从String说Reids的数据结构
我们先拿一个案例来看String类型的内存空间消耗及其数据结构,
比如我们有一个键值对存储的需求,需要根据一个10位数来找到另一个10位数
这样就是标准的key-value存储,所以优先考虑就是使用String类型来存储这个key及value
一开始,我们保存了1亿个键值对,用了大约6.4GB内存,这个内存空间大小说大不大,但是也并不能算小
因为上面来看一个KV键值对平均使用了64字节,但就原始数据大小,平均也就是16字节
两个Long类型(16字节)到64字节,必然有一些额外的内存消耗
这想必是String类型保存了额外的内存空间记录数据长度,空间使用等信息,这些信息也被称为元数据,像我们保存两个Long类型这样的小数据的时候,元数据的空间开销就显得比较大了
String类型内部也有着不同类型的数据保存方式
如果保存的是64位有符号整数的时候,String类型就会将其保存为一个8字节的Long类型
如果保存的数据中包含字符串,String就会使用简单动态字符串 Simple Dynamic String来保存数据
而简单动态字符串内部包含了
| Buf:字节数组,保存实际数组,在结尾会有一个 “\0” |
| len:四个字节,表示buf的已用长度 |
| alloc:也占四个字节,表示buf的实际分配长度,一般大约len |
在SDS之中,len和alloc可以算是SDS结构体中的额外开销
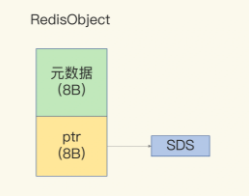
这是底层的数据结构,Reids还在外面为其包裹了一层对象结构体的开销,为了证明其是Object
这个额外的结构体开销,就是RedisObject结构体
RedisObject包括了8字节的元数据和一个8字节的指针
元数据保存了不同数据类型需要记录的数据,比如最后一层访问时间,引用次数
指针则是指向了实际数据内存地址
不过,Reids针对不同的上层数据结构,进行了内存布局的优化
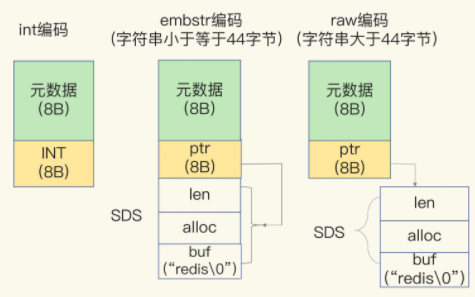
String中区分了Long类型整数和SDS,所以有着专门的设计
如果保存的是Long类型,RedisObject中的ptr将直接保存整数数据,减少内存开销
如果是SDS,其中也有着不同方式的存储,如果字符串小于等于44字节,RedisObject中的元数据 指针 SDS则是一个连续的内存区域,避免内存碎片,称为embstr编码
如果大于44字节,SDS的数据量变多了,Redis则会变为一开始的标准内存布局,称为raw编码
那么,从这样看的话,我们存储Long的KV键值对,那么实际用的是int编码的RedisObject保存的
那么就是元数据为8字节,指针部分存储着实际的数据,占用8字节,然后本身占用16字节,也就一共32字节,多出来的32字节去哪了呢?
这一部分的内存消耗源于Redis会使用一个全局的哈希表保存所有的键值对,哈希表的每一项都是一个dictEntry的结构体,维护了三个部分的指针,分别指向key,value以及下一个dictEntry,总共24字节
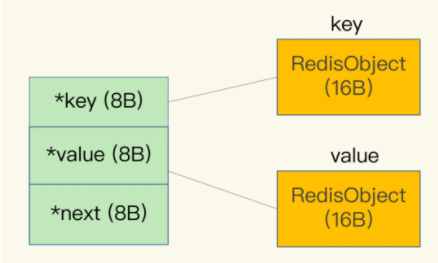
这一部分占用了32个字节,虽然表面上只有24字节,但是由于Redis的内存分配库jemalloc,如果申请24字节,会直接分配32字节,因为他会找到一个比自己申请的字节数大的N的2的幂次数作为分配的空间
这也就是32字节的由来
综上所述,这也就是KV键值对本身只有16字节的数据大小,但是需要64字节的内存空间,元数据和指针就占用了48个字节
那么也就是说如果有6.4GB的内存空间,其中4.8GB的内存空间都用来保存元数据了,额外的空间开销太大了
如何解决上面的数据结构问题
Reids的底层数据结构有一种叫做ziplist,一种非常节省内存的结构
其在表头有三个字段 zlbytes,zltail 和zllen,分别代表着列表长度,列表尾的偏移量,以及列表中的entry个数,压缩列表尾还尾还有一个zlend,表示列表结束
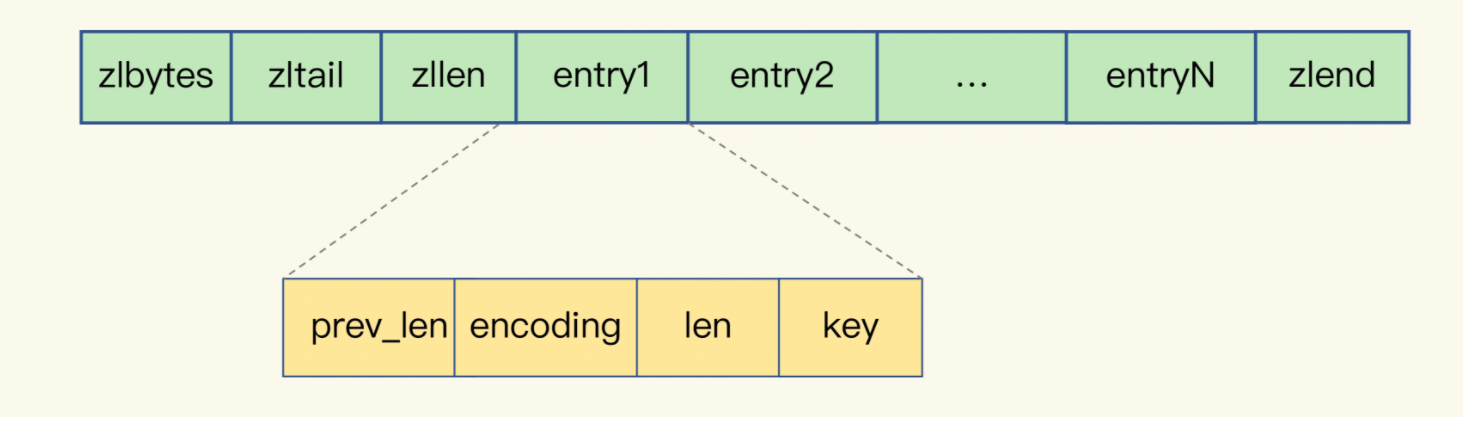
压缩列表之所以可以节省内存,就是内部保存的entry数据,每个entry元数据包含如下的部分
prev_len,表示前一个entry的长度,perv_len有两种取值,1字节和5字节,取值1字节的时候,表示上一个entry的长度小于254字节
len,表示自身长度,4字节
encoding,表示编码方式,1字节
content,保存实际数据
如果是保存上面的Long,那么perv_len只需要1字节,那么就是1+4+1+8=14字节,实际分配16字节
Reids基于压缩列表实现了List Hash Sorted Set这样的集合
而且使用集合的类型,一个key对应了一个集合的数据,能保存的数据就多了很多,而且只用了一个dictEntry,节省了内存
这个方案听起来很好,但是需要注意,集合类型保存键值对如果使用不当,还是不能带来什么空间上的节省
对于集合类型保存单值的键值对,可以采用基于Hash的二级编码,
将Key拆为两个部分前一部分作为Hash集合的key,后一部分作为Hash集合的value,方便保存到Hash集合中.
故,如果保存
1101000060:3302000080的话
可以将1101000作为Hash的键,060和3302000080作为Hash类型的key和value
那么新增加一条数据,平均来说只会使用16字节
不过在其中还需要注意一点买就是二级编码的ID长度是有讲究的
Reids Hash的底层实现结构分别为压缩列表和哈希表,在Redis中,有一个阈值来区分是否使用压缩列表,如果超过了则会从压缩列表转换为哈希表,且不可逆
而这个阈值是由两方面决定的
hash-max-ziplist-entries:表示用压缩列表保存时候哈希集合中最大元素个数
hash-max-ziplist-value,:表示压缩列表保存时集合中单个元素的最大长度
这也就是为何确定hash中key为3位,保证了Hash中集合个数不超过1000,确定了hash-max-ziplist-entries设置为1000就可以保证一直使用压缩列表来节省空间
总结一下,我们重新认知了String的底层数据结构,而且延伸到了ReidsObject SDS结构 dictEntry结构这些内存开销
针对这种情况,可以使用压缩列表来保存数据,使用Hash这类集合保存单值键值对的时候,可以考虑使用二级编码这种方式
最后一个小问题,除了String和Hash,还有那些合适的类型来保存这个例子?
看来只有sorted sort了,因为从上面看,我们应该考虑能节省的内存空间,应该是dictEntry结构体带来的额外开销,故尽可能的减少Key,剩下的数据结构中,唯一能做到的,应该只有sorted key了,但是其数据结构有一个弊端,就是压缩列表情况下,查询非常麻烦,需要进行遍历操作,所以也不适合