听文件夹,将流入文件夹的文件作为数据流来看待
Kafka则是更加常见的组合
然后我们有了DataFrame之后,我们就可以直接对DataFrame进行处理
df = df.withColumn(“words”, split($”value”, ” “))
// 把数组words展平为单词word
.withColumn(“word”, explode($”words”))
// 以单词word为Key做分组
.groupBy(“word”)
// 分组计数
.count()
就比如我们从Socket输入一列“Apark Spark”,就会先利用Split拆分,再利用explode进行展平,最后利用group和count进行计数
之后是进行数据输出
我们需要调用writeStream API将处理结果写入Sink中
对应的readStream中存在的format,writeStream也有对应的format
分别是Console,File,Kafka,Foreach(Batch)
我们先创建一个writeStream,选择Console作为Sink
df.writeStream
// 指定Sink为终端(Console)
.format(“console”)
// 指定输出选项
.option(“truncate”, false)
// 指定输出模式
.outputMode(“complete”)
//.outputMode(“update”)
// 启动流处理应用
.start()
// 等待中断指令
.awaitTermination()
在其中除了format指定输出的格式,还有一个函数很重要,就是outputMode
其中我们指定了complete,但是除了complete,还有Update和Append
对应的就是
Complete mode 输出到现在为止的所有内容
Append mode 输出最近一次的计算结果
Update mode 输出有更新的计算结果
其中Append mode用于配合聚合逻辑的流计算
最后我们使用awaitTermination指定了,一直运行等待用户终端
这样我们先进行一次运行
我们不断的进行输入
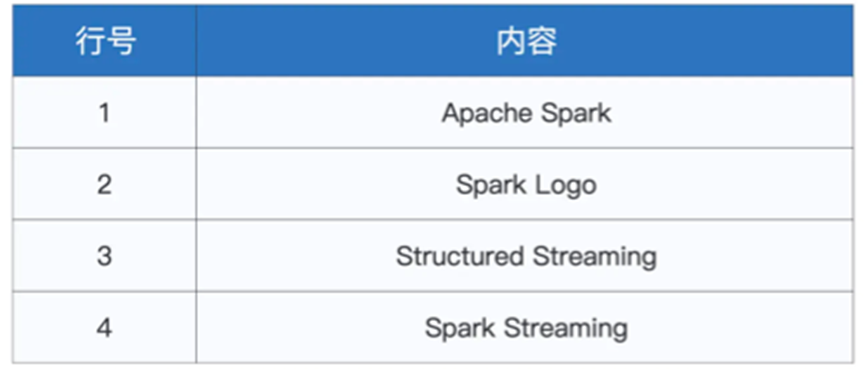
我们得到了如下的输出结果
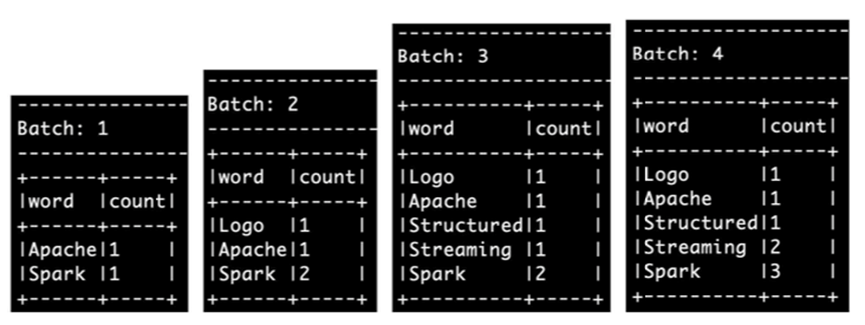
我们每一次输出都得到了全部结果
然后我们将outputMode从原本的complete改为了update
然后执行相关的代码
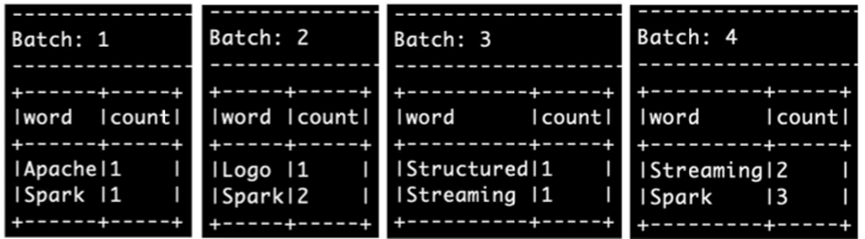
得到如上的结果
到此我们就实现了一个word count的demo
总结一下,我们学习了Spark的流计算引擎,了解内部的三个大部分
输入算子,计算算子,输出算子
并且以Socket作为输入算子,Console作为输出算子
并且阐述了不同的输出模式
Complete mode、Append mode 和 Update mode