这次我们来说下分布式计算中相当火的一个框架Flink
分布式计算在我们前面有所了解过,即移动数据不如移动计算,因此我们考虑数据和计算位置的关系,数据和计算位置需要考虑计算负载的平衡
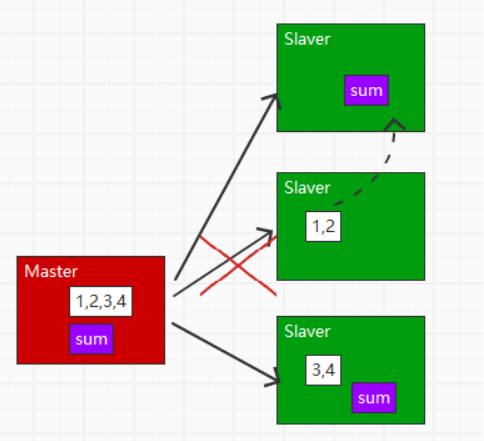
在分布式计算中,存在着两个比较常见的分类
即实时数据分析和离线数据分析,在实时数据分析之外,还有着准实时数据分析的概念
实时数据分析,指的是数据处理的延迟是以毫秒为单位,称之为实时数据分析
离线数据分析,指的是数据处理的延迟以小时及以上为单位,称为离线数据分析
准实时数据分析则是处理的延迟在两者之间,但没有达到实时的低延迟
对应实时数据分析,常见的数据来源是流数据,即数据像水流,源源不断的来
离线数据分析的数据往往是有固定边界的,数据是一批批的
其次在数据处理计算中,也可以根据是否有状态,进行区分
比如数据在计算过程中是否存在中间状态,即是否保存中间计算结果,将其分为有状态和无状态
那么Flink是一个什么样的框架呢?
在官网上,把Flink描述为了一个有状态的流式架构,且包含了批量计算和流计算,是现在实时数仓领域的不二选择
除此外,Flink还有着一些优点
支持高吞吐,低延迟,高性能
并且自己拥有着基于JVM实现的独立的内存管理
而且存在着数据窗口的概念
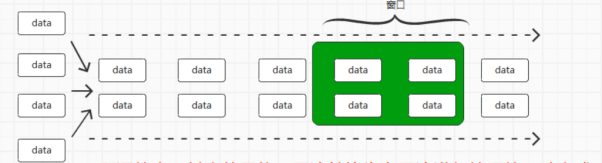
即按照时间划分一定的窗口
而且Flink中也自己存在着一定的时间观念
ProcessingTime,处理时间
EventTime事件事件
Ingestion Time 进入时间
还有容错机制,即添加了集群状态的checkpoint,一旦任务失败,就可以进行从检查点回滚数据
然后对于Flink的架构
我们从不同的角度来进行看Flink,分别从组件组成,软件架构
对于软件组成,Flink本身集群架构采用了Master-Slave架构,Master在集群中实际为JobManager,Slave为TaskManager
除此外还有一个重要的角色是Client,Client虽然不是运行任务的节点,但是也是重要组件之一,负责提交任务
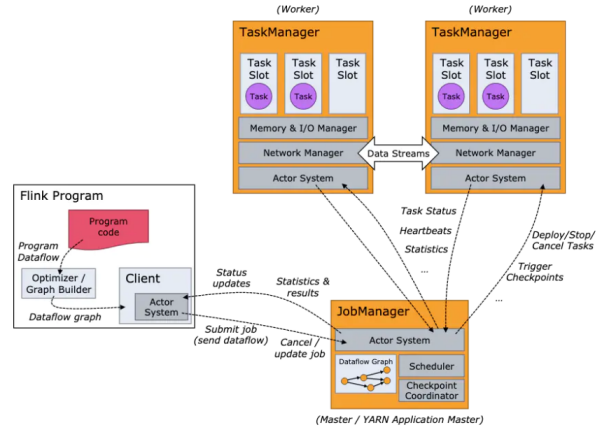
我们分别看不同的组件详情
Client:其主要目标是提交任务给JobManager
JobManager:负责协调Flink application的分布式执行,执行task调度,Checkpoint协调
内部的主要功能组件如下:
ResourceManager:负责资源调配工作,因为资源调配的基本单元是task slot,故ResourceManager主要去管理task slot的.不过因为Flink会因为不同的环境提供不同的实现,所以在不同的环境中ResourceManager对task slot可进行的操作也是不同的
Dispatcher: 提供了一个REST接口来让client提交任务,并为其启动一个新的JobMaster
JobMaster,负责管理和执行一个JobGraph,Flink中每一个job都有自己的JobMaster
整体来说,一个Flink Cluster至少有一个JobManager,高可用的情况下,可以有多个JobManager,但是只有一个是Leader,其他都是stander
TaskManager,是一个用于执行任务的组件,内部包含的task slot是集群最小的资源调度单元,内部包含的task slot数量,代表了TaskManager能并发处理的task数量
Task Slot
Flink集群中每一个TaskManager是一个JVM进程,TaskManager能够执行一个或者多个Task,而Task的执行上限就是通过task slot表示的
每个task slot代表task Manager中的固定资源子集,就是一个TaskManager下有3个task slot,那么每个task slot所分配的资源为Task Manager管理的内存的1/3,不过需要注意,只分配了内存,CPU,硬盘等资源并没有隔离
在基础组件形成的架构之上,内部系统的还存在这分层的设计架构,基本分为三层
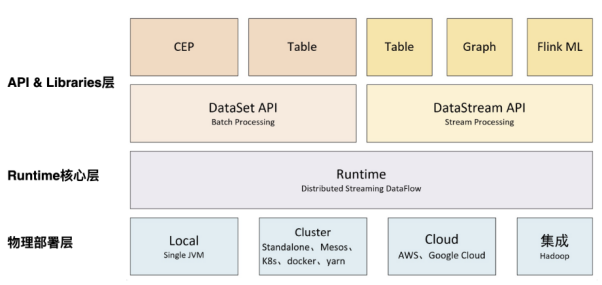
从下往上看
首先是Deployment
主要是根据部署的不同,进行的区分,Flink支持多种部署模式,分别是本地 集群(Standalone) 云
其次是Runtime核心层
负责为上层的不同接口提供基础服务,也是Flink分布式计算框架的核心实现层,支持分布式stream作业执行,JobGraph到ExecutionGraph的映射转换,任务调度等
在最为上层的是API和Libraries层
作为分布式数据处理框架,向外直接暴露了流计算和批计算的接口,而且还有些额外的组件库,比如SQL&Table库以及基于批处理的FinkML(机器学习库),Gelly(图处理)等
API层还包括着构建流计算的DataStream API 和 批计算的DataSet API
Flink和Spark相比,Spark是利用批计算来模拟的流计算,实现起来更加复杂和难用
而Flink则与之相反,使用流计算来模拟批计算,更加的通透
然后我们拿一个简单的WorkCount的需求来查看如何使用Flink
需求其实很简单,作为一个文件,读入进项目中,作为有界流
然后进行每一行的fork,fork完成对每一行进行读取,确定一行中包含的文字及出现的次数,然后进行join操作,将每一行出现的文字,进行join,确定每一个文字出现的频率,画图如下
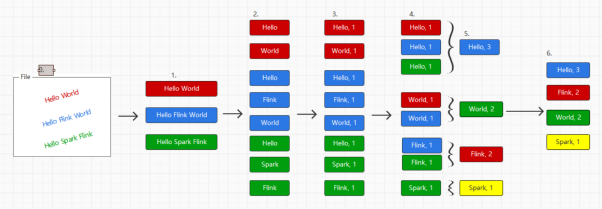
第一步必然是将数据读入的Flink,作为一个有界流
然后按照行进行拆分文件
其次对每一行进行实际的处理,并再之后形成文件-数量的数据结构
然后依次进行join,对数据进行group整合,形成group后的结果,然后就可以操作结果并返回了
那么在java中的基本实现如下
引入对应的依赖
| <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <flink.version>1.13.1</flink.version> <java.version>1.8</java.version> <scala.binary.version>2.12</scala.binary.version> <maven.compiler.source>${java.version}</maven.compiler.source> <maven.compiler.target>${java.version}</maven.compiler.target> <log4j.version>2.12.1</log4j.version> </properties> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> </dependencies> |
然后进行上述的Flink的书写
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
然后通过Flink进行文件的读取
final DataSource<String> fileDataSource =
env.readTextFile(“D:\\idea\\classes\\flink\\data\\word.txt”);
接下来使用flatMap的操作,将每一条数据进行实际的处理,即将每一行处理为单个单词
fileDataSource.flatMap()
需要传入一个接口实现类,我们通过匿名类的方式进行实现
| final FlatMapOperator<String, Tuple2<String, Integer>> wordDatas = fileDataSource.flatMap(
new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception { String[] words = line.split(” “); for (String word : words) { //out.collect(word); // Tuple2表示2个元素的元组 out.collect(new Tuple2<String, Integer>(word, 1)); } } } ); |
我们这里对每一行的数据进行扁平化的处理,在数据中我们规定了返回的数据类型为Tuple,不过我们这里指定了Tuple中包含两个数据,分别为单词和数量
这样我们就将一行按照单词进行了拆分
这就是初始化了一个函数式的对象,然后我们对其进行分组
final UnsortedGrouping<Tuple2<String, Integer>> groupDatas = wordDatas.groupBy(0);
最后进行求和
final AggregateOperator<Tuple2<String, Integer>> result = groupDatas.sum(1);
result就是我们需要的结果
key为单词,value为数量
上面使用的相关api,演示了Flink中的批处理,如果希望使用流处理的话,基本代码将改变如下
只是将基本的环境对象改变为了流处理的对象
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
然后还是去读取文件
DataStreamSource<String> fileDataStreamSource = env.readTextFile(“D:\\idea\\classes\\flink\\data\\word.txt”);
下面的处理的Function仍然不变
| final SingleOutputStreamOperator<Tuple2<String, Integer>> flatDatas = fileDataStreamSource.flatMap(
new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception { String[] words = line.split(” “); for (String word : words) { out.collect(new Tuple2<String, Integer>(word, 1)); } } } ); |
之后的group操作也需要进行修改
final KeyedStream<Tuple2<String, Integer>, Tuple> ksData = flatDatas.keyBy(0);
将其改为了keyBy,以及进行了求和
final SingleOutputStreamOperator<Tuple2<String, Integer>> result = ksData.sum(1);
需要注意,对于Stream环境对象,需要在最后开启处理操作
Env.execute(“wordcount”),其中的wordCount,标明为任务名称
不过这样本质上还是执行一个批处理的操作,对于流数据的操作,我们可以将datasource尝试修改一下
DataStreamSource<String> fileDataStreamSource = env.socketTextStream(“localhost”, 8888);
这样利用Socket通信模拟流数据的操作,其他的代码仍然不变
不过上述这样,我们终究是在本地执行,这样在本地运行的代码一般是用于测试,真正的Flink的运行则需要考虑在服务器上进行运行,那么我们先以在local环境上运行一个Flink为示例,进行测试
首先需要在服务器上准备好相关的Flink集群
在服务器下解压缩Flink相关压缩包, flink-1.13.1-bin-scala_2.12.tgz
然后修改其中/conf目录下的flink-conf.yaml,为了方便测试我们其他的配置参数不进行修改,而且cluster中只存在一个task manager即可,但为了模拟并发,我们将每个TaskManager下的slot设置为两个
taskmanager.numberOfTaskSlots: 2
接下来启动Flink本地环境即可
Start-cluster.sh
对于是否有所启动,我们可以使用浏览器访问服务器的8081端口,查看页面监控
在对应的页面之中,也可以进行任务的提交
说完了简单的使用Flink,我们需要了解Flink中非常重要的一个概念,Slot,Slot和整个任务的并行度有关。
而在此之前,我们说下Flink运行的整体流程
Flink中数据的转换大致可以分为三类

首先是数据源,Source,表明数据的来源,其次是Transformatior,表明着data转换的一系列操作,然后是sink,输出出去
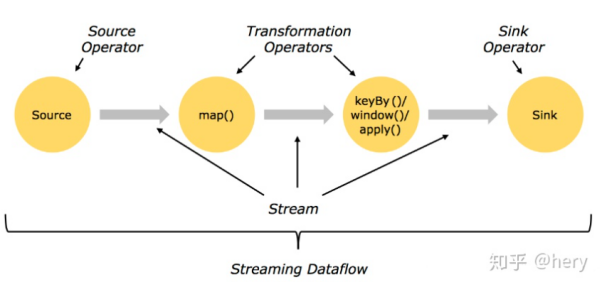
将所有在整体形成上面一个DataFlow,一个有向无环图(DAG),在DataFlow中更加细化的分为了Stream-Partition和Subtask
Stream-partition 是虚拟的逻辑分区,subtask对应的是执行Operator的Thread
一个Operator能实际出现多少个Thread是由并行度控制的
总结一下,Stream-partition是描述数据被分片的情况,Operator-subtask是描述线程并行的情况
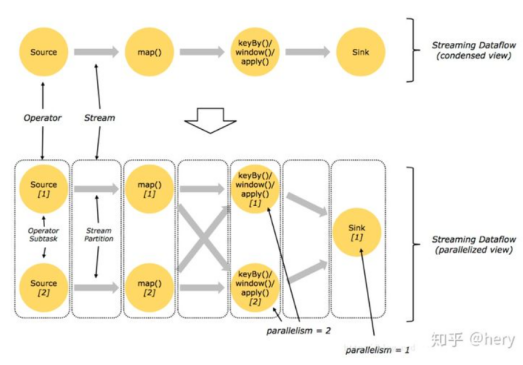
整体的数据传输也分为了两个模式,Forwarding和Redistributing模式
1,Forwarding是Stream之间一对一,父子Stream个数和元素顺序一致,也因为分区个数和元素顺序都不变,可以进行优化,比如讲source和map优化为一个TaskChain,交给一个subTask进行执行.
对应上图,就可以分为两个Thread,分别为source-map,ketBy-windows这两个Thread
2.Redistributing模式是指的Stream-Partition之间多对多的传输,stream传输过程中,Partition进行了Shuffer操作,这样分区个数和元素顺序就打乱了,不过同样Task-chain也打乱了
上面我们也说了subtask-chain的概念,将一个可以放在一起的subtask放在一起交由多个thread执行,提高运行效率
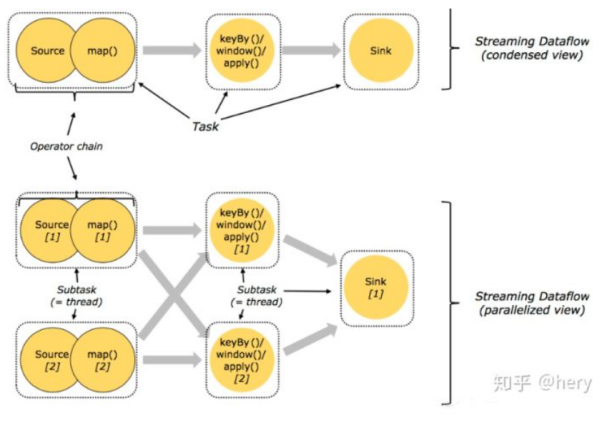
原本需要7个Thread的任务在进行Chain优化后,5个Thread就能更好的完成
最后就是Slot和parallelism的关系
Slot的概念我们说过,是整个Flink中最小的计算单元,而且我们在启动的时候,也在配置文件中配置了对应的数量
taskManager:numberOfTaskSlots:3
这个并行度就是程序执行的时候可以同时执行的任务数量
可以设置的方式,首先是flink-conf.yaml下的设置,默认为1
parallelism.default: 1
或者在提交job的时候,通过-p参数来控制
bin/flink run -p 10 xxxx.jar
以及在程序中,为env设置一个总的并行度
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(8); // 设置并行度为8
以及为计算算子进行灵活的并行度控制,每个算子后面进行并行度的控制
val env =ExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)
val data = env.fromElements(1,2,3,4)
data.map(x=>x*2).setParallelism(4)
不同的设置方式是有优先级的
是算子大于env大于配置文件
而且,如果配置的并行度超过了Task Manger提供的最大的Slot,程序会抛出异常
而且我们在使用过程中,多线程的读取时候前面其实就是不同的SubTask
默认SubTask也就是并行度,如果是local环境,是设置的虚拟cpu个数个的