我们说明了一些功能性需求的同时,满足了易用,易扩展,灵活,低延迟,高容错的非功能需求,我们借鉴了Spring的低侵入,松耦合,约定优于配置的设计思想,借鉴了Mybatis通过Mybatis-Spring类库将框架的易用性做到了极致
现在,我们针对这个限流框架,进行第一版的简单实现,尽可能的满足,设计思想,设计原则,体现一些模式,写出易读,易于扩展,易于维护,灵活,简洁,可复用的代码
v1版本功能的需求
优秀的代码,是重构出来的,复杂的代码也是慢慢堆砌出来的,所以我们先来一个包含核心功能,基本功能的v1版本
针对上面的需求和设计,我们重新梳理一下,那些功能放在这个版本实现
在第一个版本,我们只支持HTTP接口的限流,对于其他版本的限流暂不支持,配置文件只支持YAML,对于限流算法,只支持固定时间的窗口算法,对于限流本身,只支持单机限流
并且在开发的同时,考虑保留扩展点,轻松的拓展出新的限流算法,限流模式,限流规则和数据源
V1版本原型
项目实现中实现等于面向对象设计加实现,而面向对象设计和实现一般可以分为四个步骤,划分了职责识别类,定义属性和方法,定义类和类之间的交互关系,组装类并提供执行入口
我们先按照这个思想,进行最小原型代码的设计和实现
先进行类的职责划分,简单划分为如下的类
| com.xzg.ratelimiter
–RateLimiter com.xzg.ratelimiter.rule –ApiLimit –RuleConfig –RateLimitRule com.xzg.ratelimiter.alg –RateLimitAlg |
首先是RateLimiter类,代码如下
| public class RateLimiter {
private static final Logger log = LoggerFactory.getLogger(RateLimiter.class); // 为每个api在内存中存储限流计数器 private ConcurrentHashMap<String, RateLimitAlg> counters = new ConcurrentHashMap<>(); private RateLimitRule rule; public RateLimiter() { // 将限流规则配置文件ratelimiter-rule.yaml中的内容读取到RuleConfig中 InputStream in = null; RuleConfig ruleConfig = null; try { in = this.getClass().getResourceAsStream(“/ratelimiter-rule.yaml”); if (in != null) { Yaml yaml = new Yaml(); ruleConfig = yaml.loadAs(in, RuleConfig.class); } } finally { if (in != null) { try { in.close(); } catch (IOException e) { log.error(“close file error:{}”, e); } } } // 将限流规则构建成支持快速查找的数据结构RateLimitRule this.rule = new RateLimitRule(ruleConfig); } public boolean limit(String appId, String url) throws InternalErrorException { ApiLimit apiLimit = rule.getLimit(appId, url); if (apiLimit == null) { return true; } // 获取api对应在内存中的限流计数器(rateLimitCounter) String counterKey = appId + “:” + apiLimit.getApi(); RateLimitAlg rateLimitCounter = counters.get(counterKey); if (rateLimitCounter == null) { RateLimitAlg newRateLimitCounter = new RateLimitAlg(apiLimit.getLimit()); rateLimitCounter = counters.putIfAbsent(counterKey, newRateLimitCounter); if (rateLimitCounter == null) { rateLimitCounter = newRateLimitCounter; } } // 判断是否限流 return rateLimitCounter.tryAcquire(); } } |
RateLimiter的职责,就是先去读取限流规则的配置文件,读取后,创建为一个可以根据接口查询的数据结构,并且,还提供了直接使用的limit接口
然后是RuleConfig这个类
| public class RuleConfig {
private List<UniformRuleConfig> configs; public List<AppRuleConfig> getConfigs() { return configs; } public void setConfigs(List<AppRuleConfig> configs) { this.configs = configs; } public static class AppRuleConfig { private String appId; private List<ApiLimit> limits; public AppRuleConfig() {} public AppRuleConfig(String appId, List<ApiLimit> limits) { this.appId = appId; this.limits = limits; } //…省略getter、setter方法… } } |
| public class ApiLimit {
private static final int DEFAULT_TIME_UNIT = 1; // 1 second private String api; private int limit; private int unit = DEFAULT_TIME_UNIT; public ApiLimit() {} public ApiLimit(String api, int limit) { this(api, limit, DEFAULT_TIME_UNIT); } public ApiLimit(String api, int limit, int unit) { this.api = api; this.limit = limit; this.unit = unit; } // …省略getter、setter方法… } |
RuleCofing中嵌套了另外的两个类,AppRuleConfig和ApiLimit,这三个类和配置文件的三层嵌套结构完全对应
然后是RateLimitRule这个类
有了RuleConfig存储流规则,为何还要RateLimitRule类呢?
这就是为了支持频繁的查询接口的对应的限流规则,为了尽可能的查询速度,我们需要将限流规则组成快速查询的数据结构,我们使用了字符串匹配数据结构,如下所示,左边的限流规则对应到了Trie树中,就是右边的样子
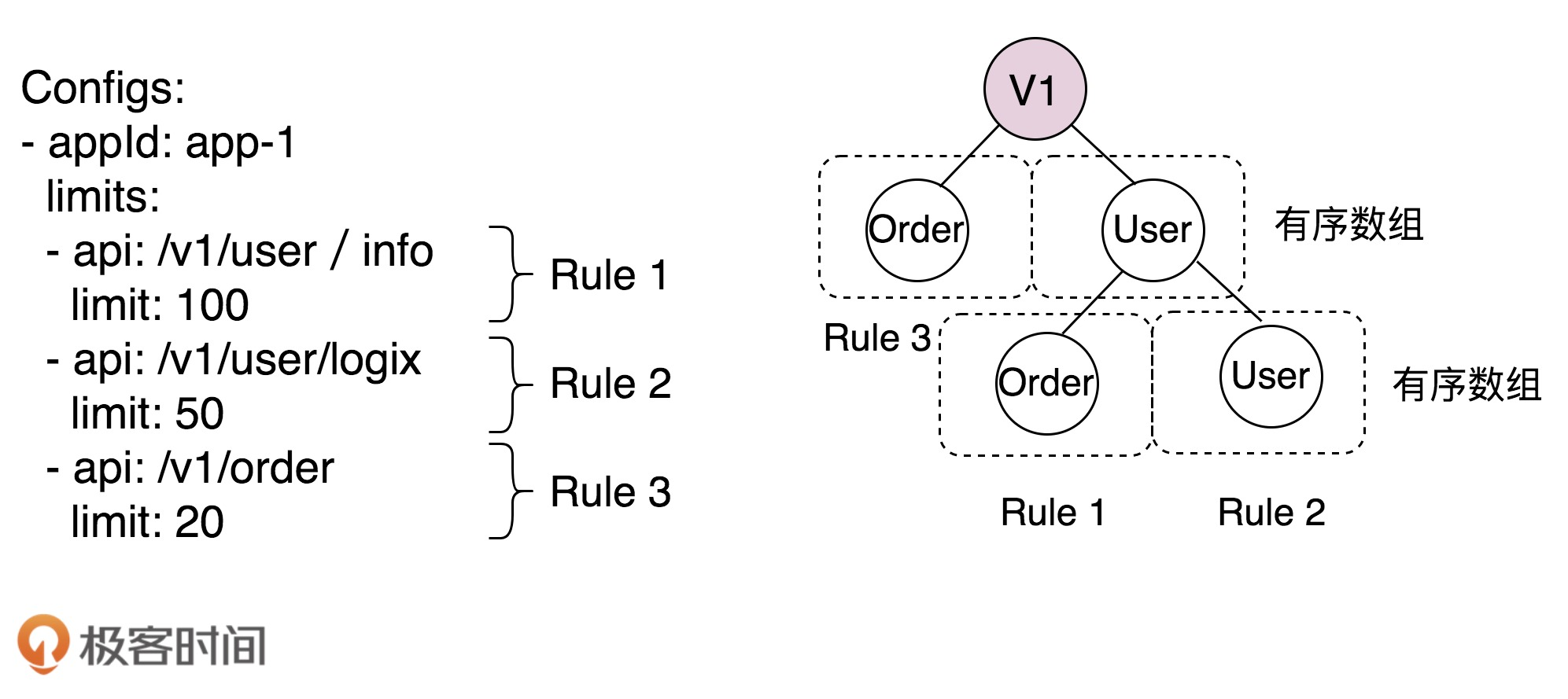
RateLimitRule的实现比较复杂,我们利用了字符串匹配树
使用方式如下
| public class RateLimitRule {
public RateLimitRule(RuleConfig ruleConfig) { //… } public ApiLimit getLimit(String appId, String api) { //… } } |
最后是限流算法的实现类
RateLimitAlg类
这个类是限流算法实现类,每个接口都要在内存中对应一个RateLimitAlg对象,记录在当前时间窗口被访问的次数,然后进行计算
| public class RateLimitAlg {
/* timeout for {@code Lock.tryLock() }. */ private static final long TRY_LOCK_TIMEOUT = 200L; // 200ms. private Stopwatch stopwatch; private AtomicInteger currentCount = new AtomicInteger(0); private final int limit; private Lock lock = new ReentrantLock(); public RateLimitAlg(int limit) { this(limit, Stopwatch.createStarted()); } @VisibleForTesting protected RateLimitAlg(int limit, Stopwatch stopwatch) { this.limit = limit; this.stopwatch = stopwatch; } public boolean tryAcquire() throws InternalErrorException { int updatedCount = currentCount.incrementAndGet(); if (updatedCount <= limit) { return true; } try { if (lock.tryLock(TRY_LOCK_TIMEOUT, TimeUnit.MILLISECONDS)) { try { if (stopwatch.elapsed(TimeUnit.MILLISECONDS) > TimeUnit.SECONDS.toMillis(1)) { currentCount.set(0); stopwatch.reset(); } updatedCount = currentCount.incrementAndGet(); return updatedCount <= limit; } finally { lock.unlock(); } } else { throw new InternalErrorException(“tryAcquire() wait lock too long:” + TRY_LOCK_TIMEOUT + “ms”); } } catch (InterruptedException e) { throw new InternalErrorException(“tryAcquire() is interrupted by lock-time-out.”, e); } } } |
这就是V1版本的基本代码,虽然只有200多行,但是实现了V1版本中的规划功能,从代码质量角度来看,还有很多优化的地方
本章重点:
结合SOLID原则, DRY原则,KISS原则, LOD迪米特法则,基于接口而非实现编程,高内聚松耦合等经典设计思想和原则,以及编程规则,从以上方面去优化
课后思考:
1.针对这个代码,如果去做code review,能发现什么问题?
2.支持自定义的限流规则配置文件名和路径,如何借鉴Spring的设计思路,来借鉴到限流框架中
1.可以将配置类和实际的拦截器接口实现类进行相分离,然后在实现类里面去执行查找接口拦截规则并执行对应接口的Alg,对于Alg实现类,抽取出接口,方便自定义算法,并且在内部实现诸如漏桶算法的实现,利用用户配置和策略模式来进行实现
2.对于这个问题,可以参考Spring给出的Resource接口,并给出了基于不同的读取方式的实现类,而且为了简化开发,给出ResourceLoader,并且还有着DefaultResourceLoader,可以根据传入前缀,来创建不同的Resource,对于字符串查找树这个实现,我是真的没想到,不过可以在这个基础上,借鉴HashMap的实现,在api接口足够少的时候,使用简单的map保存,多了再转为树
再往深了说,BeanFactory需要传入资源生成对应的实体Bean,而为了简化开发,一般是使用ApplicationContext来初始化Bean,需要传入一个资源给ApplicationContext,并在里面动态解析生成Bean对象,这样的流程,值得我们的框架借鉴点有很多