我们之前使用了kubeadm来部署了一个集群,使用kubeadm使用docker的方式去安装了kube-apiserver,kube-proxy,kubelet,利用了容器的方式,其实就是容器in容器,会导致启动慢,集群恢复慢的问题
更加健壮的方式是二进制的安装,其核心组件是Linux的服务,所以伴随着Linux再启动,一般启动会更快
这一次,我们搭建一个多主多从的集群,并且利用VPC管理内部网络,并且只暴露一个公网IP,利用这个公网IP进行网络转发,从而暴露80和443端口,以及不同后台服务器的22端口
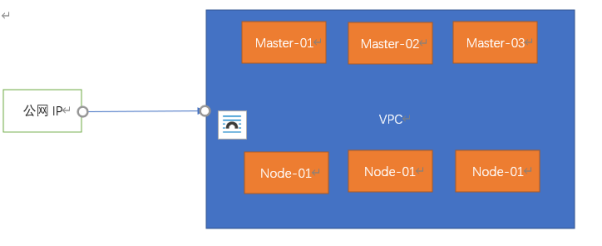
那么我们就在云上提前创建好对应的服务器,以及VPC,和安全组策略
将公网IP的不同端口,比如12306转发给内网192.169.10.10的22端口从而做到限制
之后我们考虑高可用问题
如果是一个无状态的服务代码,那么相同的业务代码部署直接部署多个,即可做到高可用
比如下面
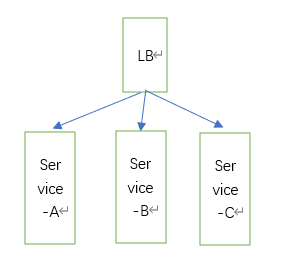
但是对于一个存储集群,就不能只这样了
因为要考虑到实际落盘的问题,比如MySql,如果我们直接搭建多个MySql来做,那么会出现多个MySql之间数据不一致的问题
如果加上一个共享存储
那么所有的mysql都连上这个共享存储,那么也可以
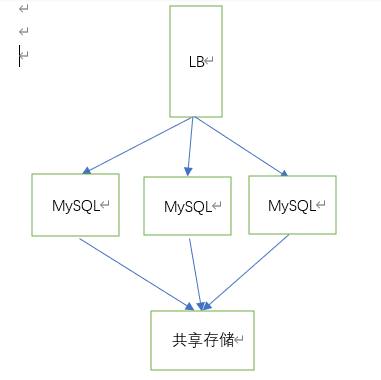
这样传输的速度其实就限制在了网络速度,以及网卡速度
但是这种数据的读取方式并不完美,可能出现脏数据的问题
比较完美的方式就是我们先挂载本地的磁盘存储,同时在同步到网络存储中,并且mysql进行彼此的主从同步,或者搭建多主的集群
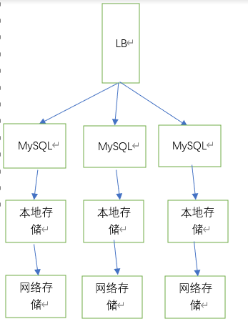
那么我们说回K8S的高可用集群
一般其架构为master+node
Master一旦宕机,K8S就不再是可用的状态,但是node还可能可以提供服务
而无论Master还是Node,都是无状态的服务,因为所有的数据最终都是保存在etcd集群的,只有etcd是有状态应用
而ETCD是在CAP中保证了AP性,即保证了 可用性和 分区容错性
关于ETCD的分布式协议,采用了Raft作为一致性协议
关于,Raft协议,之前有过讲了,这里就先不说了
而在K8S集群之中
最终的会形成,由etcd集群去联系各个master上的apiServer
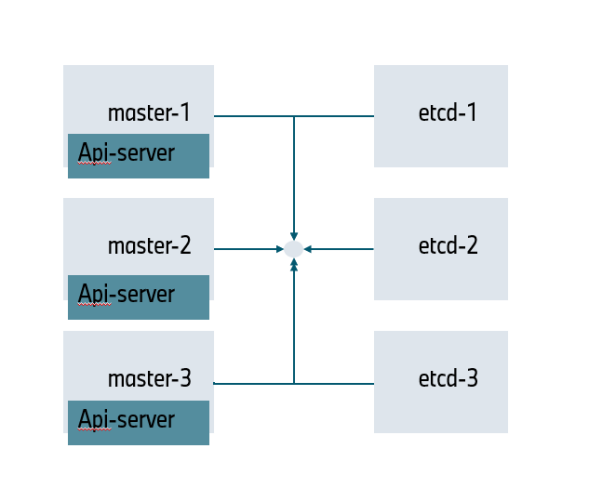
这样就做到了无状态服务和有状态服务之间的交互
无论访问哪一个master节点,最终都可以将数据保存在Etcd中
而集群内部的交互,即node和master,是利用负载均衡将master集群暴露于一个负载均衡上,毕竟是无状态的服务,从而让node和master进行交互
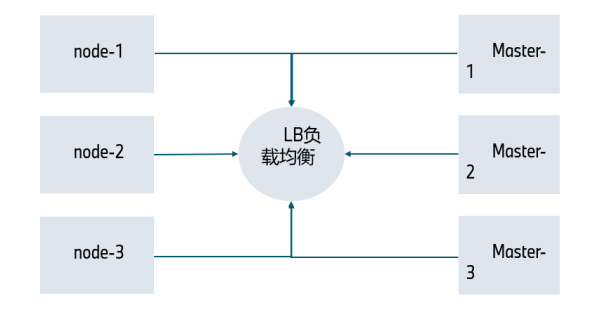
这样保证了无状态服务和无状态服务的对接
那么整体架构说完了,我们该考虑如何搭建整个集群,而无论master->etcd,还是node->master
都需要对应的认证信息
也就是彼此通信,需要证书进行认证,正是需要一套完整的公私秘钥
将自己的私钥进行保存,将公钥交付出去
不仅如此,我们在交互过程中,需要涉及背书的问题,需要搭建一个CA认证机构,需要进行搭建
对应到上面,就是需要两个CA,分别是API-server和etcd交互CA
和其他组件与api-server交互的CA
那么我们首先就需要生成一些对应的证书
分别为client certificate 用于让服务器来认证客户端,比如etcdctl etcd proxy fleetctl docker客户端
Server certificate 服务端使用,客户端以此来验证服务端身份,比如docker服务端,kube-apiserver
Peer certificate 双向证书,用于etcd之间的集群通信
那么证书发出来的需要经历的步骤为
首先需要有一个证书颁发机构
然后提交证书申请给CA,去获取颁发的证书
我们这里使用cfssl作为我们的证书颁发机构
首先是需要去安装cfssl这个服务
首先去官网下载cfssl-cretinfo_linux-amd64 cfssljson_linux-amd64 cfssl_linux-amd64
分别wget
然后授予全部的cfssl
Chmode +x cfssl*
批量重命名
For name in `ls cfssl`; do mv $name ${name%_1.5.0_linux_amd64}; done
移动文件到 /user/bin
Mv cfssl* /user/bin
然后是基本的使用 cfssl print-defaults 来打印请求ca的模板
然后cfssl print-defaults config来打印全局配置的模板
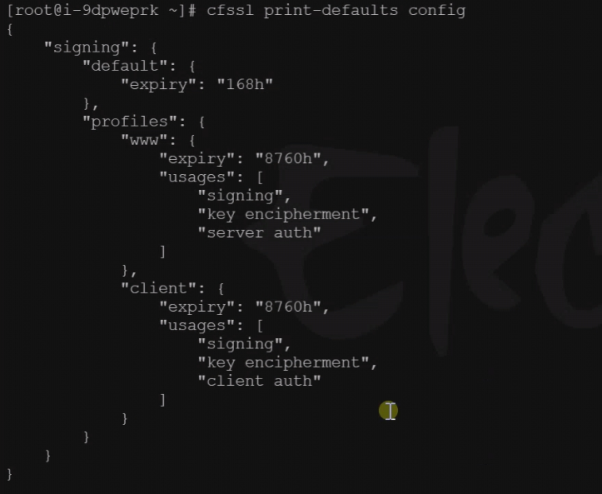
Cfssl print-defaults csr

就是一个提交修改的请求
具体的证书生成在我们实际进行部署过程中我们实际操作下
首先我们明确各个节点的网络范围
192.168.0.x 为机器的网段
10.96..0.0/16 为Service网段
196.16.0.0/16 为Pod网段
然后为集群进行规定域名
Hostnamectl set-hostname k8s-xxx
然后分别在每个机器的host文件中写入对应的ip和hostname
vi /etc/hosts
192.168.0.10 k8s-master1
192.168.0.11 k8s-master2
192.168.0.12 k8s-master3
192.168.0.13 k8s-node1
192.168.0.14 k8s-node2
192.168.0.15 k8s-node3
192.168.0.250 k8s-master-lb # 非高可用,可以不用这个。这个使用keepalive配置
之后就是关闭selinux
Setenforce 0
setenforce 0
sed -i ‘s#SELINUX=enforcing#SELINUX=disabled#g’ /etc/sysconfig/selinux
sed -i ‘s#SELINUX=enforcing#SELINUX=disabled#g’ /etc/selinux/config
关闭swap
swapoff -a && sysctl -w vm.swappiness=0
sed -ri ‘s/.*swap.*/#&/’ /etc/fstab
修改限制
ulimit -SHn 65535
vi /etc/security/limits.conf
# 末尾添加如下内容
* soft nofile 655360
* hard nofile 131072
* soft nproc 655350
* hard nproc 655350
* soft memlock unlimited
* hard memlock unlimited
配置master-1和其他节点的免密连接
Ssh-keygen -t rsa
然后将公钥拷贝到远端服务器上即可
然后安装一些接下来需要用的工具
yum install wget git jq psmisc net-tools yum-utils device-mapper-persistent-data lvm2 -y
然后是ipvs相关的工具
yum install ipvsadm ipset sysstat conntrack libseccomp -y
之后配置ipvs模块
modprobe — ip_vs
modprobe — ip_vs_rr
modprobe — ip_vs_wrr
modprobe — ip_vs_sh
modprobe — nf_conntrack
并且修改ipvs的配置,加入一些配置
vi /etc/modules-load.d/ipvs.conf
ip_vs
ip_vs_lc
ip_vs_wlc
ip_vs_rr
ip_vs_wrr
ip_vs_lblc
ip_vs_lblcr
ip_vs_dh
ip_vs_sh
ip_vs_fo
ip_vs_nq
ip_vs_sed
ip_vs_ftp
ip_vs_sh
nf_conntrack
ip_tables
ip_set
xt_set
ipt_set
ipt_rpfilter
ipt_REJECT
ipip
然后配置ipv4的问题
## 所有节点
cat <<EOF > /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
fs.may_detach_mounts = 1
vm.overcommit_memory=1
net.ipv4.conf.all.route_localnet = 1
vm.panic_on_oom=0
fs.inotify.max_user_watches=89100
fs.file-max=52706963
fs.nr_open=52706963
net.netfilter.nf_conntrack_max=2310720
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl =15
net.ipv4.tcp_max_tw_buckets = 36000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_max_orphans = 327680
net.ipv4.tcp_orphan_retries = 3
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 16768
net.ipv4.ip_conntrack_max = 65536
net.ipv4.tcp_timestamps = 0
net.core.somaxconn = 16768
EOF
sysctl –system
之后重启下机器,检测内核配置是否正确
reboot
lsmod | grep -e ip_vs -e nf_conntrack
然后我们进行K8S的集群搭建
首先需要安装docker,分别提供了在线版和离线版的安装方式
yum remove docker*
yum install -y yum-utils
yum-config-manager –add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce-19.03.9 docker-ce-cli-19.03.9 containerd.io-1.4.4
http://mirrors.aliyun.com/docker-ce/linux/centos/7.9/x86_64/stable/Packages/
yum localinstall xxxx
安装完成之后准备相关的证书生成
K8S中的证书,kubelet需要客户端证书来进行服务器身份
API服务器端点的证书
API服务器的客户端证书,和kubelet会话使用
API服务器的客户端的证书,和etcd会话使用
控制器管理器的证书和API服务器通话
调度器的证书需要和API服务器通话
Etcd集群内部还需要证书进行彼此的通信
首先我们安装cfssl
wget https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl-certinfo_1.5.0_linux_amd64
wget https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl_1.5.0_linux_amd64
wget https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssljson_1.5.0_linux_amd64
然后授予权限
Chmod +x cfssl
重命名
for name in `ls cfssl*`; do mv $name ${name%_1.5.0_linux_amd64}; done
并且移动到mv cfssl* /usr/bin
之后我们创建一个配置文件
mkdir -p /etc/kubernetes/pki
cd /etc/kubernetes/pki
vi ca-config.json
|
{
“signing”: { “default”: { “expiry”: “87600h” }, “profiles”: { “server”: { “expiry”: “87600h”, “usages”: [ “signing”, “key encipherment”, “server auth” ] }, “client”: { “expiry”: “87600h”, “usages”: [ “signing”, “key encipherment”, “client auth” ] }, “peer”: { “expiry”: “87600h”, “usages”: [ “signing”, “key encipherment”, “server auth”, “client auth” ] }, “kubernetes”: { “expiry”: “87600h”, “usages”: [ “signing”, “key encipherment”, “server auth”, “client auth” ] }, “etcd”: { “expiry”: “87600h”, “usages”: [ “signing”, “key encipherment”, “server auth”, “client auth” ] } } } } |
上面配置了不同profile下的过期时间,以及相关认证方式
然后我们就可以先搭建一个高可用的etcd集群了
首先是搭建一个etcd的集群,关于集群的范围,可以参考如下的建议
https://etcd.io/docs/v3.4/op-guide/hardware/
关于安装方式参考如下
https://etcd.io/docs/v3.4/install/
我们直接下载etcd
wget https://github.com/etcd-io/etcd/releases/download/v3.4.16/etcd-v3.4.16-linux-amd64.tar.gz
发送etcd的包部署高可用
for i in k8s-master1 k8s-master2 k8s-master3;do scp etcd-* root@$i:/root/;done
解压到/usr/local/bin
tar -zxvf etcd-v3.4.16-linux-amd64.tar.gz –strip-components=1 -C /usr/local/bin etcd-v3.4.16-linux-amd64/etcd{,ctl}
尝试验证etcd
只需要输入etcdctl即可
然后准备etcd的证书
首先我们需要一个CA证书进行背书
这样我们需要生成CA,首先准备一个CA.json
|
{
“CN”: “etcd”, “key”: { “algo”: “rsa”, “size”: 2048 }, “names”: [ { “C”: “CN”, “ST”: “Beijing”, “L”: “Beijing”, “O”: “etcd”, “OU”: “etcd” } ], “ca”: { “expiry”: “87600h” } } |
生成etcd的ca证书
{
“CN”: “etcd”,
“key”: {
“algo”: “rsa”,
“size”: 2048
},
“names”: [
{
“C”: “CN”,
“ST”: “Beijing”,
“L”: “Beijing”,
“O”: “etcd”,
“OU”: “etcd”
}
],
“ca”: {
“expiry”: “87600h”
}
}
上面我们声明了一个ca的请求json
其中CN表明为公用名,可以为网站域
O代表组织名,一般公网上的证书中是政府登记的企业名称
OU 单位部门,一般直接填IT
C是城市
ST是单位所在省份
C是国家名称
然后我们创建CA证书和密钥
cfssl gencert -initca etcd-ca-csr.json | cfssljson -bare /etc/kubernetes/pki/etcd/ca –
# ca.csr ca.pem(ca公钥) ca-key.pem(ca私钥,妥善保管)
然后创建一个有背书的公私钥
|
{
“CN”: “etcd-itdachang”, “key”: { “algo”: “rsa”, “size”: 2048 }, “hosts”: [ “127.0.0.1”, “k8s-master1”, “k8s-master2”, “k8s-master3”, “192.168.0.10”, “192.168.0.11”, “192.168.0.12” ], “names”: [ { “C”: “CN”, “L”: “beijing”, “O”: “etcd”, “ST”: “beijing”, “OU”: “System” } ] } |
其中hosts声明了可以访问的地址
其他和上面的说的一致
然后由之前创建的ca签发这个新的证书
cfssl gencert \
-ca=/etc/kubernetes/pki/etcd/ca.pem \
-ca-key=/etc/kubernetes/pki/etcd/ca-key.pem \
-config=/etc/kubernetes/pki/ca-config.json \
-profile=etcd \
etcd-itdachang-csr.json | cfssljson -bare /etc/kubernetes/pki/etcd/etcd
并将创建好的etcd证书,复制给其他的机器
for i in k8s-master2 k8s-master3;do scp -r /etc/kubernetes/pki/etcd root@$i:/etc/kubernetes/pki;done
然后就是对应的启动,不过启动需要对应的配置文件
所以我们需要在不同主机上创建好配置文件
mkdir -p /etc/etcd
vi /etc/etcd/etcd.yaml
|
name: ‘etcd-master3’ #每个机器可以写自己的域名,不能重复
data-dir: /var/lib/etcd wal-dir: /var/lib/etcd/wal snapshot-count: 5000 heartbeat-interval: 100 election-timeout: 1000 quota-backend-bytes: 0 listen-peer-urls: ‘https://192.168.0.12:2380’ # 本机ip+2380端口,代表和集群通信 listen-client-urls: ‘https://192.168.0.12:2379,http://127.0.0.1:2379’ #改为自己的 max-snapshots: 3 max-wals: 5 cors: initial-advertise-peer-urls: ‘https://192.168.0.12:2380’ #自己的ip advertise-client-urls: ‘https://192.168.0.12:2379’ #自己的ip discovery: discovery-fallback: ‘proxy’ discovery-proxy: discovery-srv: initial-cluster: ‘etcd-master1=https://192.168.0.10:2380,etcd-master2=https://192.168.0.11:2380,etcd-master3=https://192.168.0.12:2380’ #这里不一样 initial-cluster-token: ‘etcd-k8s-cluster’ initial-cluster-state: ‘new’ strict-reconfig-check: false enable-v2: true enable-pprof: true proxy: ‘off’ proxy-failure-wait: 5000 proxy-refresh-interval: 30000 proxy-dial-timeout: 1000 proxy-write-timeout: 5000 proxy-read-timeout: 0 client-transport-security: cert-file: ‘/etc/kubernetes/pki/etcd/etcd.pem’ key-file: ‘/etc/kubernetes/pki/etcd/etcd-key.pem’ client-cert-auth: true trusted-ca-file: ‘/etc/kubernetes/pki/etcd/ca.pem’ auto-tls: true peer-transport-security: cert-file: ‘/etc/kubernetes/pki/etcd/etcd.pem’ key-file: ‘/etc/kubernetes/pki/etcd/etcd-key.pem’ peer-client-cert-auth: true trusted-ca-file: ‘/etc/kubernetes/pki/etcd/ca.pem’ auto-tls: true debug: false log-package-levels: log-outputs: [default] force-new-cluster: false |
然后就可以启动Etcd了
不过我们建议将Etcd设置为了开机自启
|
vi /usr/lib/systemd/system/etcd.service
[Unit] Description=Etcd Service Documentation=https://etcd.io/docs/v3.4/op-guide/clustering/ After=network.target [Service] Type=notify ExecStart=/usr/local/bin/etcd –config-file=/etc/etcd/etcd.yaml Restart=on-failure RestartSec=10 LimitNOFILE=65536 [Install] WantedBy=multi-user.target Alias=etcd3.service |
然后就可以设置开机自启动了
Systemctl daemon-reload
Systemctl enable –now etcd
然后查看集群状态无误之后就可以测试集群的使用了,这里我们推荐提前配置好环境变量
|
export ETCDCTL_API=3
HOST_1=192.168.0.10 HOST_2=192.168.0.11 HOST_3=192.168.0.12 ENDPOINTS=$HOST_1:2379,$HOST_2:2379,$HOST_3:2379 ## 导出环境变量,方便测试,参照https://github.com/etcd-io/etcd/tree/main/etcdctl export ETCDCTL_DIAL_TIMEOUT=3s export ETCDCTL_CACERT=/etc/kubernetes/pki/etcd/ca.pem export ETCDCTL_CERT=/etc/kubernetes/pki/etcd/etcd.pem export ETCDCTL_KEY=/etc/kubernetes/pki/etcd/etcd-key.pem export ETCDCTL_ENDPOINTS=$HOST_1:2379,$HOST_2:2379,$HOST_3:2379 |
Etcdctl member list –write-out=table
之后就该是K8S相关的安装了,我们这一次使用二进制的安装方式,就需要对应的离线安装包
在github中
https://github.com/kubernetes/kubernetes 找到changelog对应版本
在对应版本的md中,存在着二进制压缩包的下载地址
https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.24.md

下载好对应的gz压缩包之后,将这个压缩包复制给其他节点
| for i in k8s-master1 k8s-master2 k8s-master3 k8s-node1 k8s-node2 k8s-node3;do scp kubernetes-server-* root@$i:/root/;done |
并且将压缩包中的内容解压到/usr/local/bin
| tar -xvf kubernetes-server-linux-amd64.tar.gz –strip-components=3 -C /usr/local/bin kubernetes/server/bin/kube{let,ctl,-apiserver,-controller-manager,-scheduler,-proxy} |
之后是证书的生成
首先是用于串联全局,串联内外的api-server
对于这一个组件,之后是需要单独的部署在负载均衡上的,所以我们先只生成证书
仍然是需要一个CA证书
vi ca-csr.json
{
“CN”: “kubernetes”,
“key”: {
“algo”: “rsa”,
“size”: 2048
},
“names”: [
{
“C”: “CN”,
“ST”: “Beijing”,
“L”: “Beijing”,
“O”: “Kubernetes”,
“OU”: “Kubernetes”
}
],
“ca”: {
“expiry”: “87600h”
}
}
cfssl gencert -initca ca-csr.json | cfssljson -bare ca –
然后声明一个CA颁发的请求
|
{
“CN”: “kube-apiserver”, “hosts”: [ “10.96.0.1”, “127.0.0.1”, “192.168.0.250”, “192.168.0.10”, “192.168.0.11”, “192.168.0.12”, “192.168.0.13”, “192.168.0.14”, “192.168.0.15”, “192.168.0.16”, “kubernetes”, “kubernetes.default”, “kubernetes.default.svc”, “kubernetes.default.svc.cluster”, “kubernetes.default.svc.cluster.local” ], “key”: { “algo”: “rsa”, “size”: 2048 }, “names”: [ { “C”: “CN”, “L”: “BeiJing”, “ST”: “BeiJing”, “O”: “Kubernetes”, “OU”: “Kubernetes” } ] } |
需要注意的是,CA中不支持声明网段,所以还请在声明的时候依次填入ip
cfssl gencert -ca=/etc/kubernetes/pki/ca.pem -ca-key=/etc/kubernetes/pki/ca-key.pem -config=/etc/kubernetes/pki/ca-config.json -profile=kubernetes apiserver-csr.json | cfssljson -bare /etc/kubernetes/pki/apiserver
这样就在kubernetes下声明了一个ca机构,以及在/Kubernetes/apiserver下声明了api-server的CA证书
其次是front-proxy的证书生成,这个组件是由于CRD,自定义资源类型支持的组件
这里的证书请求可以使用上面的统一CA机构,也可以使用一个新的CA机构,如果是使用新的CA机构,那么需要在api-server引导的时候声明配置
–requestheader-allowed-names=front-proxy-client
那么我们就假设生成一个新的CA机构
|
vi front-proxy-ca-csr.json
{ “CN”: “kubernetes”, “key”: { “algo”: “rsa”, “size”: 2048 } } |
然后初始化这个CA机构
cfssl gencert -initca front-proxy-ca-csr.json | cfssljson -bare /etc/kubernetes/pki/front-proxy-ca
然后申请一个CA证书的颁发
|
{
“CN”: “front-proxy-client”, “key”: { “algo”: “rsa”, “size”: 2048 } } |
cfssl gencert -ca=/etc/kubernetes/pki/front-proxy-ca.pem -ca-key=/etc/kubernetes/pki/front-proxy-ca-key.pem -config=ca-config.json -profile=kubernetes front-proxy-client-csr.json | cfssljson -bare /etc/kubernetes/pki/front-proxy-client
之后就不再是简单的证书生成了,而是需要生成一些集群需要的配置
首先是controller-manager的配置
第一步仍然是生成一个CA证书
|
{
“CN”: “system:kube-controller-manager”, “key”: { “algo”: “rsa”, “size”: 2048 }, “names”: [ { “C”: “CN”, “ST”: “Beijing”, “L”: “Beijing”, “O”: “system:kube-controller-manager”, “OU”: “Kubernetes” } ] } |
然后生成对应的证书
cfssl gencert \
-ca=/etc/kubernetes/pki/ca.pem \
-ca-key=/etc/kubernetes/pki/ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
controller-manager-csr.json | cfssljson -bare /etc/kubernetes/pki/controller-manager
然后是生成一个配置
|
#1.声明了集群的配置项
kubectl config set-cluster kubernetes \ –certificate-authority=/etc/kubernetes/pki/ca.pem \ –embed-certs=true \ –server=https://192.168.0.250:6443 \ #这是声明的集群负载均衡 –kubeconfig=/etc/kubernetes/controller-manager.conf #2.环境项,和上下文的配置项 kubectl config set-context system:kube-controller-manager@kubernetes \ –cluster=kubernetes \ –user=system:kube-controller-manager \ –kubeconfig=/etc/kubernetes/controller-manager.conf #3.设置用户项,对应上面的用户 kubectl config set-credentials system:kube-controller-manager \ –client-certificate=/etc/kubernetes/pki/controller-manager.pem \ –client-key=/etc/kubernetes/pki/controller-manager-key.pem \ –embed-certs=true \ –kubeconfig=/etc/kubernetes/controller-manager.conf #4. 使用环境作为默认环境 kubectl config use-context system:kube-controller-manager@kubernetes \ –kubeconfig=/etc/kubernetes/controller-manager.conf |
之后是scheduler的证书生成及配置
|
vi scheduler-csr.json
{ “CN”: “system:kube-scheduler”, “key”: { “algo”: “rsa”, “size”: 2048 }, “names”: [ { “C”: “CN”, “ST”: “Beijing”, “L”: “Beijing”, “O”: “system:kube-scheduler”, “OU”: “Kubernetes” } ] } cfssl gencert \ -ca=/etc/kubernetes/pki/ca.pem \ -ca-key=/etc/kubernetes/pki/ca-key.pem \ -config=/etc/kubernetes/pki/ca-config.json \ -profile=kubernetes \ scheduler-csr.json | cfssljson -bare /etc/kubernetes/pki/scheduler |
然后生成配置
|
kubectl config set-cluster kubernetes \
–certificate-authority=/etc/kubernetes/pki/ca.pem \ –embed-certs=true \ –server=https://192.168.0.250:6443 \ –kubeconfig=/etc/kubernetes/scheduler.conf kubectl config set-credentials system:kube-scheduler \ –client-certificate=/etc/kubernetes/pki/scheduler.pem \ –client-key=/etc/kubernetes/pki/scheduler-key.pem \ –embed-certs=true \ –kubeconfig=/etc/kubernetes/scheduler.conf kubectl config set-context system:kube-scheduler@kubernetes \ –cluster=kubernetes \ –user=system:kube-scheduler \ –kubeconfig=/etc/kubernetes/scheduler.conf kubectl config use-context system:kube-scheduler@kubernetes \ –kubeconfig=/etc/kubernetes/scheduler.conf |
之后是生成admin这个角色
|
vi admin-csr.json
{ “CN”: “admin”, “key”: { “algo”: “rsa”, “size”: 2048 }, “names”: [ { “C”: “CN”, “ST”: “Beijing”, “L”: “Beijing”, “O”: “system:masters”, “OU”: “Kubernetes” } ] } cfssl gencert \ -ca=/etc/kubernetes/pki/ca.pem \ -ca-key=/etc/kubernetes/pki/ca-key.pem \ -config=/etc/kubernetes/pki/ca-config.json \ -profile=kubernetes \ admin-csr.json | cfssljson -bare /etc/kubernetes/pki/admin |
然后生成配置
|
kubectl config set-cluster kubernetes \
–certificate-authority=/etc/kubernetes/pki/ca.pem \ –embed-certs=true \ –server=https://192.168.0.250:6443 \ –kubeconfig=/etc/kubernetes/admin.conf kubectl config set-credentials kubernetes-admin \ –client-certificate=/etc/kubernetes/pki/admin.pem \ –client-key=/etc/kubernetes/pki/admin-key.pem \ –embed-certs=true \ –kubeconfig=/etc/kubernetes/admin.conf kubectl config set-context kubernetes-admin@kubernetes \ –cluster=kubernetes \ –user=kubernetes-admin \ –kubeconfig=/etc/kubernetes/admin.conf kubectl config use-context kubernetes-admin@kubernetes \ –kubeconfig=/etc/kubernetes/admin.conf |
这样基本的配置生成就完成
对于kubelet这个组件则是采用其他方式配置,不然一个节点配置一次证书,集群大了不好配置
在证书的最后,集群还需要一对公私钥,这一对是用于在生成K8S内部用户Secret的时候进行加解密的
|
openssl genrsa -out /etc/kubernetes/pki/sa.key 2048
openssl rsa -in /etc/kubernetes/pki/sa.key -pubout -out /etc/kubernetes/pki/sa.pub |
然后将上述的证书全部发到其他的节点上
|
for NODE in k8s-master2 k8s-master3
do for FILE in admin.conf controller-manager.conf scheduler.conf do scp /etc/kubernetes/${FILE} $NODE:/etc/kubernetes/${FILE} done done |
那么我们接下来就是依次配置诸如 api-server controller-manager kubelet kube-proxy这些组件
首先是api-server这个服务
我们需要对应的证书才能在其他的master节点上配置,所以我们需要将所有的节点上拷贝证书
首先确认各个master节点上的 usr/local/bin已经有了api-server
首先需要准备一个配置文件
|
[Unit]
Description=Kubernetes API Server Documentation=https://github.com/kubernetes/kubernetes After=network.target [Service] ExecStart=/usr/local/bin/kube-apiserver \ –v=2 \ –logtostderr=true \ –allow-privileged=true \ –bind-address=0.0.0.0 \ –secure-port=6443 \ –insecure-port=0 \ –advertise-address=192.168.0.10 \ –service-cluster-ip-range=10.96.0.0/16 \ –service-node-port-range=30000-32767 \ –etcd-servers=https://192.168.0.10:2379,https://192.168.0.11:2379,https://192.168.0.12:2379 \ –etcd-cafile=/etc/kubernetes/pki/etcd/ca.pem \ –etcd-certfile=/etc/kubernetes/pki/etcd/etcd.pem \ –etcd-keyfile=/etc/kubernetes/pki/etcd/etcd-key.pem \ –client-ca-file=/etc/kubernetes/pki/ca.pem \ –tls-cert-file=/etc/kubernetes/pki/apiserver.pem \ –tls-private-key-file=/etc/kubernetes/pki/apiserver-key.pem \ –kubelet-client-certificate=/etc/kubernetes/pki/apiserver.pem \ –kubelet-client-key=/etc/kubernetes/pki/apiserver-key.pem \ –service-account-key-file=/etc/kubernetes/pki/sa.pub \ –service-account-signing-key-file=/etc/kubernetes/pki/sa.key \ –service-account-issuer=https://kubernetes.default.svc.cluster.local \ –kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname \ –enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,ResourceQuota \ –authorization-mode=Node,RBAC \ –enable-bootstrap-token-auth=true \ –requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \ –proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.pem \ –proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client-key.pem \ –requestheader-allowed-names=aggregator,front-proxy-client \ –requestheader-group-headers=X-Remote-Group \ –requestheader-extra-headers-prefix=X-Remote-Extra- \ –requestheader-username-headers=X-Remote-User # –token-auth-file=/etc/kubernetes/token.csv Restart=on-failure RestartSec=10s LimitNOFILE=65535 [Install] WantedBy=multi-user.target |
上面配置中需要注意,上面的advertise-address 需要改为本master节点的ip
比如master-2上就需要配置master-2的的ip
其次是service-cluster-ip-range=10.96.0.0/16,这是我们需要配置的service的网段
还有就是etcd-server,修改为自己的ectd-server的所有地址
之后就可以启动api-server了
systemctl daemon-reload && systemctl enable –now kube-apiserver
然后查看对应的状态
Systemctl status kube-apiserver
而且由于我们是高可用集群,所以我们需要设置一个LoadBalancer,在对应的云厂商创建一个,去代理所有master节点上的6443端点即可
然后配置controller-manager的服务
仍然需要给master节点配置kube-controller-manager
书写一个service文件
vi /usr/lib/systemd/system/kube-controller-manager.service
|
[Unit]
Description=Kubernetes Controller Manager Documentation=https://github.com/kubernetes/kubernetes After=network.target [Service] ExecStart=/usr/local/bin/kube-controller-manager \ –v=2 \ –logtostderr=true \ –address=127.0.0.1 \ –root-ca-file=/etc/kubernetes/pki/ca.pem \ –cluster-signing-cert-file=/etc/kubernetes/pki/ca.pem \ –cluster-signing-key-file=/etc/kubernetes/pki/ca-key.pem \ –service-account-private-key-file=/etc/kubernetes/pki/sa.key \ –kubeconfig=/etc/kubernetes/controller-manager.conf \ –leader-elect=true \ –use-service-account-credentials=true \ –node-monitor-grace-period=40s \ –node-monitor-period=5s \ –pod-eviction-timeout=2m0s \ –controllers=*,bootstrapsigner,tokencleaner \ –allocate-node-cidrs=true \ –cluster-cidr=196.16.0.0/16 \ –requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \ –node-cidr-mask-size=24 Restart=always RestartSec=10s [Install] WantedBy=multi-user.target |
上面的书写中,声明了相关证书,其次是声明了Pod的网段
也就是-cluster-cidr=196.16.0.0/16
之后就是设置启动了
Systemctl daemon-reload && systemctl enable –now kube-controller-manager
Systemctl status kube-controller-manager
其次是所有master节点上配置的kube-scheduler.service
仍然需要书写一个service文件
vi /usr/lib/systemd/system/kube-scheduler.service
内部内容为
|
[Unit]
Description=Kubernetes Scheduler Documentation=https://github.com/kubernetes/kubernetes After=network.target [Service] ExecStart=/usr/local/bin/kube-scheduler \ –v=2 \ –logtostderr=true \ –address=127.0.0.1 \ –leader-elect=true \ –kubeconfig=/etc/kubernetes/scheduler.conf Restart=always RestartSec=10s [Install] WantedBy=multi-user.target |
然后启动这个scheduler
systemctl daemon-reload && systemctl enable –now kube-scheduler
systemctl status kube-scheduler
上面的service都是master节点上必须的,而剩下的服务都是需要在node节点上也配置的,例如kubelet和kube-proxy
首先是kubelet
Kublet是进行TLS引导启动的,对应官网上的地址为
https://kubernetes.io/zh/docs/reference/command-line-tools-reference/kubelet-tls-bootstrapping/
整个流程如下
|
kubelet 启动
kubelet 看到自己 没有 对应的 kubeconfig 文件 kubelet 搜索并发现 bootstrap-kubeconfig 文件 kubelet 读取该启动引导文件,从中获得 API 服务器的 URL 和用途有限的 一个“令牌(Token)” kubelet 建立与 API 服务器的连接,使用上述令牌执行身份认证 kubelet 现在拥有受限制的凭据来创建和取回证书签名请求(CSR) kubelet 为自己创建一个 CSR,并将其 signerName 设置为 kubernetes.io/kube-apiserver-client-kubelet CSR 被以如下两种方式之一批复: 如果配置了,kube-controller-manager 会自动批复该 CSR 如果配置了,一个外部进程,或者是人,使用 Kubernetes API 或者使用 kubectl 来批复该 CSR kubelet 所需要的证书被创建 证书被发放给 kubelet kubelet 取回该证书 kubelet 创建一个合适的 kubeconfig,其中包含密钥和已签名的证书 kubelet 开始正常操作 可选地,如果配置了,kubelet 在证书接近于过期时自动请求更新证书 更新的证书被批复并发放;取决于配置,这一过程可能是自动的或者手动完成 |
上面需要我们配置好一个bootstrap-kubeconfig文件
这样我们准备一个随机token,方便Node的kubelet根据token换取秘钥
head -c 8 /dev/urandom | od -An -t x | tr -d ‘ ‘
|
kubectl config set-cluster kubernetes \
–certificate-authority=/etc/kubernetes/pki/ca.pem \ –embed-certs=true \ –server=https://192.168.0.250:6443 \ –kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf kubectl config set-credentials tls-bootstrap-token-user \ –token=l6fy8c.d683399b7a553977 \ –kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf #设置上下文 kubectl config set-context tls-bootstrap-token-user@kubernetes \ –cluster=kubernetes \ –user=tls-bootstrap-token-user \ –kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf #使用设置 kubectl config use-context tls-bootstrap-token-user@kubernetes \ –kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf |
上面生成了conf文件之后
就可以考虑给node节点上配置kubelet了,不过首先还是给master节点上配置一个具有admin权限的kubectl
在上面的官方引导教程中说了, kubectl能不能执行看的是/root/.kube下有没有config文件
而这个config其实就是admin,conf,我们只需要改下名字
mkdir -p /root/.kube ;
cp /etc/kubernetes/admin.conf /root/.kube/config
kubectl get nodes就可以尝试调用集群资源了
然后我们准备一个集群引导权限文件
在具有admin权限的master节点上准备一个secret.yaml
|
apiVersion: v1
kind: Secret metadata: name: bootstrap-token-l6fy8c namespace: kube-system type: bootstrap.kubernetes.io/token stringData: description: “The default bootstrap token generated by ‘kubelet ‘.” token-id: l6fy8c token-secret: d683399b7a553977 usage-bootstrap-authentication: “true” usage-bootstrap-signing: “true” auth-extra-groups: system:bootstrappers:default-node-token,system:bootstrappers:worker,system:bootstrappers:ingress — apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: kubelet-bootstrap roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:node-bootstrapper subjects: – apiGroup: rbac.authorization.k8s.io kind: Group name: system:bootstrappers:default-node-token — apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: node-autoapprove-bootstrap roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:certificates.k8s.io:certificatesigningrequests:nodeclient subjects: – apiGroup: rbac.authorization.k8s.io kind: Group name: system:bootstrappers:default-node-token — apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: node-autoapprove-certificate-rotation roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:certificates.k8s.io:certificatesigningrequests:selfnodeclient subjects: – apiGroup: rbac.authorization.k8s.io kind: Group name: system:nodes — apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: “true” labels: kubernetes.io/bootstrapping: rbac-defaults name: system:kube-apiserver-to-kubelet rules: – apiGroups: – “” resources: – nodes/proxy – nodes/stats – nodes/log – nodes/spec – nodes/metrics verbs: – “*” — apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: system:kube-apiserver namespace: “” roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:kube-apiserver-to-kubelet subjects: – apiGroup: rbac.authorization.k8s.io kind: User name: kube-apiserver |
并且应用这个资源
Kubectl apply -f /etc/kubernetes/bootstrap.secret.yaml
至于其他的Node及诶单
首先需要我们将conf和令牌以及执行文件发送到各个node上
诸如:
for NODE in k8s-master2 k8s-master3 k8s-node3 k8s-node1 k8s-node2; do
scp -r /etc/kubernetes/* root@$NODE:/etc/kubernetes/
done
创建相关的目录
mkdir -p /var/lib/kubelet /var/log/kubernetes /etc/systemd/system/kubelet.service.d /etc/kubernetes/manifests/
然后创建一个kubelet服务
|
vi /usr/lib/systemd/system/kubelet.service
[Unit] Description=Kubernetes Kubelet Documentation=https://github.com/kubernetes/kubernetes After=docker.service Requires=docker.service [Service] ExecStart=/usr/local/bin/kubelet Restart=always StartLimitInterval=0 RestartSec=10 [Install] WantedBy=multi-user.target |
然后给kubelet服务创建一个配置文件
需要在10-kubelet.conf中创建
|
vi /etc/systemd/system/kubelet.service.d/10-kubelet.conf
[Service] Environment=”KUBELET_KUBECONFIG_ARGS=–bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf –kubeconfig=/etc/kubernetes/kubelet.conf” Environment=”KUBELET_SYSTEM_ARGS=–network-plugin=cni –cni-conf-dir=/etc/cni/net.d –cni-bin-dir=/opt/cni/bin” Environment=”KUBELET_CONFIG_ARGS=–config=/etc/kubernetes/kubelet-conf.yml –pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/pause:3.4.1″ Environment=”KUBELET_EXTRA_ARGS=–node-labels=node.kubernetes.io/node=” ” ExecStart= ExecStart=/usr/local/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_SYSTEM_ARGS $KUBELET_EXTRA_ARGS |
然后配置一个kubelet的confi文件
Vi /etc/Kubernetes/kubelet-conf.yml
需要注意下面的clusterDNS需要设置为之前设置的api-server中service网段的第10个ip
|
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration address: 0.0.0.0 port: 10250 readOnlyPort: 10255 authentication: anonymous: enabled: false webhook: cacheTTL: 2m0s enabled: true x509: clientCAFile: /etc/kubernetes/pki/ca.pem authorization: mode: Webhook webhook: cacheAuthorizedTTL: 5m0s cacheUnauthorizedTTL: 30s cgroupDriver: systemd cgroupsPerQOS: true clusterDNS: – 10.96.0.10 clusterDomain: cluster.local containerLogMaxFiles: 5 containerLogMaxSize: 10Mi contentType: application/vnd.kubernetes.protobuf cpuCFSQuota: true cpuManagerPolicy: none cpuManagerReconcilePeriod: 10s enableControllerAttachDetach: true enableDebuggingHandlers: true enforceNodeAllocatable: – pods eventBurst: 10 eventRecordQPS: 5 evictionHard: imagefs.available: 15% memory.available: 100Mi nodefs.available: 10% nodefs.inodesFree: 5% evictionPressureTransitionPeriod: 5m0s #缩小相应的配置 failSwapOn: true fileCheckFrequency: 20s hairpinMode: promiscuous-bridge healthzBindAddress: 127.0.0.1 healthzPort: 10248 httpCheckFrequency: 20s imageGCHighThresholdPercent: 85 imageGCLowThresholdPercent: 80 imageMinimumGCAge: 2m0s iptablesDropBit: 15 iptablesMasqueradeBit: 14 kubeAPIBurst: 10 kubeAPIQPS: 5 makeIPTablesUtilChains: true maxOpenFiles: 1000000 maxPods: 110 nodeStatusUpdateFrequency: 10s oomScoreAdj: -999 podPidsLimit: -1 registryBurst: 10 registryPullQPS: 5 resolvConf: /etc/resolv.conf rotateCertificates: true runtimeRequestTimeout: 2m0s serializeImagePulls: true staticPodPath: /etc/kubernetes/manifests streamingConnectionIdleTimeout: 4h0m0s syncFrequency: 1m0s volumeStatsAggPeriod: 1m0s |
接下来启动即可
systemctl daemon-reload && systemctl enable –now kubelet
systemctl status kubelet
之后就是全局都有的kube-proxy
首先创建一个ServiceAccount供kube-proyx使用
kubectl -n kube-system create serviceaccount kube-proxy
#创建角色绑定
kubectl create clusterrolebinding system:kube-proxy \
–clusterrole system:node-proxier \
–serviceaccount kube-system:kube-proxy
然后是master节点生成一个conf文件
提前做好一些变量的设置
SECRET=$(kubectl -n kube-system get sa/kube-proxy –output=jsonpath='{.secrets[0].name}’)
JWT_TOKEN=$(kubectl -n kube-system get secret/$SECRET –output=jsonpath='{.data.token}’ | base64 -d)
PKI_DIR=/etc/kubernetes/pki
K8S_DIR=/etc/kubernetes
然后生成kube-proxy的配置
kubectl config set-cluster kubernetes \
–certificate-authority=/etc/kubernetes/pki/ca.pem \
–embed-certs=true \
–server=https://192.168.0.250:6443 \
–kubeconfig=${K8S_DIR}/kube-proxy.conf
这里需要注意,如果不是高可用集群,那么不要设置 192.168.0.250,而应该是master1的配置
然后设置token
kubectl config set-credentials kubernetes \
–token=${JWT_TOKEN} \
–kubeconfig=/etc/kubernetes/kube-proxy.conf
之后编写上下文的初始化和设置
kubectl config set-context kubernetes \
–cluster=kubernetes \
–user=kubernetes \
–kubeconfig=/etc/kubernetes/kube-proxy.conf
kubectl config use-context kubernetes \
–kubeconfig=/etc/kubernetes/kube-proxy.conf
之后便是将这个conf传递到不同的节点上
for NODE in k8s-master2 k8s-master3 k8s-node1 k8s-node2 k8s-node3; do
scp /etc/kubernetes/kube-proxy.conf $NODE:/etc/kubernetes/
done
然后设置kube-proxy.service
vi /usr/lib/systemd/system/kube-proxy.service
|
[Unit] Description=Kubernetes Kube Proxy Documentation=https://github.com/kubernetes/kubernetes After=network.target [Service] ExecStart=/usr/local/bin/kube-proxy \ –config=/etc/kubernetes/kube-proxy.yaml \ –v=2 Restart=always RestartSec=10s [Install] WantedBy=multi-user.target |
上面我们还声明了使用配置yaml
vi /etc/kubernetes/kube-proxy.yaml
|
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0 clientConnection: acceptContentTypes: “” burst: 10 contentType: application/vnd.kubernetes.protobuf kubeconfig: /etc/kubernetes/kube-proxy.conf #kube-proxy引导文件 qps: 5 clusterCIDR: 196.16.0.0/16 #修改为自己的Pod-CIDR configSyncPeriod: 15m0s conntrack: max: null maxPerCore: 32768 min: 131072 tcpCloseWaitTimeout: 1h0m0s tcpEstablishedTimeout: 24h0m0s enableProfiling: false healthzBindAddress: 0.0.0.0:10256 hostnameOverride: “” iptables: masqueradeAll: false masqueradeBit: 14 minSyncPeriod: 0s syncPeriod: 30s ipvs: masqueradeAll: true minSyncPeriod: 5s scheduler: “rr” syncPeriod: 30s kind: KubeProxyConfiguration metricsBindAddress: 127.0.0.1:10249 mode: “ipvs” nodePortAddresses: null oomScoreAdj: -999 portRange: “” udpIdleTimeout: 250ms |
接下来便是kube-proxy的启动了
systemctl daemon-reload && systemctl enable –now kube-proxy
然后为了集群的正常使用,还需要配置网络,即Calico插件
那么我们就需要在master及诶单上配置calico
首先下载calico的yaml
curl https://docs.projectcalico.org/manifests/calico-etcd.yaml -o calico.yaml
需要修改这个yaml中的image地址
以及etcd的集群地址
将这个etcd_endpoints的value改为对应的集群地址
sed -i ‘s#etcd_endpoints: “http://<ETCD_IP>:<ETCD_PORT>”#etcd_endpoints: “https://192.168.0.10:2379,https://192.168.0.11:2379,https://192.168.0.12:2379″#g’ calico.yaml
修改对应的证书信息,利用base64编码后设置到yaml中
ETCD_CA=`cat /etc/kubernetes/pki/etcd/ca.pem | base64 -w 0 `
ETCD_CERT=`cat /etc/kubernetes/pki/etcd/etcd.pem | base64 -w 0 `
ETCD_KEY=`cat /etc/kubernetes/pki/etcd/etcd-key.pem | base64 -w 0 `
# 替换etcd中的证书base64编码后的内容
sed -i “s@# etcd-key: null@etcd-key: ${ETCD_KEY}@g; s@# etcd-cert: null@etcd-cert: ${ETCD_CERT}@g; s@# etcd-ca: null@etcd-ca: ${ETCD_CA}@g” calico.yaml
#打开 etcd_ca 等默认设置(calico启动后自己生成)。
sed -i ‘s#etcd_ca: “”#etcd_ca: “/calico-secrets/etcd-ca”#g; s#etcd_cert: “”#etcd_cert: “/calico-secrets/etcd-cert”#g; s#etcd_key: “” #etcd_key: “/calico-secrets/etcd-key” #g’ calico.yaml
修改自己的Pod网段
POD_SUBNET=”196.16.0.0/16″
sed -i ‘s@# – name: CALICO_IPV4POOL_CIDR@- name: CALICO_IPV4POOL_CIDR@g; s@# value: “192.168.0.0/16″@ value: ‘”${POD_SUBNET}”‘@g’ calico.yaml
最后便是kubectl apply -f calico.yaml
在等待Calico就绪之后,我们可以需要部署这个CoreDNS
对于CoreDNS的部署也并不困难,官方给我们提供了对应的脚本
git clone https://github.com/coredns/deployment.git
cd deployment/kubernetes
./deploy.sh -s -I 10.96.0.10 | kubectl apply -f
然后由于是二进制的方式进行安装的,所以master节点上不会打上污点
需要手动加上
kubectl taint nodes k8s-master1 node-role.kubernetes.io/master=:NoSchedule
其次是其他的一些Label,比如区分master和Worker
kubectl label node k8s-master1 node-role.kubernetes.io/master=”
kubectl label node k8s-master2 node-role.kubernetes.io/master=”
kubectl label node k8s-master3 node-role.kubernetes.io/master=”
然后部署一个service进行测试
|
apiVersion: apps/v1
kind: Deployment metadata: name: nginx-01 namespace: default labels: app: nginx-01 spec: selector: matchLabels: app: nginx-01 replicas: 1 template: metadata: labels: app: nginx-01 spec: containers: – name: nginx-01 image: nginx — apiVersion: v1 kind: Service metadata: name: nginx-svc namespace: default spec: selector: app: nginx-01 type: ClusterIP ports: – name: nginx-svc port: 80 targetPort: 80 protocol: TCP — apiVersion: v1 kind: Namespace metadata: name: hello spec: {} — apiVersion: apps/v1 kind: Deployment metadata: name: nginx-hello namespace: hello labels: app: nginx-hello spec: selector: matchLabels: app: nginx-hello replicas: 1 template: metadata: labels: app: nginx-hello spec: containers: – name: nginx-hello image: nginx — apiVersion: v1 kind: Service metadata: name: nginx-svc-hello namespace: hello spec: selector: app: nginx-hello type: ClusterIP ports: – name: nginx-svc-hello port: 80 targetPort: 80 protocol: TCP |
测试彼此是否可以通信
之后是配置coreDns
这一点比较好配置,直接git clone下即可
|
git clone https://github.com/coredns/deployment.git
cd deployment/Kubernetes ./deploy.sh -s -i 10.96.0.10 | kubectl apply -f – |
然后是一些集群方面的优化
首先是docker相关的配置优化
设置仓库地址和一些保活机制
|
vi /etc/docker/daemon.json
{ “registry-mirrors”: [ “https://82m9ar63.mirror.aliyuncs.com” ], “exec-opts”: [“native.cgroupdriver=systemd”], “max-concurrent-downloads”: 10, “max-concurrent-uploads”: 5, “log-opts”: { “max-size”: “300m”, “max-file”: “2” }, “live-restore”: true } |
其中配置了仓库,然后live-restore保证了docker服务掉线的情况下,容器仍然存活
systemctl daemon-reload && systemctl restart docker
然后是优化kubelet
为了避免kubelet调度太多pod在宿主机上,导致宿主机上资源枯竭
故在kubelet中进行配置
|
vi /etc/kubernetes/kubelet-conf.yml
# kubeReserved: kubelet预留资源 kubeReserved: cpu: “500m” memory: 300m ephemeral-storage: 3Gi systemReserved: cpu: “200m” memory: 500m ephemeral-storage: 3Gi |
访问下10249来验证是否是ipvs模式
curl 127.0.0.1:10249/proxyMode
最后是时区问题的考虑
因为很多dockerhub中的时区都是UTC,所以我们需要进行Pod的时区修改
如果是1.20之前的版本,可以考虑利用PodPreset这个kind来进行Pod的加工
|
apiVersion: settings.k8s.io/v1alpha1
kind: PodPreset metadata: name: allow-localtime namespace: spinnaker spec: selector: matchLabels: volumeMounts: – mountPath: /etc/localtime name: localtime volumes: – name: localtime hostPath: path: etc/localtime |
但是新版移除了这个特性,那么我们只能在Pod书写的时候避免这个问题