我们来说下Kubernetes的默认调度器
在Kubernetes项目中,默认调度器的职责,是为一个新创建的Pod,寻找一个合适的节点Node
这个最合适的含义,包含,从集群中根据调度算法选出所有可以运行这个Pod的节点
然后根据调度算法,选出一个最为合适的节点Node
那么在具体的调度过程中,首先调度一组名为Predicate的调度算法,检查每个Node,然后调用一组叫做Priority的调度算法,来给上一组的Node进行打分,获得分数最高的Node
调度器对一个Pod调度成功,就会在spec.nodeName字段上填上调度结果的节点名字
具体的调度机制如下
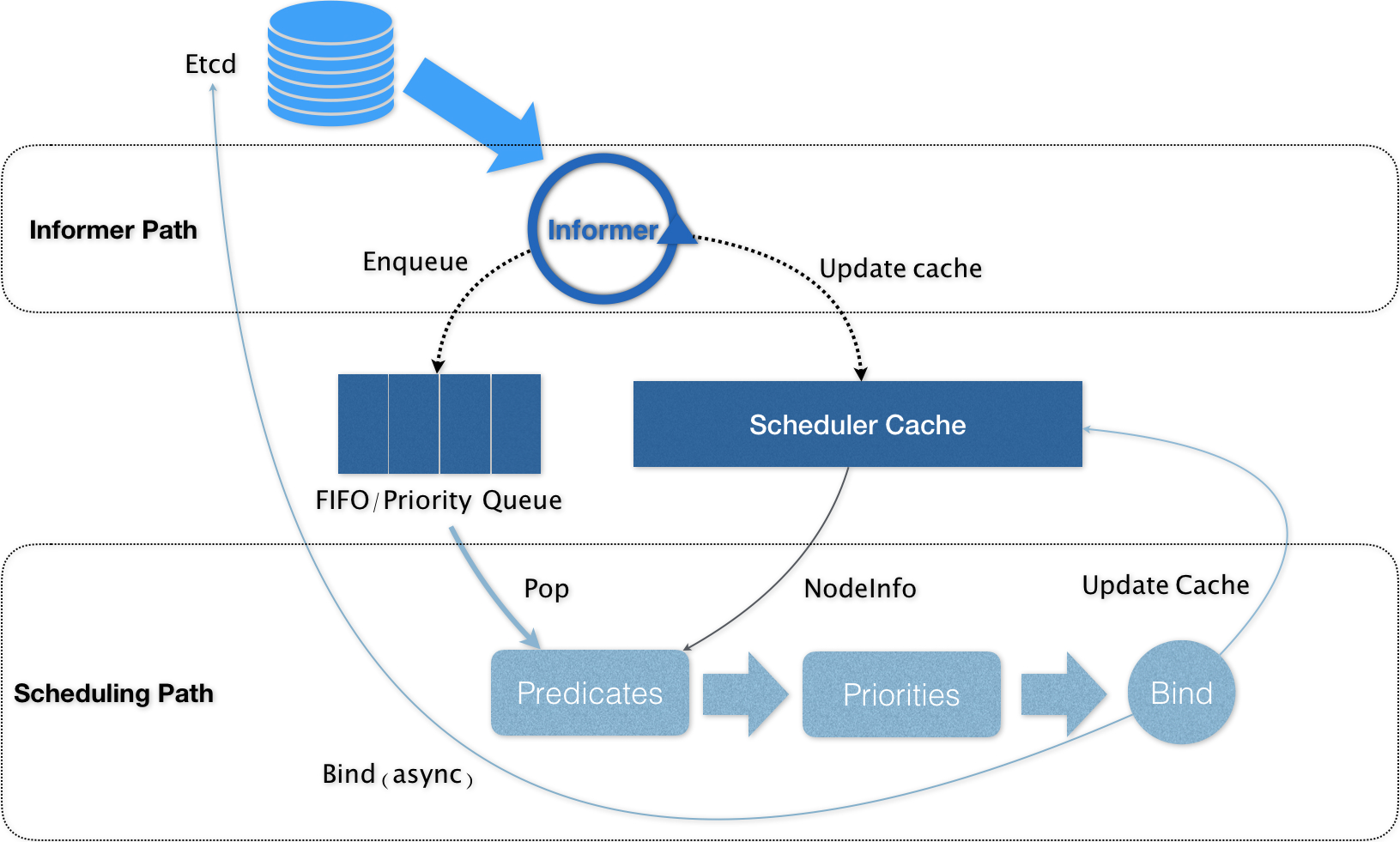
其实这就是两个相互独立的控制循环
第一个控制循环,称为Informer Path 主要目的,是启动一系列的Informer,来监视Etcd中Pod Node Service 等API对象的变化,比如,一个待调度Pod被创建出来了,就会通过Pod Informer的Handler,添加入调度队列
在默认情况下,我们的调度队列是一个PriorityQueue 优先级队列,当集群信息发生变化时候,会对调度队列中的内容进行一些特殊操作
并且,还能利用上缓存,进行更高效的Cache化
第二个控制循环,则是调度器负责Pod调度的主循环,称为Scheduling Path 主要逻辑,是不断的从调度队列中出队一个Pod,然后调用Predicates算法进行过滤,这个过滤得到了一组Node,就是所有可以运行Pod的宿主机列表,Predicates需要的Node信息,是缓存拿到的,提高执行效率
接下来,调度器就会调用Priorities算法为上述的列表中的Node打分,分数从0到10,得分最高的Node,就会作为这次调度的结果
调度算法执行完成后,调度器就需要在Pod对象的nodeName字段的值,修改为上述的Node名字,这一部分就称为Bind
为了不在关键调度中访问远程APIServer,默认调度器在Bind阶段,只会更新Scheduler Cache中的Pod和Node信息,这种基于乐观假设的API对象的更新方式,在Kubernetes中被称为Assume
Assume之后,会另起一个线程向APIServer发起更新Pod请求,如果这次的Bind过程失败了,也并没有太大关系,等Schedule Cache同步后也会回退回去
正式基于上述Kubernetes调度器的乐观绑定设计,一个新的Pod调度完成在某个节点运行起来之前,这个节点上的Kubelet还会通过一个叫做Admit的操作来验证一下是可以运行,这个是交给本地Kubelet进行GeneralPredicates的基础调度算法进行计算的
而调度器中,会启动多个Goroutine进行并发的执行Predicates算法,提高执行效率,Priorities会以MapReduce为方式并行的进行计算并进行汇总,在此过程中,会尽可能的避免全局的竞争资源,避免了使用锁进行同步带来的巨大性能损耗
所以,在这种思想的知道下,我们看一下上面的调度原理图,会发现,Kuberentes调度器只有对调度队列或者Schedule Cache进行操作的时候,才需要加锁,这部分的操作,都不在Schedule Path算法的执行路径上
这也是Kubernetes项目发展出的Cache话的趋势,增强了Kubernetes调度器性能
伴随着Kubernetes项目发展到今天,KuBernetes的默认调度器越来越小型化,将组件轻量化,接口化,插件化,我们有了CRI CNI CRD CSI等层级的扩展能力,Kuberneteds调度器现在还没有暴露出来,但是还是会在多次重构后,将技术债进行清理完成后,进行暴露出来.
而其中的默认调度器,将会往着可扩展性进行发展,其中的目标可以如下的表示
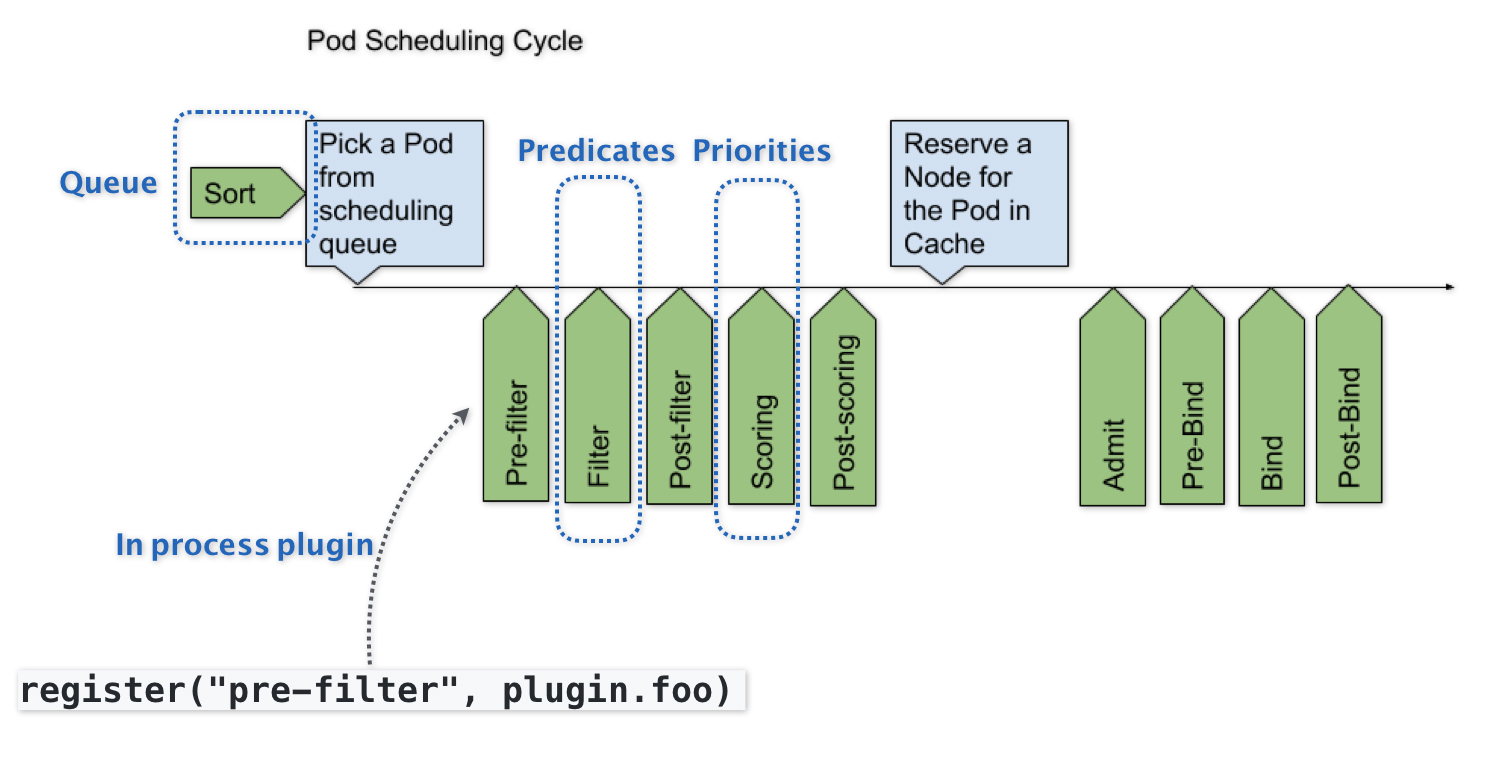
其中Scheduler Framework的设计目的,就是为了在调度器生命周期的各个关键点上,为用户暴露出可以扩展或者实现的接口,提供用户自定义调度器的能力
而这些实现,利用的是Go语言的插件机制,需要在编译的时候选择性的编译进去
那么,在本章中,我们讲解了Kubernetes默认的调度器的设计和实现,调度这件事,是需要进行多个插件协调工作,获得的一个最终结果
课后思考
Kubernetes的默认调度器和Mesos 两级调度器,有何异同
对应的Pod的调度过程是一个串行的调度过程,而非是并行的
而对于上面的比较,则是Messos二级调度是资源调度和业务调度分开,可以让用户自定义自己的调度器并且注册到messos资源调度框架即可,但是资源调度和业务调度框架分开,导致无法做到细粒度的调用,K8s则是两者统一调度,但是对于扩展性则比较差