09.Redis的切片集群
每次说到Redis,都离不开其切片集群,比如我们需要保存大量的键值对,每个键值对并不大,但是数量相对较多,对此,我们需要进行扩容,可以选择的方式有两种,分别的名称为纵向扩展和横向扩展
纵向扩展指的是,升级单个Reids实例的资源配置,包括内存容量,增加磁盘容量,使用更高配置的CPU
横向扩展,就是横向增加Reids的实例个数,将原本一个实例,扩展为三个实例
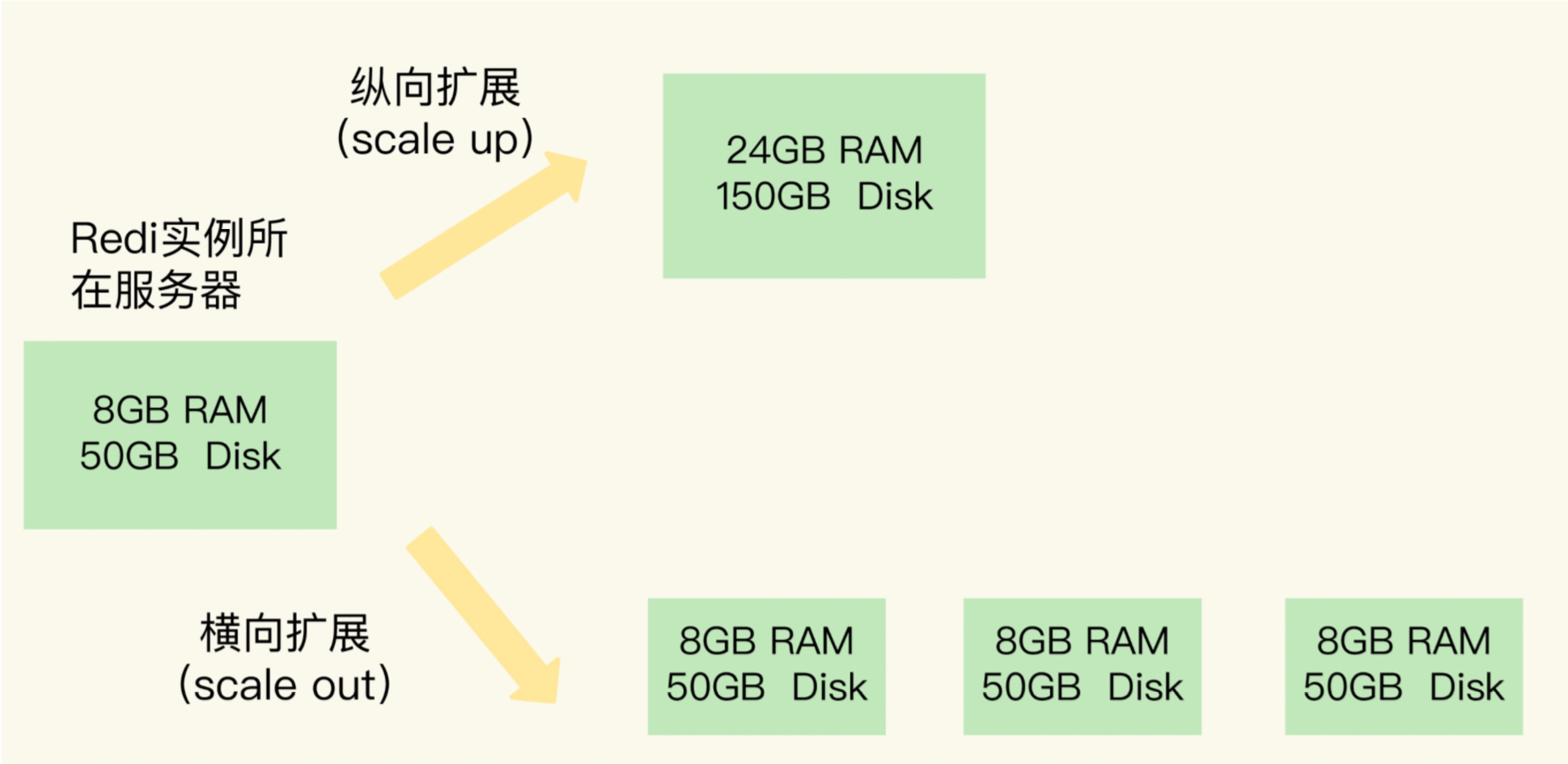
两者的各有优缺点.
比如纵向扩展中,当使用RDB对数据进行持久化的时候,如果数据量增加了,主进程在fork子进程的时候,可能会出现阻塞的问题
第二个问题,纵向扩展会受到硬件和成本的限制,毕竟128GB往上扩展可不好扩了
与之相对的,横向扩展中,如果需要保存更多的信息,只需要增加Redis的实例个数就可以了,非常适合大规模数据的保存
但在横向扩展中,需要面对几个问题,数据切片后,如何分布的保存,客户端如何确定想要访问的数据在哪个实例上?
首先是数据和实例的对应关系
切片集群中,数据需要分布在不同的实例上,Redis官方给出的Reids Cluster方案采用了哈希槽的方式,来处理数据和实例之间的映射关系,在Reids Cluster方案中,总共分为了16384个哈希槽,每个键值对数据都根据key的hash值,分配到一个哈希槽中
假设有N个实例,那么Cluter默认创建的集群中实例上每个槽的个数为16384/N个
当然对于每个实例上槽的个数,是可以进行指定的,使用cluster addslots命令进行制定哈希槽的个数
执行的命令如下
| redis-cli -h 172.16.19.3 –p 6379 cluster addslots 0,1
redis-cli -h 172.16.19.4 –p 6379 cluster addslots 2,3 redis-cli -h 172.16.19.5 –p 6379 cluster addslots 4 |
但是,如果是使用addslots这种手动分配的方式,必须要将16384个槽都分配了,不然没法正常的工作
这样,初始化的分配就完成了,接下来客户端如何知道要访问的数据在哪个实例上呢?
一般来说,正常的访问情况下,客户端要访问的哈希槽是可以通过hash计算得出,但是客户端如何知道哈希槽对应的实例在哪呢?想必也是利用了pub/sub机制或者是反熵的机制
Reids利用pub/sub机制或者是反熵的机制完成哈希槽对应信息的扩散
方便客户端获取到并将其缓存
正常情况说完了,我们需要考虑些常见的临界情况,
就是Redis集群中新增或者减少实例,以及哈希重分配
对于Reids实例的哈希槽分配我们先不谈,主要说一下客户端如何感知变化并且请求到新实例的
Redis Cluster方案提供了一种重定向机制,就是客户端给实例上发送读写请求的时候,如果对应的实例上没有对应的数据,客户端要再给一个新实例发送操作命令
基本操作为:如果客户端访问一个实例,发起请求,但是实例上没有键值对映射的哈希槽
那么实例就会给客户端返回下面的MOVED命令响应结果,包含了实例的访问地址
| GET hello:key
(error) MOVED 13320 172.16.19.5:6379 |
MOVED命令后面跟着客户端请求的哈希槽,最后的是要重定向的IP地址
但是存在一个中间的状态,比如在迁移过程中,只有部分数据迁移了,这时候客户端请求的话,会直接收到一个ASK报错信息
| GET hello:key
(error) ASK 13320 172.16.19.5:6379 |
ASK命令含义为,客户端获取的哈希槽 13320在172.16.19.5这个实例上,如果想要访问现在数据所在的实例并修改,就需要首先给172.16.19.5这个实例发送一个ASKING命令,然后客户端再向实例发送GET命令,进行读取
但是需要注意的是,ASK命令并不会更新客户端缓存的哈希槽分配信息,也就是说,如果客户端还需要请求相同的key,那么还是会向之前的实例发送请求
总结一下,我们学习了切片集群在保存大量数据方面的优势,以及基于哈希槽的数据分布机制和客户端键值对保存的方法
我们还说了切片集群提供了横向扩展的模式,将多个实例,并给每个实例配置一定数量的哈希槽
方便根据键来映射到对应的哈希槽,扩展性优秀,不管多少数据,都能利用切片集群应对
并且说了和客户端相关的MOVED和ASK命令
Redis官方提供了Redis Cluster,除此外还有基于客户端分区的shardedJedis,代理的Codis Twemproxy,都是各有优势,方便学习,可以根据这些方案的选择合适的切片集群
最后一个小问题,Reids Cluster通过哈希槽的方式将键值对分配到不同的实例上,这一步,为何不采用一个表将键值对和实例的关系记录下来
别忘了,如果使用哈希表作为映射关系的维护方式,那么这个哈希表的维护将是一个非常庞大的工作量,一个实例的上下线,都将修改大量的hash表内数据,这一步可以利用反熵等机制来实现维护,但是反熵带来的额外耗时,都是新出现的问题