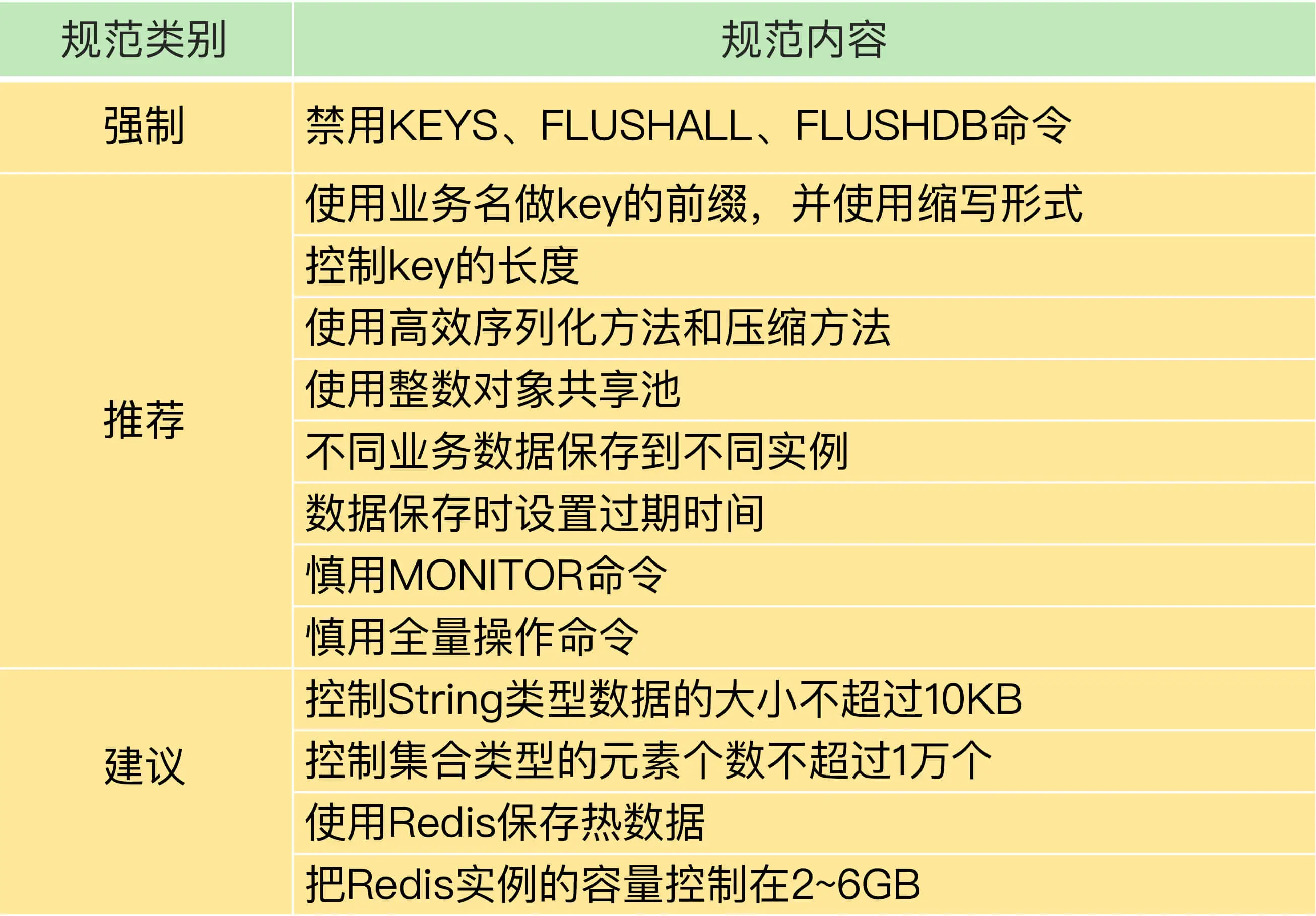
我们说一下Redis的使用规范,包含键值对的使用,业务数据保存和命令使用规范
我们也按照上面三个维度,进行三个方面的讲解
1.对键值对使用规范
键值对使用规范,主要是两个方面
key的命名规范,利用命名上的规范,提供可读性强,可维护性高的key,方便日常管理
value的设计规范,避免bigkey,高效序列化方法和压缩方法,使用整数对象共享池,合理的数据类型选择
规范一:key的命令规范
在Redis中,通过合理的命名key,减少字符串占用信息,因为key是字符串类型的,所以本身包含一定的元信息,在设置key的名称的时候,需要注意key的长度,如果很长的话,就会消耗较多的内存空间,我们可以考虑利用业务名作为前缀,然后冒号分割,加上具体的业务数据名,减少key长度
规范二:避免Bigkey的弧线
对于BigKey,相比不陌生,对于value的设计规范,最重要的一点就是避免bigkey
bigkey的出现常见于键值对的值本身就很大,value为1MB的String类型数据就是一个标准的bigkey,或者键值对的值是一个集合类型,集合的元素数量非常多,包含100万个元素的Hash集合类型数据,避免集合类型的bigkey,建议控制集合的个数,或者拆分集合
规范三,使用高效的序列化方法和压缩方法
使用高效的序列化和压缩方法,可以减少value的大小
不同的序列化方式,在序列化速度和数据序列化后占用的空间大小两方面是不一样的,protostuff和kryo两种方法,就比Java内置的序列化方法高
规范四:使用整数对象共享池
对于Redis,也和Java一样维护了共享对象,Redis将0-9999这一万个整数对象,放在了个共享池中使用
保存的时候如果是范围内的整数对象,可以节省内存空间
但是这个整数对象共享池的使用,需要考虑情况,如果使用LRU策略,进行过期时间的话,因为共享对象导致LRU策略统计不准
对于业务数据保存的规范
规范一:使用Redis保存数据
是的,Redis是一个缓存数据库,我们应该考虑只将热点数据放在Redis中,而不是将业务数据都保存在Redis中,带来较大的内存成本压力
规范二:不同业务数据分实例存储
将所有数据混杂的放在一个实例上,那么对于不同数据的操作必然会导致干扰
所以我们应该考虑不同的业务数据放在不同的实例下保存,避免不同业务的操作进行干扰
规范三:数据保存时候要设置过期时间
Redis的内存是非常宝贵的资源,一般用于热数据,而且需要考虑时效性,故需要设置数据的过期时间,不然写入Redis的数据会一直占用内存
规范四:Redis实例大小需要注意
如果一个实例过大,那么在集群同步的时候,可能会阻塞正常请求的处理
最后是命令使用上的规范
规范一:禁用部分命令
对于Redis的部分大量操作,耗时长的命令,需要考虑禁用,我们看一些示例
KEYS:根据键值对的key进行匹配,需要进行全表扫描,严重阻塞Redis主线程
FLUSHALL:删除Redis实例上的所有数据,如果数据量很大,就会阻塞Redis主线程
FLUSHDB:删除当前数据库中的数据,如果数据量很大,就会阻塞主线程
对于其,可以使用一些命令来代替
对于KEYS,可以使用SCAN来代替KEYS命令,分批返回符合条件的键值对,避免主线程阻塞
对于FLUSHDB和FLUSHALL命令,可以加上ASYNC选项,使用后台线程异步删除数据,避免阻塞
使用rename-command命令在配置文件中对这些命令进行重命名,让客户端无法使用这些命令
规范二:慎用MONITOR命令
Redis的MONITOR命令会在执行之后,持续的输出检测到的各个命令操作,其会将监控到的内容持续写入输出缓冲区,如果线上命令操作很多,输出缓冲区会被阻塞,.造成服务的崩溃
所以,除非十分需要检测某些命令的执行,短时间的使用MONITOR命令
规范三:慎用全量操作命令
对于集合类型的操作,如果想要获得集合中的所有元素,一般不建议使用全量操作的命令,可能阻塞Redis主线程
对于此,建议是使用SSCAN HSACN命令分批返回集合中的数据,减少主线程的阻塞
以及换整为零,将一个大的Hash集合转换为多个小的Hash集合,或者将Hash对象序列化后利用String数据进行存储,避免全量扫描
总结一下,我们将整体的建议分为了三类,分别是强制,推荐,建议