Flink的状态恢复
Flink是一个分布式的数据处理系统,所以需要处理一些故障,对于故障恢复,Flink提供了检查点来进行保存,并提供了savepoint来让用户可以自定义保存.
首先是检查点机制
传统的流式应用的一致性检查点是在所有任务处理完等量的原始输入后对全部任务状态进行一个拷贝
简单的实现可以为
1.暂停所有的输入流
2.然后等待所有任务处理完已输出的数据
3.最后将所有任务的状态拷贝到远程持久化存储中,生成检查点,在所有任务完成拷贝后,确定检查点生成完成.
4.恢复数据流输入.
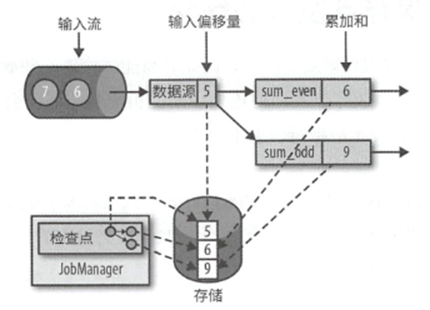
那么根据这个状态进行恢复如下
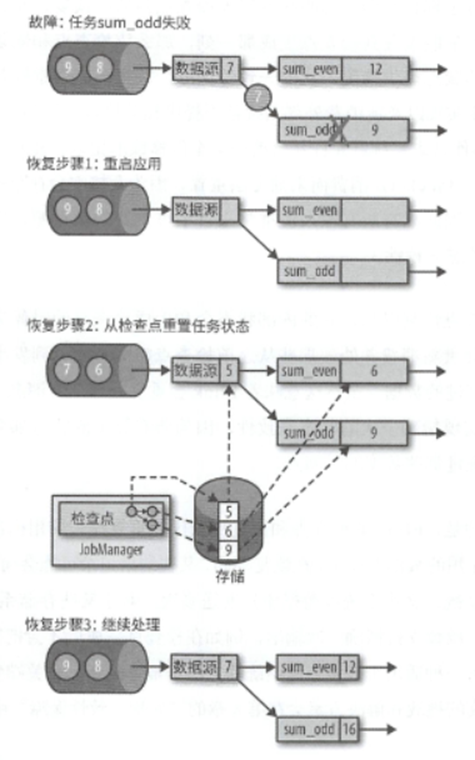
利用最新的检查点来重置任务状态
然后恢复所有任务的处理
上面图中可以看出来一点,就是在恢复的时候,往往需要数据源配合进行恢复,类似Kafka就允许从之前的某一个偏移中读取记录.如果无法重置,那也无法满足精准一次的状态一致性.
而且对于精准一次,还需要数据输出数据源支持,对于某些存储系统,支持事务方式的提交,在检查点完成后才会提交写出的记录.
Flink中检查点算法的具体实现基于了Chandy-Lamport算法,避免了stop-the-world的尴尬.
会产生一类名为检查点分隔符的特殊标记,会通过数据源注入到常规的记录中,相比较于其他的记录,在流中的位置无法提前或者延后.确保了数据流可以被分为已检查和未检查的.
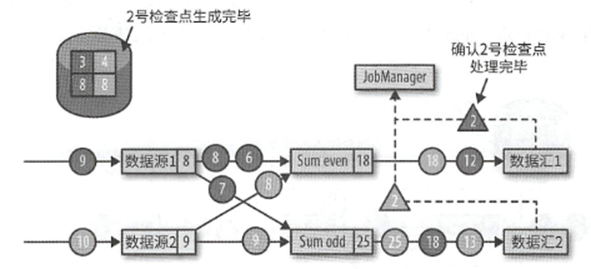
我们来简单示例下这个算法,比如下面,应用中包含了两个数据源任务,任务输出分为了两个部分.分别是奇数流和偶数流.
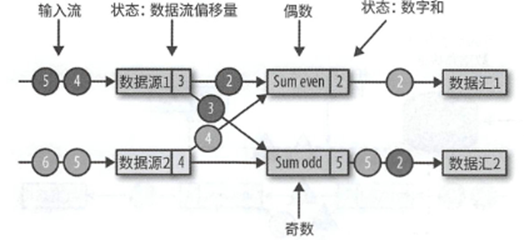
然后当检查点触发的时候,JobMananger会发送一个新的检查点编号
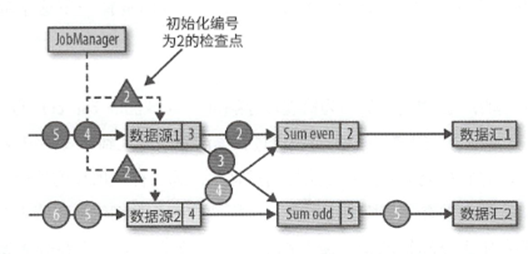
当数据源收到消息之后,就会暂停发送消息,然后利用状态后端生成检查点
之后便是将检查点分隔符连同编号一同广播给所有的下游分区.
最后向JobManager发送确认消息
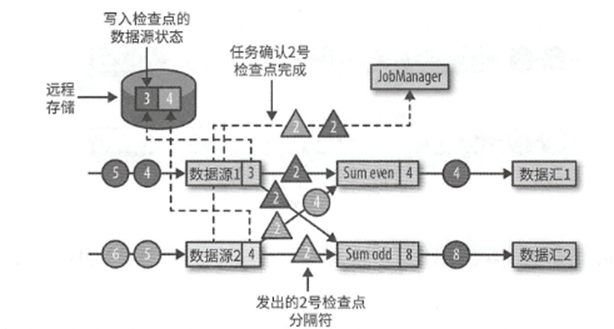
然后下游的任务收到了分隔符,这时候会等待其他分区发来分隔符,对于已经发来了分隔符的分区,新到的记录会被缓冲起来.这个等待所有的分隔符到达的过程称为分隔符对齐.
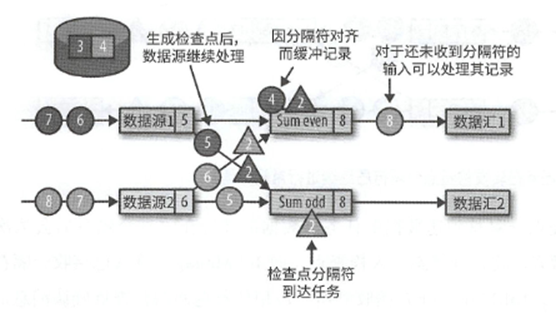
而在所有的分隔符都到齐之后,会开始生成检查点,写入状态,并将分隔符广播到下游相连任务
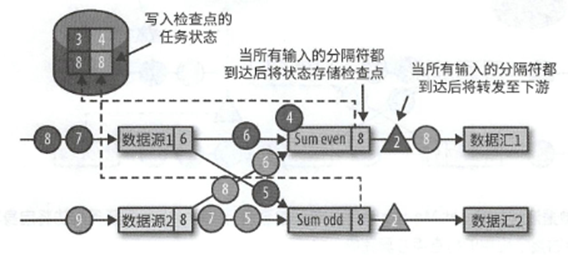
发出分隔符之后就会开始缓冲记录,等到所有缓冲记录处理完成之后,就会继续开始处理缓冲的记录
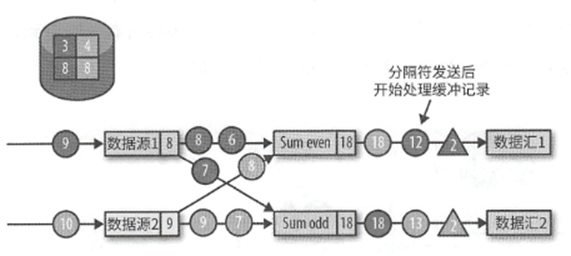
最终检查点分隔符到达了输入算子,那么在分隔符对其之后,就会将自身状态写入检查点,然后发送确认给JobManager.在JobMananger收到了所有应用任务的确认之后,就会将此次检查点标记为完成.
其次是Flink提供的保存点机制
检查点会周期性地生成,会在应用处理完成后自动丢弃.而保存点不一样,这是Flink交给用户,让用户完成的保存操作.
通过一个保存点,可以让一个应用中的数据初始化状态到生成保存点的那一刻,这样看适合检查点机制类似,但他更适用于在一个完全相同的集群上,以完全相同的配置,运行完全相同的应用.
这样可以做简单的AB测试
或者以不同的并行度启动原应用
在集群之间进行Flink的迁移
保存不同版本的应用.
一个简单的实践就是将流式应用迁移到实例最低的数据中心.
那么如何从保存点启动一个应用
一个应用往往包含多个算子,每个算子都可以定义一个或者多个状态,在保存点生成的时候,算子状态会被保存到一个持久化的位置上.而在保存中,会按照算子标识和状态名称进行组织保存,key为算子名称,value为算子状态,这样启动的时候,需要能找到对应名称的算子,默认情况下,算子名称会被分配一个唯一标示,但是是自动生成的,所以可能会变化,故建议手动制定算子标识,而不是依赖于Flink默认分配机制.