由于一般情况下,我们往往利用Kafka这类中间件进行数据的清洗
将原始数据加工为更为上层,更加贴合业务的数据
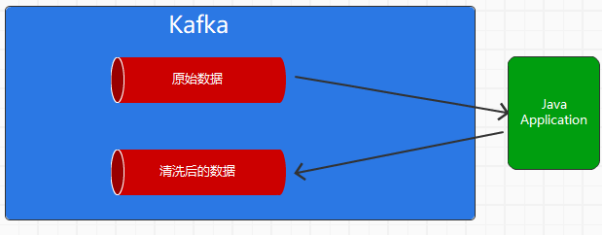
故需要一个Agent既当consumer ,又当Producer
这就要求,作为consumer拉取到数据后,需要开启一个事务,如果处理完成,那么就提交偏移量到server,表明自己作为consumer消费成功,然后将处理后的数据,作为生产者将数据发送出去,提交事务
需要注意,一般我们设置consumer的时候,一般都是设置enable.auto.commit 为true
这种情况表示自动提交,但对于手动提交,则是设置下面的配置
props.put(“enable.auto.commit”, “false”);
// 消费方式:从最新的位置读,还是从最早的位置读取数据
props.put(“auto.offset.reset”, “earliest”);
然后在业务代码相关的模块中
| producer.initTransactions();
while (true) { producer.beginTransaction(); try { ConsumerRecords<String, String> records = consumer.poll(1000); //System.out.println(“cnt = ” + records.count()); Map<TopicPartition, OffsetAndMetadata> map = new HashMap<>(); for (ConsumerRecord<String, String> record : records) { map.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset())); } // 将生产者和消费者融合在一起 producer.send(new ProducerRecord<String, String>(“itdachang-2”, “test”)); producer.sendOffsetsToTransaction(map, “itdachang”); producer.commitTransaction(); } catch ( Exception e ) { producer.abortTransaction(); } finally { } } |
首先创建了一个事务管理器
然后在while中,producer开启了一个事务
Producer.beginTransaction()
之后分别拉取消息和处理消息,之后,根据是否成功,确定是否同步消息,以及提交事务