我们来讲解DataStream中基于时间的处理方法和基于时间的算子
我们先讲解如何配置Flink中的时间特性,然后是时间戳和水位线的生成方式
之后是Flink的窗口API,Flink提供的不同窗口实现,最后还有用户自定义窗口操作和窗口的核心结构
首先是如何配置Flink中的时间特性
在Flink中,支持设定的时间特性有
processingTime, 让算子根据自己机器的系统时间得到的处理时间,但是由于数据在通信中的不确定性,可能导致不确定的结果,但是由于无需依靠水位线,故延迟低
EventTime,事件自身包含的时间,每个事件都带有一个时间戳,这样即使事件乱序到达,也会计算出正确的结果.
IngestionTime, 以进入Flink任务链,也就是在数据源处的时间作为时间戳进行处理,是EventTime和ProcessingTime的混合体,但是本身价值不大.
而如何选择使用上面哪种时间可以利用StreamExecutionEnvironment来进行设置.
StreamExecutionEnvironment.getExecutionEnvironment.setStreamExecutionEnvironment(TimeCharacteristic.EventTime) 设定
那么设置了EventTime之后,如何来确定时间戳的来源和水位线如何生成呢?
关于如何设置时间戳和水位线,可以通过SourceFunction,也可以显示的创建一个水位线和时间戳生成器
对于水位线和时间戳的生成器,DataStream API中提供了TimestampAssigner接口
从元素中获取时间戳.
而这个接口的实现者,我们建议是在数据源函数后立刻调用,避免出现元素顺序问题
那么使用的方式,就是在addSource之后进行assignTimestampsAndWatermarks()

而具体的时间分配器可以继承AsignerWithPeriodicWatermarks,也可以是 AssignerWithPunctuatedWatermark
接下来我们讲解下两者的区别
AsignerWithPeriodicWatermarks,是周期性的发出水位线来推动事件时间的前进,默认的时间间隔是200毫秒,必然可以设置,如下所示

我们上面设置了每5秒发出一次水位线,那么在5秒之后,就会调用一次期中的getCurrentWatermark()方法.
而在内部,还有一个extractTimestamp函数来进行时间戳的记录.每个记录到来都会触发一次.
而且对于AsignerWithPeriodicWatermarks,DataStream还内置了多个简便实现类
比如一个单调递增的水位线生成器

或者在单调递增的基础上,增加一个接收最大延迟的参数,比如我配置了最大支持延迟10秒

AssignerWithPunctuatedWatermark则是定点水位线分配器
其中的checkAndGetNextWatermark()方法会在每个事件的extractTimestamp()后立刻调用
由checkAndGetNextWatermark方法决定是否发出一个新的水位线

那么在设置完成水位线和时间戳后,流式应用中,核心的转换功能如何搭配使用?
在Flink的DataStream API中,提供了一组相对底层的转换,处理函数,可以访问时间戳和水位线,支持一个在特定时间后触发的计时器,并且支持多流输出
常见的处理函数有
processFunction,KeyedProcessFunction,CoProcessFunction,ProcessJoinFunction,BroadcastProcess Function,KeyedBroadcastprocessFunctoon,ProcessWindowFunction以及 ProcessAllWindowFunction
上面的名称就是为了不同的上下文环境准备的
比如KeyedProcessFunction就是专门作用于KeyedStream,实现RichFunction,支持open,close,getRuntimeContext()等方法
而且ProcessFunction还提供了
ProcessElement,针对流中每条记录都调用了一次.其中传入了一个Context对象,可以利用其去访问时间戳,获取键值对信息,以及将结果发送到副输出中.
OnTimeer,一个回调函数,在注册的计时器出发的时候被调用
Context中提供了一些方法
CurrentProcessingTime 返回当前处理时间
CurrentWatermark 返回当前水位线的时间戳
registerProcessingTimeTimer 注册一个处理时间计时器
registerEventTimeTimer 注册一个事件时间计时器
deleteProcessingTimeTimer 删除一个处理时间计时器
deleteEventTimeTimer 删除一个事件时间计时器
由于计时器触发会调用onTime,那么为了避免冲突,processElement和onTimer是同步的
而一个ProcessFunction中可以注册多个计时器,每个键值对有多个计时器,以键值+时间戳为key进行注册
那么如果有时间计时器在应用重启后已经过了执行时间,那么会立刻触发.同理,如果注册的计时器的时间戳是一个过去时间,那么也会立刻触发.
那么我们创造一个processFunction,会在温度一直上升时触发警报.


我们之前还说了DataStream可以进行多流输出,那么如何拆分为多条流呢?
ProcessFunction提供了OutputTag[X]方便多流输出
在主流程中获取的方式很简单

向其中输入数据的方式也很简单

其次是CoProcessFunction
跟CoFlatMapFunction类似,CoProcessFunction提供了每个输入上的转换方法,processElement1()和processElement2(),使用方式和ProcessFunction的方法类似,传入一个Context对象,来访问当前元素或者计时器时间戳.同样提供了onTimer()回调方法.
比如,我们可以基于其来控制数据录入开关


这样我们结合如下的数据流就可以控制数据的录入与否

有了时间之后,窗口这个流式应用中非常常见的操作也是可以实现的
基于时间逻辑定义的按照一定规则对事件进行分组,并对组中有限的内容进行计算的方法.
DataStream API提供了内置窗口,并且提供了可用于窗口的函数,以及提供了自定义窗口逻辑的方式
在整个流计算中,使用窗口很简单,传入一个window assigner,会产生一个WindowedStream.
在具有键值和非键值的分区上进行窗口分配的方式为
Stream.keyBy().window()
Stream.windowAll()
虽然窗口分为了键值和非键值,但是我们只讲述键值窗口,因为非键值窗口的行为和其完全相同,只不过无法并行计算.
那么Flink提供了哪些内置的窗口分配器.
首先是基于数量的,这一个就是按照固定数量进行分组,但由于元素到达的不确定性,所以会有些不确定的结果.
而基于时间的窗口,会提供一个默认的触发器,在超过了窗口的结束时间就会触发窗口计算,窗口也会伴随着系统的首次分配元素而创建.
内置的窗口类型为TimeWindow.主要包含的内置窗口分配器有滚动窗口,滑动窗口,会话窗口
滚动窗口分配器会将元素放入固定大小且不相互重叠的窗口中

DataStream API针对事件时间和处理时间提供了不同的滚动窗口分配器
TumblingEventTimeWindows或者TumblingProcessTimeWindows,而无论哪种滚动窗口分配器,都是只接收一个参数,即窗口大小,利用分配器的of来指定,时间间隔可以是毫秒 秒 分钟,小时,天
比如
.window(TumblingProcessingTimeWindows.of(Time.second(1)))
.window(TumblingEventTimeWindows.of(Time.second(1)))
除此外,Flink还提供了简写能力
比如 .timeWindow(Time.second(1)),这样写的话,是会创建一个滚动窗口,具体的方法取决于配置的时间特性
当然除了间隔外,还可以指定一个偏移量,比如如下代码

这样我们就创建了一个1个小时大小的窗口,但是具有偏移量,这样其会从00:15:00 01:15:00等开始

滑动窗口
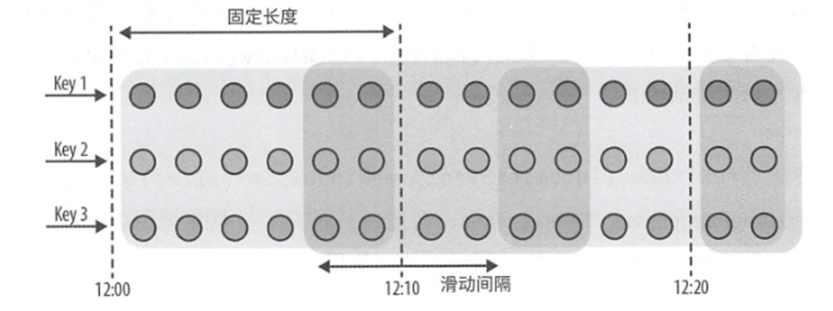
按照固定大小且指定滑动间隔移动的窗口
对于滑动窗口来说,需要制定窗口大小和新窗口开始的滑动间隔
如果滑动间隔小于窗口大小,那么窗口会出现重叠,这样元素会分配给多个窗口,如果滑动间隔大于窗口大小,那么会丢失一些元素
那么我们接下来创建一个,大小为1个小时,滑动间隔为15分钟的窗口,那么往往一个事件会被放入四个窗口中
会话窗口
会将元素放入长度可变且不重叠的窗口中,会话窗口的边界是由一个设定的非活动时间决定的,如果持续没有收到记录的时间达到了设定间隔,那么就会出现新的会话.
使用的方式为
而Flink在实现会话窗口的时候,会将每个到来的元素映射到一个属于它自己的窗口中,这个窗口的起始时间是元素的时间戳,大小为会话间隔,然后分配器会将范围内存在重叠的窗口合并.
那么如何在窗口上使用函数,可用于窗口的函数类型有两种:
增量聚合函数, 会存储某个值并且根据每个加入窗口的元素来对这个值进行更新,这个函数会十分的节省时间并且会将聚合值作为单个结果发送出去.比如ReduceFunction
全量窗口函数,会接受窗口所有元素,然后遍历处理,支持更加复杂的逻辑,但是占用空间但,比如ProcessWindowFunction就是一个全量窗口函数
首先是ReduceFunction
会接收两个相同类型的值并且组合成一个新的,但是类型不变的值
那么窗口只需要存储当前的结果,然后当收到一个新的元素,算子都会将其和状态中的值一起调用ReduceFuntion,然后进行替换窗口状态
使用起来比如下面的代码

AggregateFunction
和ReduceFunction类似,其也只有一个值,不过类型不要求相同,更加灵活,如何是实现一个AggregateFunction接口

比如我们会需要获取一个传感器的平均温度,内部维护了不断变化的温度总和,在getResult()方法来计算平均值

ProcessWindowFunction
ReduceFunction和AggregateFunction可以进行增量计算,但是对于更加复杂的计算,比如获取窗口中数据中频率最高的值这样的需求,就需要ProcessWindowFunction来进行计算.
ProcessWindowFunction接口的定义如下

其中process()方法参数中包含,一个Context.一个访问窗口内部元素的Iterator和用于发出结果的Collector,方便我们进行计算
此外Context参数的实现中,可以获取当前处理时间,水位线,状态访问器等
需要注意,上面包含了单个窗口状态的访问和全局状态的访问.
全局状态好说,那么为什么需要单个窗口呢?是因为由于存在迟到数据的可能性,所以可能会多次触发process(),而使用了单个窗口状态的ProcessWindowFunction需要实现clear()方法
来清理使用的单个窗口状态.
而且ProcessWindowFunction处理的窗口会将所有已经分配的事件存储在ListState中,所以占用的状态会大得多.
最后我们给出一个ProcessWindowFunction的实现

在process中计算最高最低温度,并形成对象进行返回\.
有很多函数往往是增量聚合,但是又希望可能保存更多的数据,那么可以将ReduceFunction或AggregateFunction和ProcessWindowFunction结合使用,进行聚合
比如下面这样,讲ProcessWindowFunction作为reduce和aggregate的第二个参数

这样每当数据到来的时候,会先在Reduce或者Agg中进行聚合,然后再传递给ProcessWindowFunction中进行处理,这样传递给process方法中的Iterable只会有一个值.
最后一个常见的使用需求是对具有时间概念的两个流进行彼此join,比如我们有两个流,那么我们想要进行Join,只要B中的时间戳比起A的时间戳不早于1小时 且不晚于15分钟就可以JoIn
同理A对B也是如此
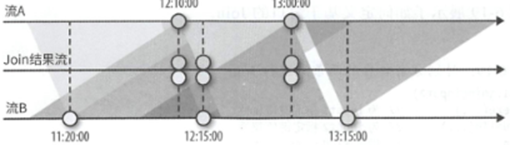
上述我们说的时间间隔,指的是间隔Join中的上界和下界,分别由两个时间间隔来进行定义
比如between(Time.hour(-1), Time.minute(15)) 就是上面我们说的间隔,使用方式也如下

我们这样设定了之后,对于第一个输入来说,所有时间戳大于当前水位线到上届间的数据都会被缓冲
第二个输入来说,所有时间戳到下届之间的数据都会被缓冲
故由于事件时间可能不同步,所以存储会增加.
这是一部分,其次是基于窗口的Join
其实就是将两条输入流中的元素分配到公共窗口并在其中完成Join
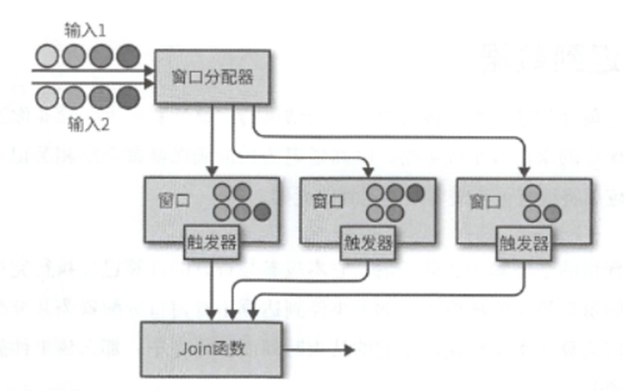
就是两条输入流都会根据各自的键值属性进行分区,然后将两者分配到公共窗口内,当窗口的计时器出发的时候,会遍历两个输入中元素的每个组合,调用JoinFunction,整体流程为
Input.join(otherinput)
.where() 对input进行分区
.equalTo() 对otherinput进行分区
.window() 指定windowAssigner
.apply() 指定JoinFunction
其中支持了在窗口前和后进行调用,参数都包含一个Iterable对象,可以在其中获取元素并删除元素
除了对两个流进行Join之外,还可以对其进行Cogroup(),Join和CoGroup的总体逻辑相同,两者的唯一区别在于,Join会为两侧输入的每个事件对,调用JoinFunction, 而CoGroupFunction会以两个输入的元素遍历器为参数进行调用.