内核中如何管理线程呢?
有的进程只有一个线程,有个进程有多个线程,但是都需要内核CPU来分配时间去干活
如何进行调度呢?
首先说,公司内有多个项目组,项目组对应进程,进程多是好事,但是进程之间有不同的开发模式
但从操作系统角度来说,这些项目需要有一个统一的项目管理体系
就好比无论是单体应用模式,还是微服务模式,都是根据客户的需求去定制的,都需要统一的协调资源等
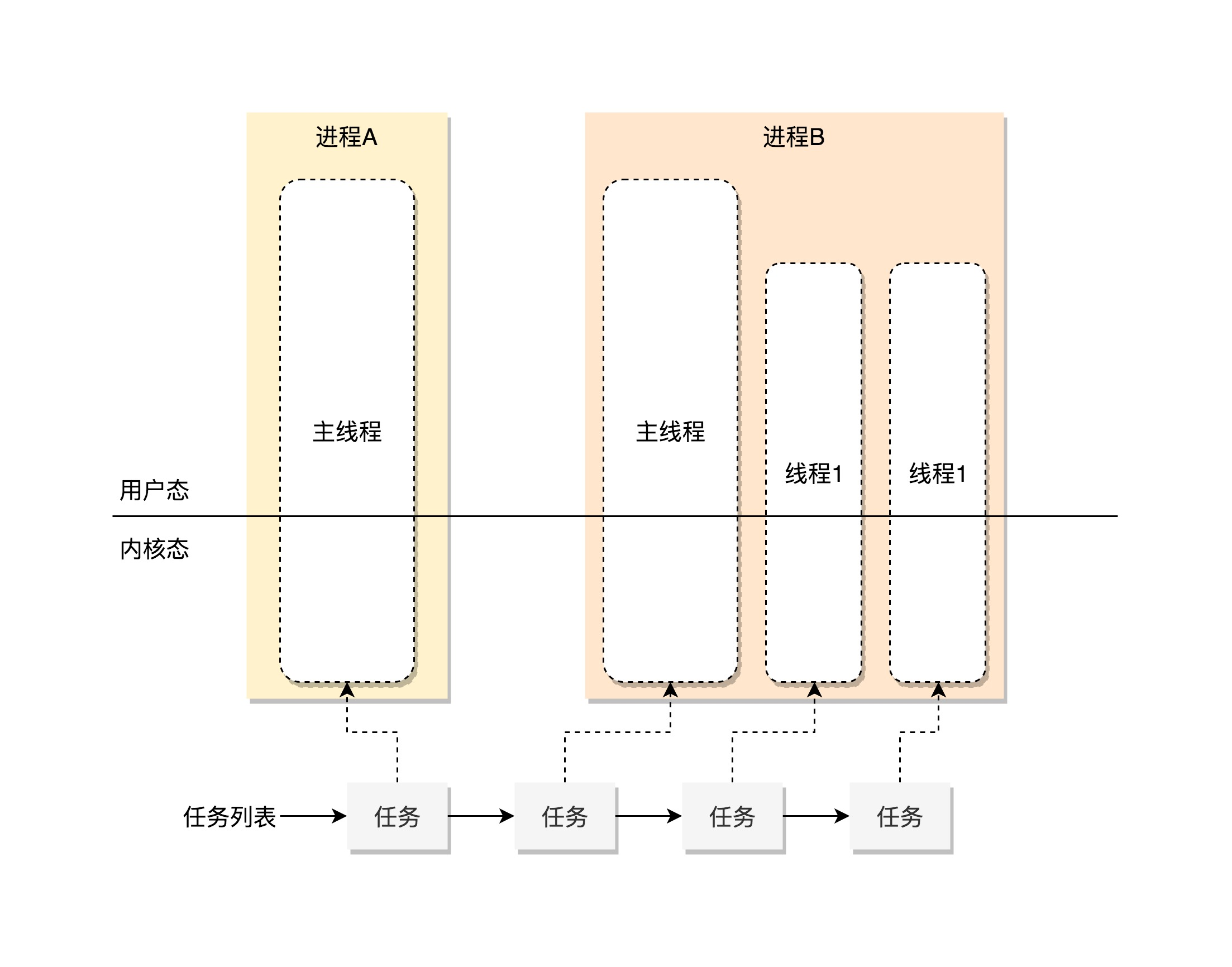
同样在Linux中,无论是进程还是线程,都是统一的叫做Task,交给task_struct进行管理
我们先说下这个task_struct的结构
我们设想一下,Linux的任务管理应该干什么呢?
首先需要一个统一的项目管理列表,所以Linux维护了一个链表,进行串起来
struct list_head tasks
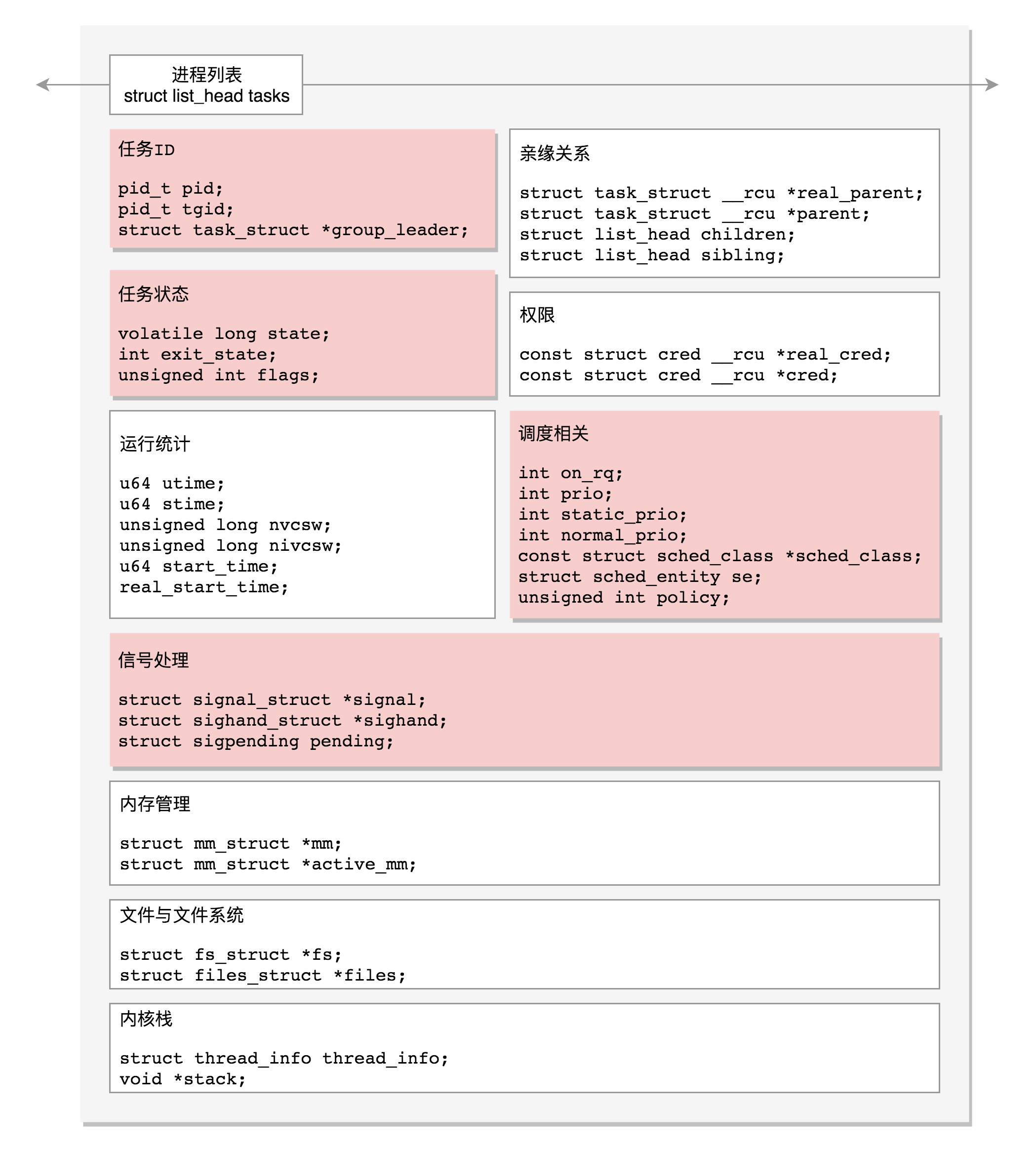
然后是任务ID
每个任务都有一个ID,作为这个任务的唯一表示,所以标识位如下
pid_t pid
pid_t tgid
struct task_struct *group_leader
但是作为唯一标识,为何有这么多的标识位呢?
逐步展开来讲,我们需要进行任务展示,每个小组都是啥情况,如果将所有线程进行平铺展示,会让用户觉着复杂和疑惑,复杂在于列表如此长,疑惑在于线程很多不是自己创建的
其次是给任务下达指令,如果一个客户给项目组提了一个新的需求,客户可能觉着项目已经完成,可以终止,那么操作系统给谁发指令,是整个项目组吧,Linux也一样,我们学习命令行的时候,可以通过kill给线程发信号,通知进程退出,发给其中一个线程,就不能只退出一个线程,而是整个进程
所以在内核中,任务需要加以区分,其中pid是process id,tgid thread group Id
一个任务,如果只有主线程,pid是自己,tgid是自己,group_leader指向的还是自己
一个线程创建了多个线程,那么就会变化,线程有自己的pid,tgid是进程主线程的pid,group_leader指向的就是进程的主线程
tgid就是区分线程代表的是一个进程还是一个线程
信号处理
task_struct中关于信号处理的字段
| /* Signal handlers: */
struct signal_struct *signal; struct sighand_struct *sighand; sigset_t blocked; sigset_t real_blocked; sigset_t saved_sigmask; struct sigpending pending; unsigned long sas_ss_sp; size_t sas_ss_size; unsigned int sas_ss_flags; |
里面定义了信号类型,阻塞不处理 blocked,信号等待处理 pending,正在处理信号函数 sighand,
信号处理函数使用用户态的信号栈
还有最后的,任务的状态,也就是线程的状态
在task_struct里面,涉及任务状态的下面这几个变量
| volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
int exit_state; unsigned int flags; |
第一项,state 状态 定义在 include/linux/sched.h
| /* Used in tsk->state: */
#define TASK_RUNNING 0 #define TASK_INTERRUPTIBLE 1 #define TASK_UNINTERRUPTIBLE 2 #define __TASK_STOPPED 4 #define __TASK_TRACED 8 /* Used in tsk->exit_state: */ #define EXIT_DEAD 16 #define EXIT_ZOMBIE 32 #define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD) /* Used in tsk->state again: */ #define TASK_DEAD 64 #define TASK_WAKEKILL 128 #define TASK_WAKING 256 #define TASK_PARKED 512 #define TASK_NOLOAD 1024 #define TASK_NEW 2048 #define TASK_STATE_MAX 4096 |
上面的定义中,每一位,对应着的2进制的一位
现在是什么状态,哪一位就置为一
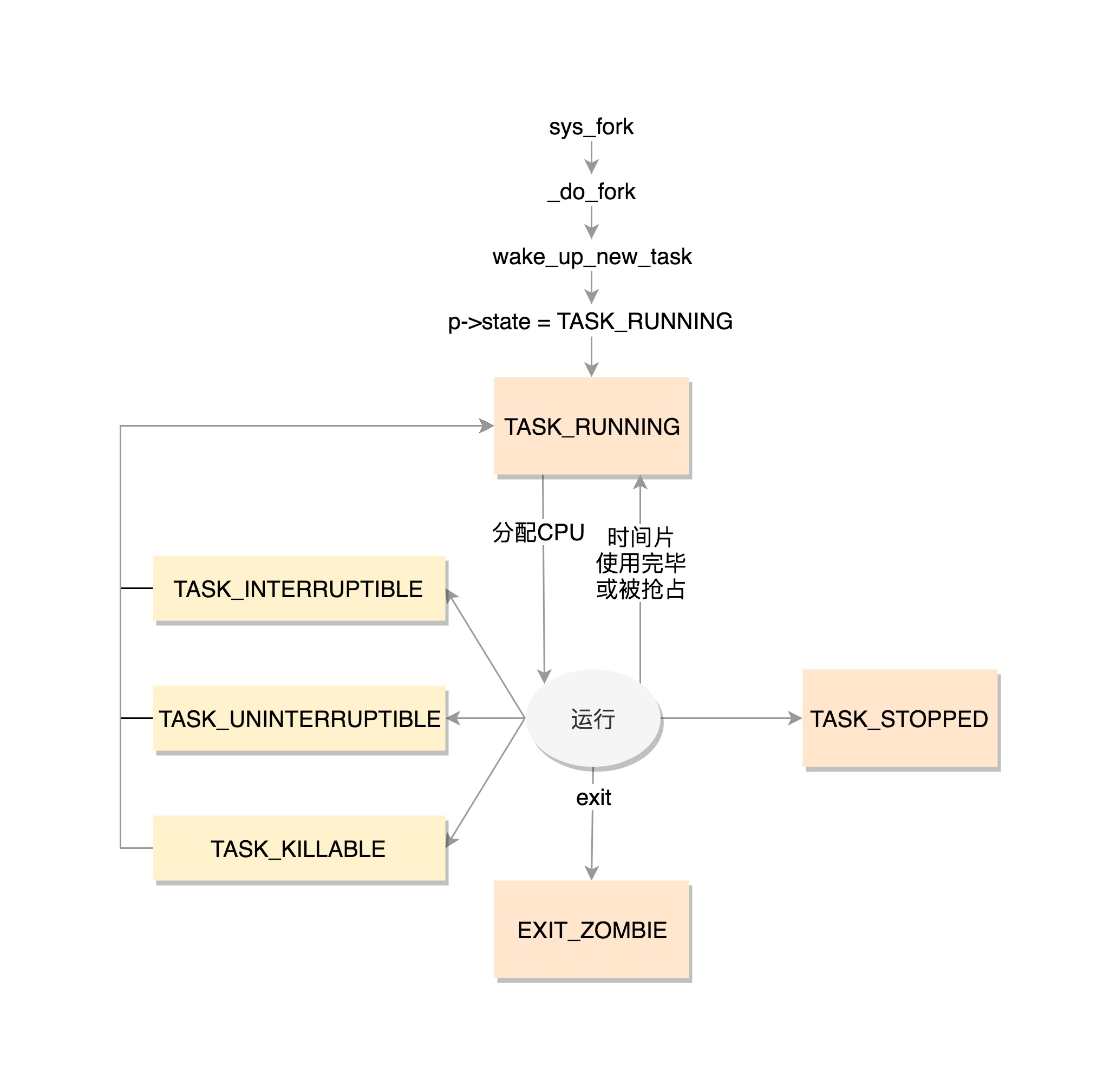
TASK_RUNNING是第一种状态,不是说进程正在进行,而是进程时刻准备运行的状态
当这个状态的进程获得时间片的时候,就是运行中,没有则说明需要等待再次分配时间片
在Linux中有两种睡眠状态
一种是TASK_INTERRUPTIBLE,可中断的睡眠状态,一种浅睡眠的状态,方便对应的唤醒操作
一种是TASK_UNINTERRUPTIBLE,不可中断的睡眠状态,不可被唤醒,只能死等,也不可被唤醒,KILL都唤不醒
后来有了新的进程睡眠状态,TASK_KILLABLE,可以终止新的睡眠状态,在TASK_UNINTERRUPTIBLE的基础上可以唤醒致命信号
TASK_WAKEKILL用于接收到致命信号时候唤醒进程,
TASK_STOPPED在收到SIGSTOP,SIGTTN,SIGTSTP或者SIGTTOU信号之后进入该状态
TASK_TRACED表示进程debugger等进程监视
进程结束的时候,进入的是EXIT_ZOMBIE状态,如果父进程还没有使用wait()等系统调用,就一直等待下去了
EXIT_DEAD也可以用于exit_state
上面的进程状态和进程运行 调度都有关系,还有其他状态,称为标志,放在flags字段中,都定义为了宏,以PF开头
#define PF_EXITING 0x00000004
#define PF_VCPU 0x00000010
#define PF_FORKNOEXEC 0x00000040
PF_EXITING,表示正在退出,方便统计活着的线程的时候,有这个flag,就直接跳过
PF_VCPU,在虚拟cpu上运行
PF_FORKNOEXEC,fork完成了,还没有exec,do_fork函数中调用了copy_process,将flag设置为PF_FORKNOEXEC,当EXEC调用了load_elf_binary的时候,将这个flag去掉
进程调度,进程的切换涉及调度
| //是否在运行队列上
int on_rq; //优先级 int prio; int static_prio; int normal_prio; unsigned int rt_priority; //调度器类 const struct sched_class *sched_class; //调度实体 struct sched_entity se; struct sched_rt_entity rt; struct sched_dl_entity dl; //调度策略 unsigned int policy; //可以使用哪些CPU int nr_cpus_allowed; cpumask_t cpus_allowed; struct sched_info sched_info; |
这次,我们总结一下task_struct的结构图
接下来就是项目的运行情况
如何了解一个员工的工作状态呢?进程的运行过程中,会有一些统计量,具体可以看下面的列表,会有进程在用户态和内核态消耗的时间,上下文切换的次数
| u64 utime;//用户态消耗的CPU时间
u64 stime;//内核态消耗的CPU时间 unsigned long nvcsw;//自愿(voluntary)上下文切换计数 unsigned long nivcsw;//非自愿(involuntary)上下文切换计数 u64 start_time;//进程启动时间,不包含睡眠时间 u64 real_start_time;//进程启动时间,包含睡眠时间 |
然后是进程的亲缘关系,
任何一个进程都有父子关系,进程关系本质上就是一个进程树
同一父进程的进程都有兄弟关系
那么进程关系上的结构如下
| struct task_struct __rcu *real_parent; /* real parent process */
struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */ struct list_head children; /* list of my children */ struct list_head sibling; /* linkage in my parent’s children list */ |
parent指向父进程,终止的时候,必须向父进程发送信号
children表示链表的头部,链表的所有元素都是子进程
sibling表示当前进程插入到兄弟进程中
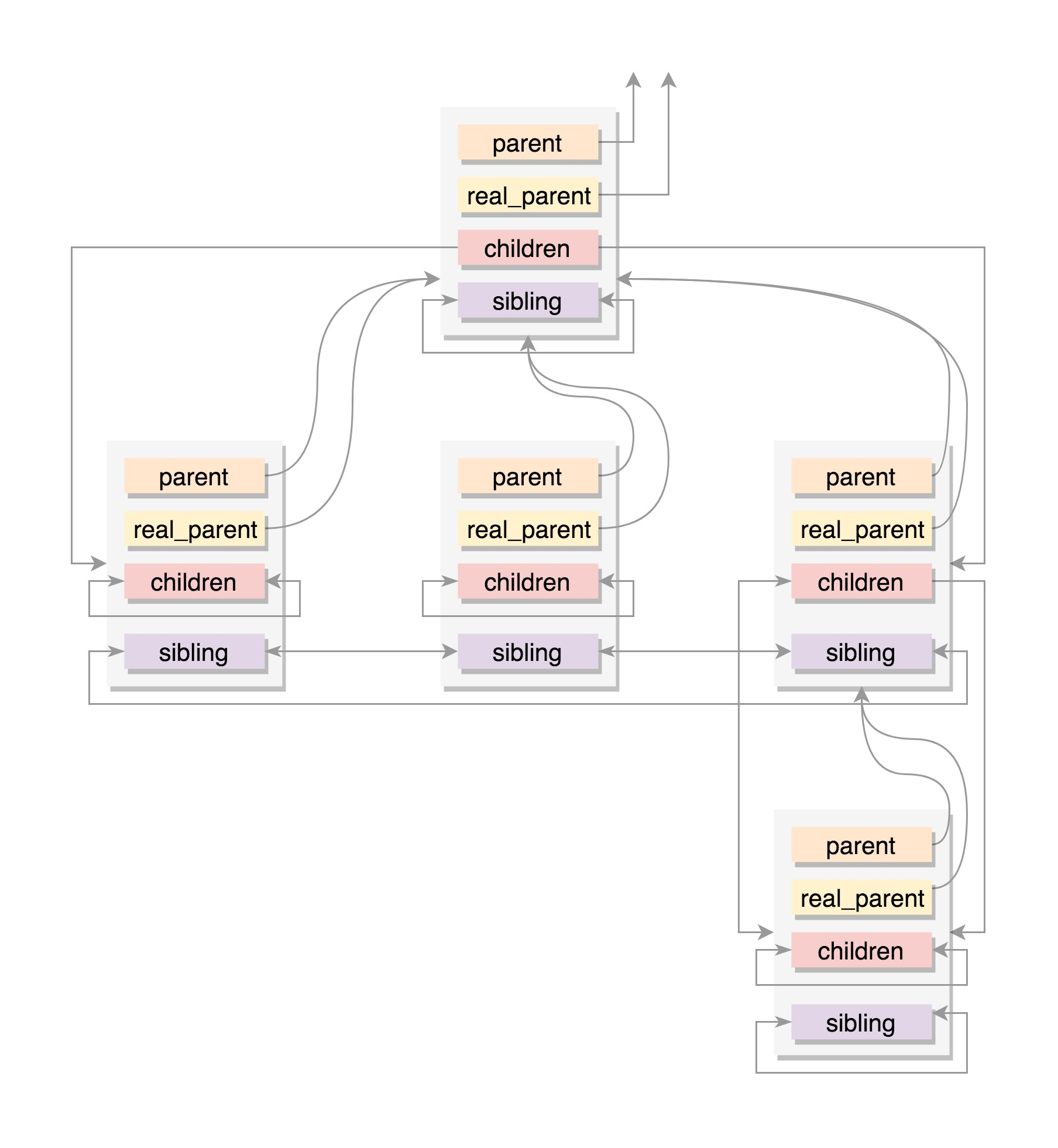
一般来说,real_parent和parent一致,但是有另外情况存在,bash的时候一般都一致,但是如果bash上使用GDB进行debug的时候,GDB是read_parent,bash是parent
进程权限
进程权限的定义基本如下
| /* Objective and real subjective task credentials (COW): */
const struct cred __rcu *real_cred; /* Effective (overridable) subjective task credentials (COW): */ const struct cred __rcu *cred; |
其中有的名词 Objective和Subjective,Objective是操作我的对象,Subjective是我操作的对象
操作是一些动作的实施,实施的时候,需要审核权限,其中real_cread是谁能操作我
cread是我能操作谁
| struct cred {
…… kuid_t uid; /* real UID of the task */ kgid_t gid; /* real GID of the task */ kuid_t suid; /* saved UID of the task */ kgid_t sgid; /* saved GID of the task */ kuid_t euid; /* effective UID of the task */ kgid_t egid; /* effective GID of the task */ kuid_t fsuid; /* UID for VFS ops */ kgid_t fsgid; /* GID for VFS ops */ …… kernel_cap_t cap_inheritable; /* caps our children can inherit */ kernel_cap_t cap_permitted; /* caps we’re permitted */ kernel_cap_t cap_effective; /* caps we can actually use */ kernel_cap_t cap_bset; /* capability bounding set */ kernel_cap_t cap_ambient; /* Ambient capability set */ …… } __randomize_layout; |
大部分是关于用户和用户组信息
uid gid user id group id 一般不审核这两个
euid egid effective user group id 起作用的,操作内存,信号量的时候,比较这个用户和组是否有权限
fsuid fsgid 文件操作审核权限
一般来说,fsuid euid uid都是一致的,fsgid egid gid都是一样的
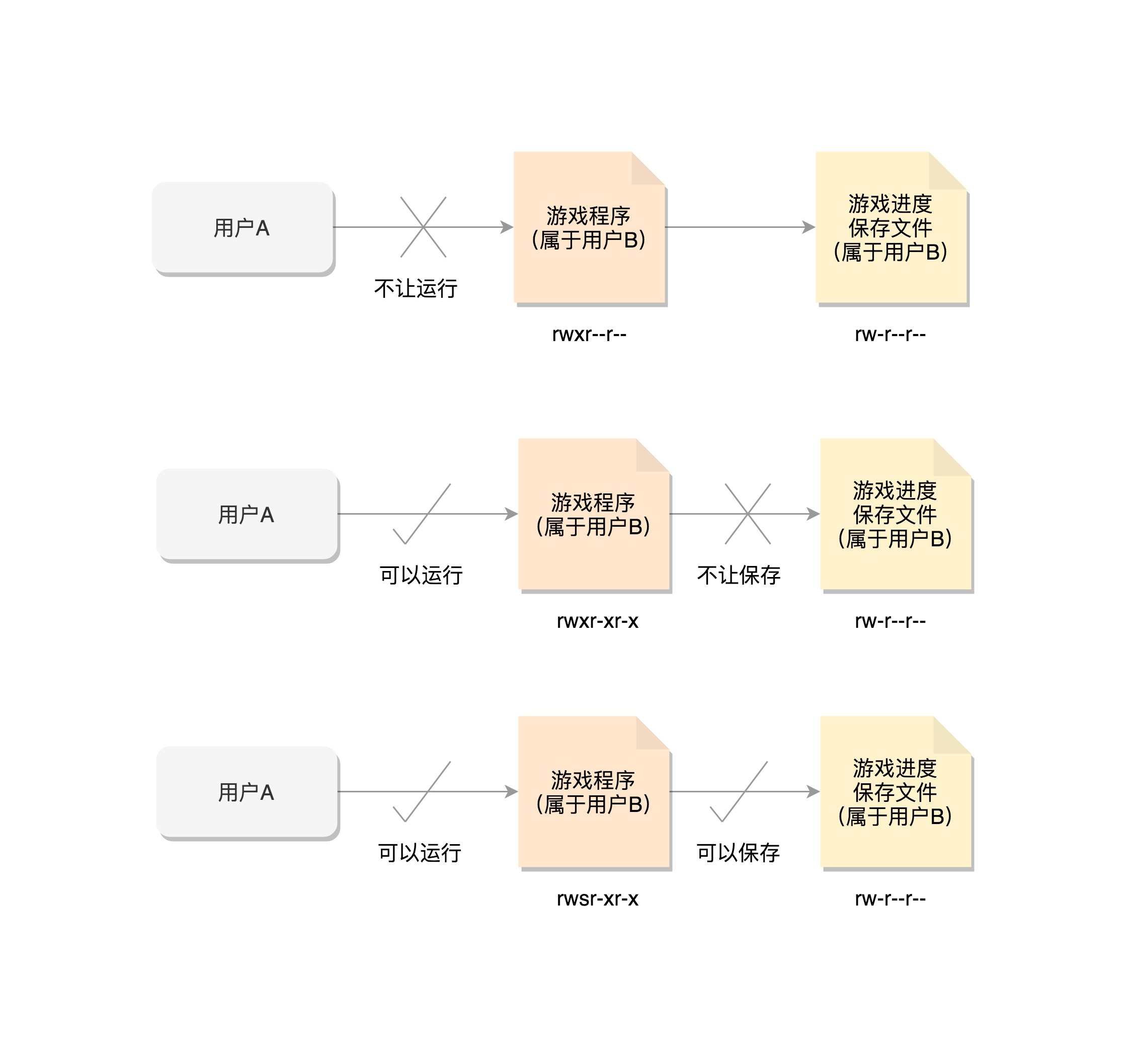
我们想使用一个游戏,但是游戏属于B,所以B需要给用户A权限
所以设置了执行权限 rwxr-xr-x
A有了用户权限,uid euid fsuid都是A
但是A需要保存数据的时候,发现数据是保存在其他文件中的,这就导致没法写入到文件,白玩了
如何操作呢?可以通过chmod u+s program命令,设置set-user-ID标识位,将权限设置位rwsr-xr-x
用户A启动的时候,利用set-user-id标识,将文件所有者ID,改为了用户B
利用setuid来改变权限
最后是内存管理
每个进程都有自己的独立虚拟内存空间,有一个数据结构来表示,mm_struct
内存管理那一节细讲
struct mm_struct *mm;
struct mm_struct *active_mm;
文件管理系统也有对应的数据结构
文件系统一节细讲
/* Filesystem information: */
struct fs_struct *fs;
/* Open file information: */
struct files_struct *files;
我们总结一下
进程亲缘关系维护的数据结构,会在内核中多个地方出现类似的结构
进程权限中setuid的原理,比较难以理解

最后,我们说一下内核栈的几个变量
struct thread_info thread_info
void *stack
用户态的函数栈
用户态的程序执行是一个程序调用另一个程序,函数调用通过栈进行的,我们大致讲了函数站的原理
函数调用很简单,看一下汇编语言的代码,就是指令跳转,从代码一个地方调转到别的地方,参数和返回地址如何传递过去呢?
比如用户态中调用,A调用B B调用C C调用D 然后返回 C B A
后进先出的过程,这就是基于栈的调用方式
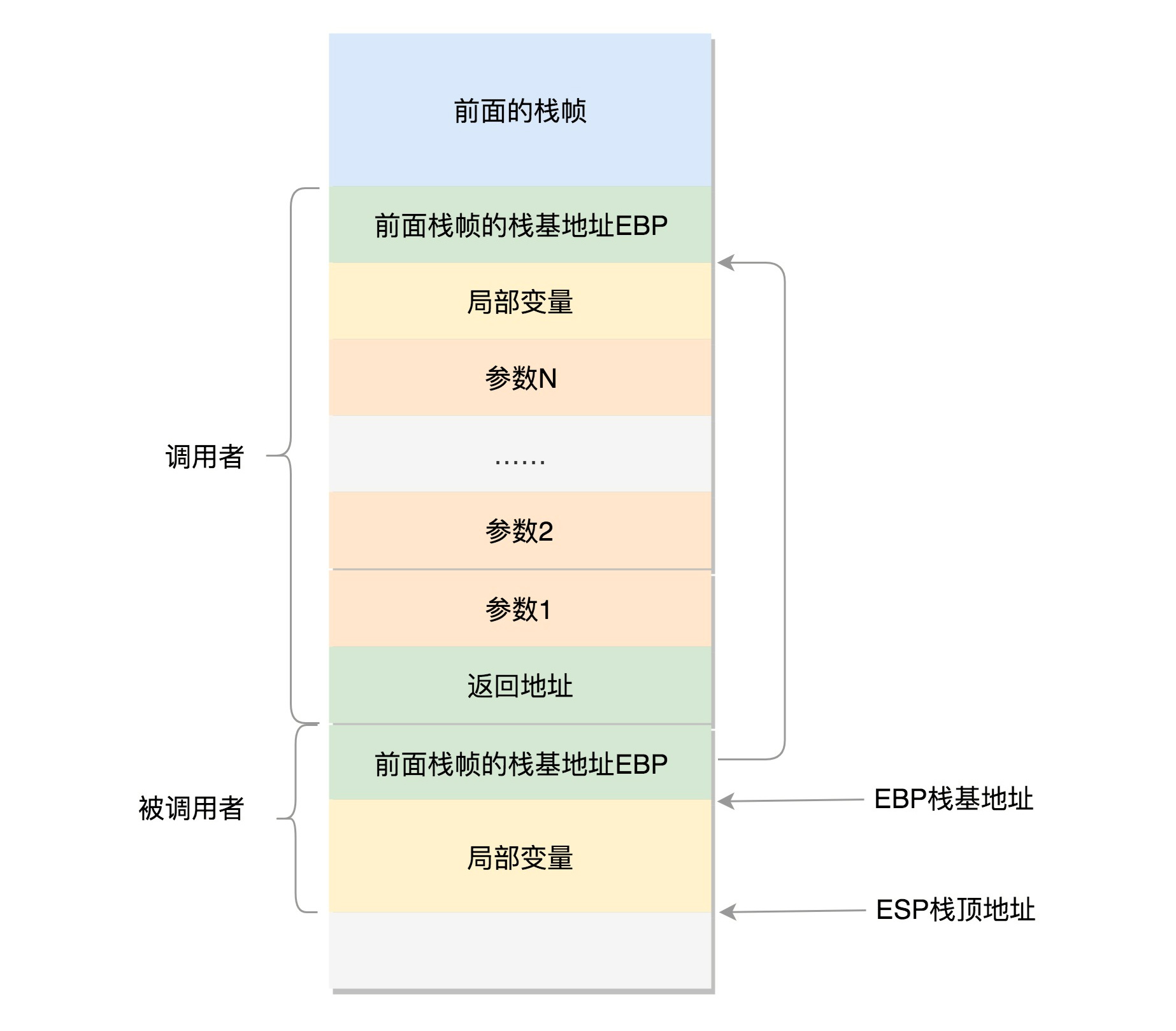
32位操作系统的情况,在CPU中 ESP是栈顶探针寄存器,入栈操作Push和出栈操作Pop指令
自动调整ESP的值,另外有一个寄存器EBP,栈基地址指针寄存器,指向当前栈帧的最底部
A调用B A栈中包含A函数的局部变量 以及调用B的时候传给B的参数
返回A的地址,这个地址应该入栈,就是形成了A的栈帧,然后是B的栈帧部分
先保存的是A栈帧的栈底位置,就是EBP,因为B中获取函数A的参数,就是通过这个指针获取的,最后保存的就是B的局部变量
B返回的时候,返回值保存在EAX寄存器中,从栈中弹出返回地址,指令跳转回去,参数也从栈中弹出,继续执行A
对于64位系统,模式多少不一样,因为64位系统的寄存器的数目比较多,rax保存函数调用的返回结果,栈顶指针寄存器变成了rbp,指向当前栈帧的其实位置
参数传递利用了rdi rsi rdx rcx r8 r9 6个寄存器,传递函数调用的时候6个函数,超过6个,需要放入栈中
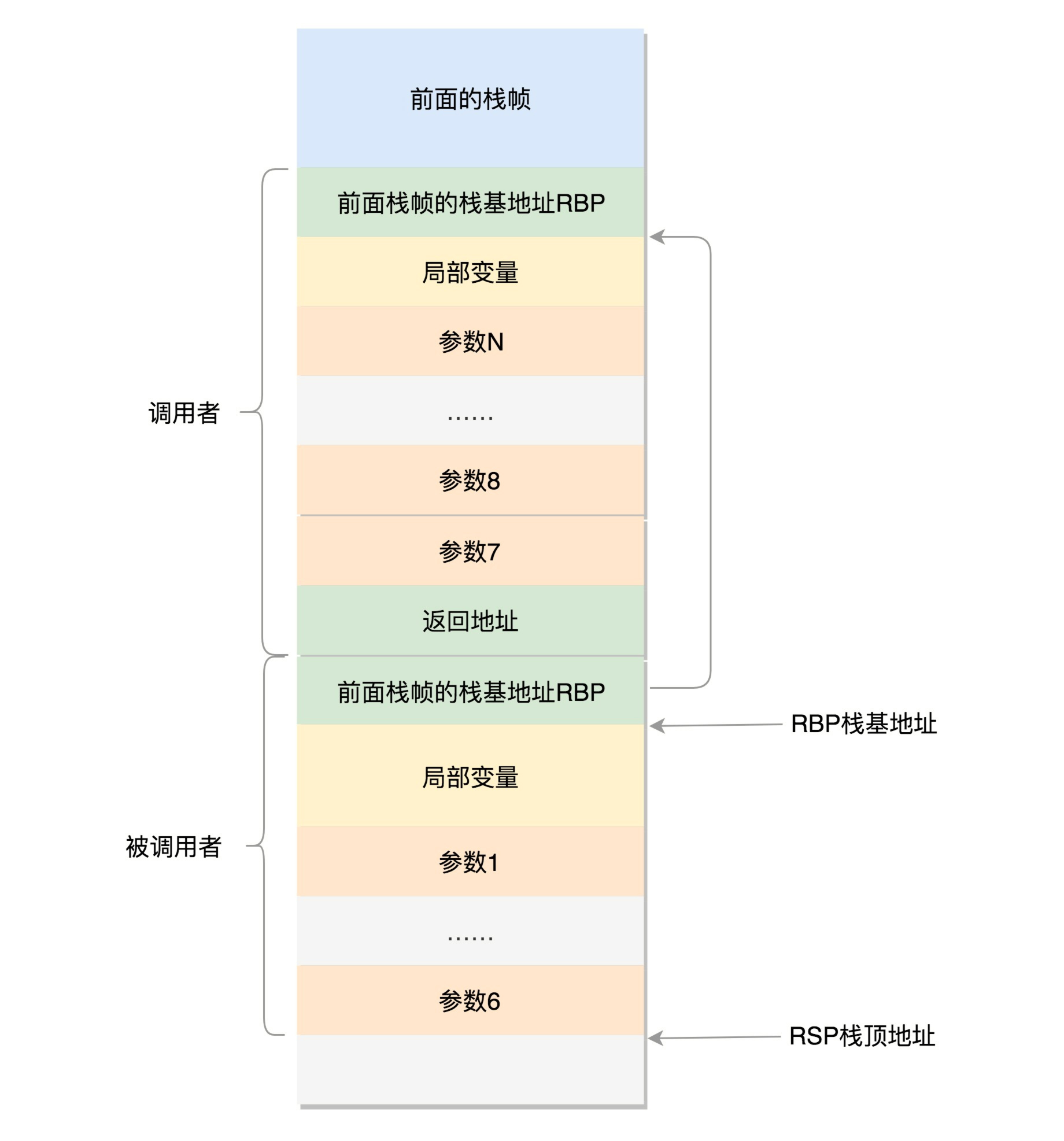
上面我们通过系统调用,从进程的内存空间到内核中了,内核中有各种各样函数调用,基本上也是栈的调用机制
上面的变量stack,就是内核栈,派上了用场
Linux给每个task都分配了内核栈,32位系统和64位不一样
32位上,一个PAGE_SIZE是4K,左移一位就是乘以2,8K
64位上,在PAGE_SIZE基础上左移两位,就是16K,起始地址必须是8192的整数倍
内核栈结构如下
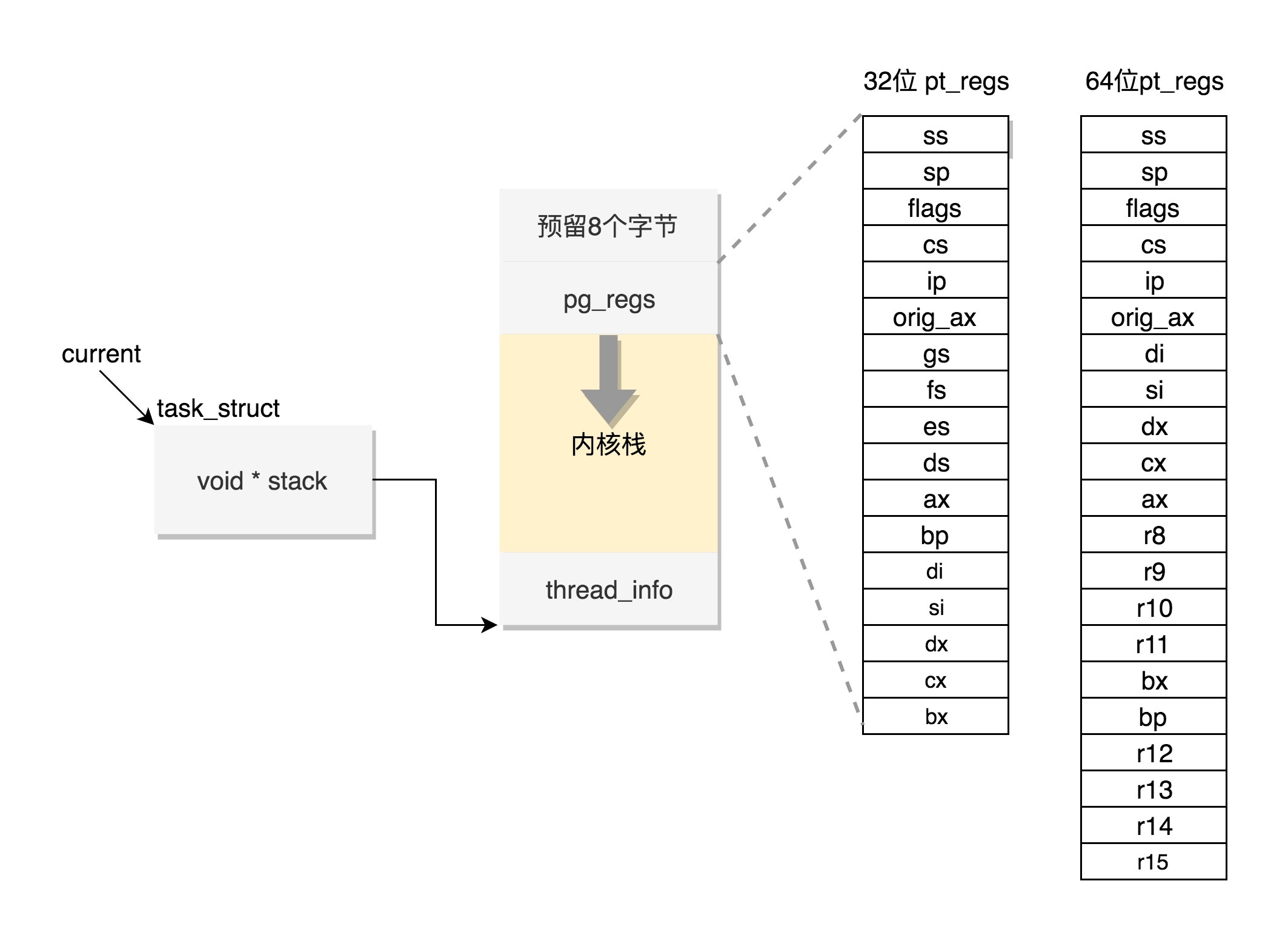
最低位置,是一个thread_info结构,结构是task_struct结构的补充,和体系结构相关的,都放在thread_info中
内核中,将thread_info和stack放在一起,形成一个union
也就是我们的进程数据结构
内核栈的最高地址栈,存放的是另一个结构pt_regs,定义如下,32位和64位的定义不一样
| #ifdef __i386__
struct pt_regs { unsigned long bx; unsigned long cx; unsigned long dx; unsigned long si; unsigned long di; unsigned long bp; unsigned long ax; unsigned long ds; unsigned long es; unsigned long fs; unsigned long gs; unsigned long orig_ax; unsigned long ip; unsigned long cs; unsigned long flags; unsigned long sp; unsigned long ss; }; #else struct pt_regs { unsigned long r15; unsigned long r14; unsigned long r13; unsigned long r12; unsigned long bp; unsigned long bx; unsigned long r11; unsigned long r10; unsigned long r9; unsigned long r8; unsigned long ax; unsigned long cx; unsigned long dx; unsigned long si; unsigned long di; unsigned long orig_ax; unsigned long ip; unsigned long cs; unsigned long flags; unsigned long sp; unsigned long ss; /* top of stack page */ }; #endif |
从用户态到内核态的时候,第一件事,就是将用户态的CPU上下文保存到这个结构中,然后从内核系统调用返回的时候,才能让进程在刚刚的地方继续运行下去
如果有一个task_struct的stack指针在手,可以通过下面的函数找到线程内核栈
| static inline void *task_stack_page(const struct task_struct *task)
{ return task->stack; } |
task_struct可以获取到对应的pt_regs
| /*
* TOP_OF_KERNEL_STACK_PADDING reserves 8 bytes on top of the ring0 stack. * This is necessary to guarantee that the entire “struct pt_regs” * is accessible even if the CPU haven’t stored the SS/ESP registers * on the stack (interrupt gate does not save these registers * when switching to the same priv ring). * Therefore beware: accessing the ss/esp fields of the * “struct pt_regs” is possible, but they may contain the * completely wrong values. */ #define task_pt_regs(task) \ ({ \ unsigned long __ptr = (unsigned long)task_stack_page(task); \ __ptr += THREAD_SIZE – TOP_OF_KERNEL_STACK_PADDING; \ ((struct pt_regs *)__ptr) – 1; \ }) |
task_struct找到内核栈的开始位置,加上了Thread_SIZE到了最后的位置,然后转换为struct_pt_regs,减一,减少一位pt_regs位置,到了结构的首地址.
里面有一个TOP_OF_KERNEL_STACK_PADDING
其中,32位上是8,其他是0,为何,因为压栈有两种情况,CPU利用ring进行区分,从而Linux可以区分内核态和用户态
第一种情况,涉及用户态到内核态的系统调用来说,设计权限的变化,压栈保存SS ESP寄存器,占用8个byte
不涉及权限的变化,不会压栈这8个byte,使得两个情况不兼容,没有压栈访问必然会保存,所以预留在此
64位上改为了定长的
如果有task_struct在手,可以轻松获得内核栈和内核寄存器
内核栈找task_struct
在某个CPU上执行的进程,想知道自己的task_struct在哪,怎么办?
交给了thread_info
| struct thread_info {
struct task_struct *task; /* main task structure */ __u32 flags; /* low level flags */ __u32 status; /* thread synchronous flags */ __u32 cpu; /* current CPU */ mm_segment_t addr_limit; unsigned int sig_on_uaccess_error:1; unsigned int uaccess_err:1; /* uaccess failed */ }; |
其中的task指针指向了task_struct
thread_info的位置就是内核栈的最高位置,减去THREAD_SIZE,就到了thread_info的起始位置
最后就只剩下一个flags
如何获取到当前运行中的task_struct内?
CPU运行的task_struct不通过thread_info获取到的,直接放在Per CPU中了,Per CPU就是为了每个CPU构造一个变量的副本,多个CPU各自操作自己的副本,互不干涉,当前进程变量的current_task就是声明为了Per CPU
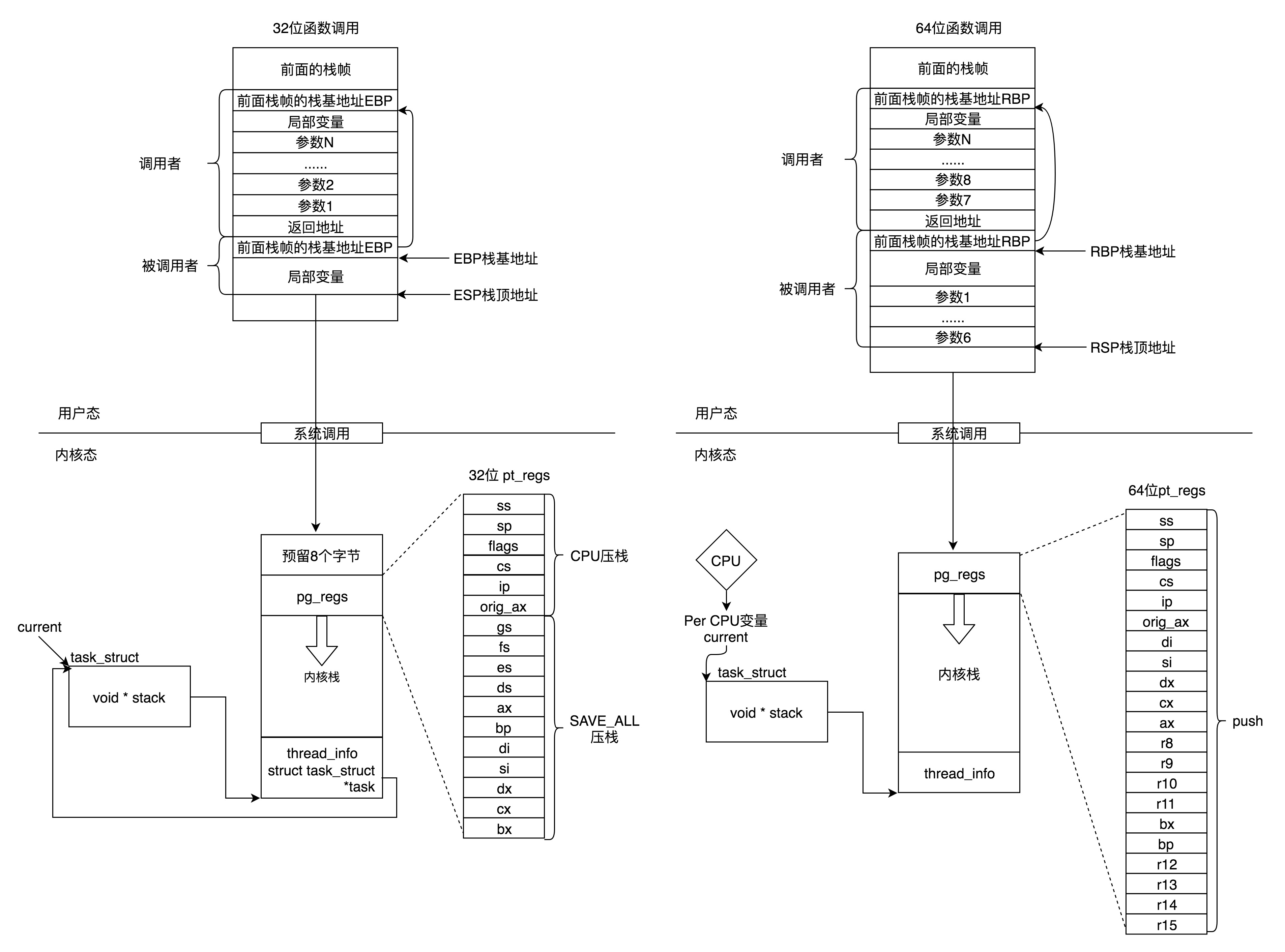 总结一下处理
总结一下处理
在用户态,应用程序至少进行了一次函数调用.32位和64的传递参数方式不同,32位的是函数栈,64位用前6个参数寄存器,其他用函数栈
内核态,32位和64位都使用内核栈
内核态中,32位和64位的内核栈和task_struct的关系不同,32位主要靠thread_info,64位主要靠Per-CPU变量