Flink的状态管理
大部分的流计算中都是有状态的.那么我们会介绍不同种类的状态,和状态如何进行保存的,以及如何利用状态进行扩缩容.
假设我们有一个任务,其负责计算收到了多少条记录,那么在收到一个记录的时候,就会访问状态获取已经统计的数目,然后更新状态,最后发送出去.
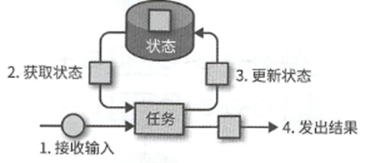
那么这个状态的维护是Flnik需要搞定的,其需要高效可靠的管理状态.
在Flink中,状态是和某些算子进行绑定的,为了让Flink知道算子具有的状态,算子需要自己注册状态,根据作用域的不同,可以分为了两类,算子状态和键值分区状态.
算子状态作用于某个算子任务,一个算子任务中无论有多少状态,都共享一个状态
故提供了三种不同类型的算子状态
1. 列表状态,将状态展示为一个条目列表
2. 联合列表状态,将状态展示为一个列表,但是扩缩容的时候不一样
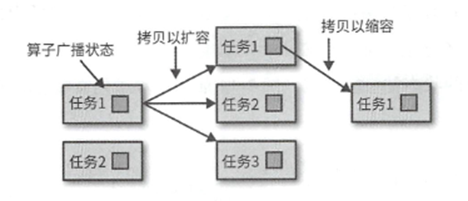
3. 广播状态,保证所有并行算子的状态一致.
键值分区状态,则是根据键值来进行维护和访问,这个状态的划分根据的是键值而非算子,故Flink更加方便维护.扩缩容的时候也更加方便
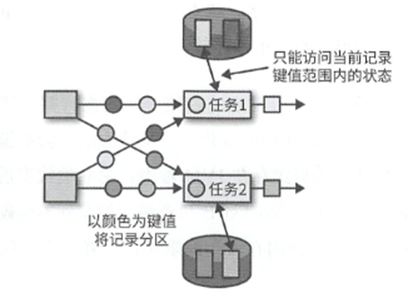
而且键值的类型更加灵活,更加贴近业务:
1. 单值状态,存储了一个任意类型的值,这个值可以任意类型
2. 列表状态,每个键存储一个值得列表,列表中的条目可以是任意类型.
3. 映射状态,每个键存储一个键值映射,key和value可以是任意类型.
状态后端
我们需要了解状态是如何存储的,在Flink中,为了保证快速访问状态,会把状态维护在本地.
而本地往往有一个具体的组件负责存储,维护,访问.这个组件名为状态后端.
有的状态后端直接将状态作为对象,序列化后以内存的方式存在于JVM中
另一类RocksDB,则会将状态对象写到RocksDB上,最终写到本地磁盘中
而上面不同装填,在扩缩容的时候也是不一样的
比如键值对,由于是跟数据的键值相关的,所以相对简单,在分配的时候,将所有的键值分为了不同的键值对组,然后以组为单位进行分配.
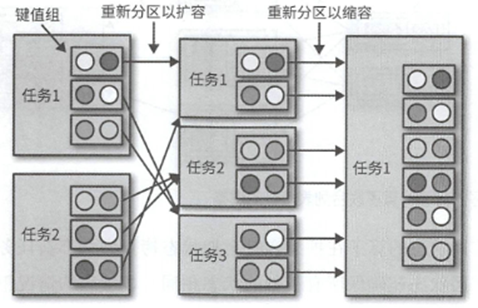
算子状态的算子中
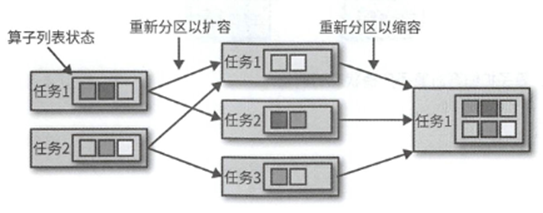
对于算子列表的扩缩容,所有算子任务的状态会被统一收集起来,然后分配到更多或者更少的任务中,如果列表条目的数量小于新设置的并行度,那么某些任务启动时候的状态会为空.
算子联合列表状态的算子在扩缩容的时候会将全状态拷贝到新任务上,交给算子自己决定丢弃哪些
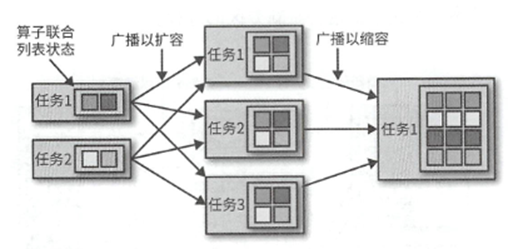
广播状态的算子会将状态拷贝到全部新任务上,也会将状态拷贝到新任务上,确保所有任务的状态都能相同.缩容的时候也可以简单的停掉多余的任务