深入解析声明API值编写自定义控制器
然后我们说下Kubernetes中声明式API的实现原理,并且我们添加了一个Network对象的实例,讲述了在kubernetes里添加API资源的过程
我们继续编写剩下的工作,为Network自定义API对象编写一个自定义控制器Custom Controller
声明式API 并不像 命令式API有着严格的执行逻辑,这就需要基于声明式API业务功能实现,能够根据控制器模式来监视API对象的变化,然后决定执行执行的具体工作
编写自定义的控制器过程包含,编写main函数,编写自定义控制器的定义,以及编写控制器的业务逻辑三个部分
我们首先定义这个自定义控制器的main函数
main函数的主要工作,就是定义并初始化一个自定义控制器,然后启动其,这部分代码的主要内容如下
|
func main() {
… cfg, err := clientcmd.BuildConfigFromFlags(masterURL, kubeconfig) … kubeClient, err := kubernetes.NewForConfig(cfg) … networkClient, err := clientset.NewForConfig(cfg) … networkInformerFactory := informers.NewSharedInformerFactory(networkClient, …) controller := NewController(kubeClient, networkClient, networkInformerFactory.Samplecrd().V1().Networks()) go networkInformerFactory.Start(stopCh) if err = controller.Run(2, stopCh); err != nil { glog.Fatalf(“Error running controller: %s”, err.Error()) } } |
第一步,首先是利用提供的master配置,APIServer的地址端口和kubeconfig的路径,创建一个Kubernetes的client和Network对象的client
如果没有提供Master配置,那么会使用一种名为InClusterConfig的方式来创建这个client,这会假设自定义的控制是以Pod的方式运行在Kubernetes中的,而且别忘了,所有的Pod都会挂载Kuberenetes的默认ServiceAccount,来进行访问APIServer的权限声明
第二步,main函数为Network对象创建一个叫做InformerFactory的工厂,然后生成Network对象的Informer,传递给控制器
第三步,main函数启动上述的Informer,然后执行controller.Run,启动自定义控制器
Informer是什么东西呢?
我们首先说下自定义控制器的工作原理,在一个Kubernetes中,一个自定义控制器的工作流程,可以用下面的流程图来进行表示
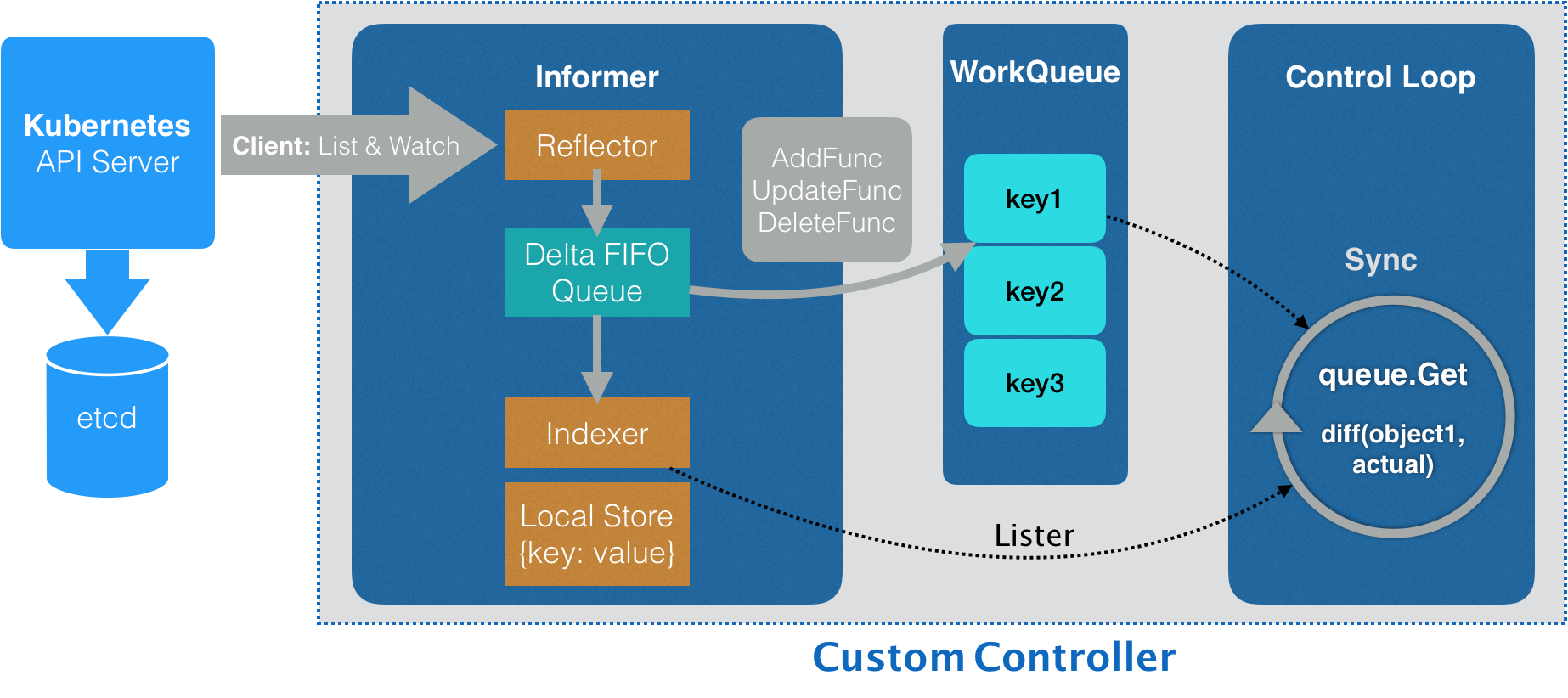
第一件事,就是从Kubernetes中的APIServer中获取到关心的对象,就是定义的Network对象
这个操作,是靠一个叫做Informer的代码库完成的,Informer和API对象是一一对应的,所以我们传递给自定义控制器的,正式一个Network对象的Informer
创建Informer工厂的时候,需要传递一个networkClient
事实上,Network Informer使用的正是这个networkClient跟APIServer进行连接建立,不过真正维护这个连接的,是Informer使用的Reflector包
Reflector使用的是一种叫做ListAndWatch的方法,来获取并监听这些Network对象实例的变化
在这个ListAndWatch的机制下,一旦APIServer有了新的Network实例被创建,删除 更新,Reflector都会收到一个事件通知,这时候,这个事件和对应的API对象的组合,就会被称为增量,放在一个Delta FIFO Queue 增量先进先出队列中
然后Informe会不断的从这个Delta FIFO Queue读取Pop增量,然后每拿到一个增量,Informer就会判断这个增量的事件类型,然后创建或者更新本地对象的缓存,这个缓存在Kubernetes中被称为Stroe
如果事件类型是Added 添加对象,那么Informer就会通过一个叫做Indexer的库把增量的API对象保存的本地缓存,并为之创建索引,相反,如果增量的事件类型是Deleted,那么Informer就会从本地缓存中删除这个对象
同步本地缓存的工作,是Informer的第一个职责
而第二个职责,是根据这些事件的类型,触发事先定义好的ResourceEventHandler,这些Handler,需要在创建控制器的时候注册给它对应的Informer
然后,我们就编写这个控制器的定义,主要的内容如下
|
func NewController(
kubeclientset kubernetes.Interface, networkclientset clientset.Interface, networkInformer informers.NetworkInformer) *Controller { … controller := &Controller{ kubeclientset: kubeclientset, networkclientset: networkclientset, networksLister: networkInformer.Lister(), networksSynced: networkInformer.Informer().HasSynced, workqueue: workqueue.NewNamedRateLimitingQueue(…, “Networks”), … } networkInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{ AddFunc: controller.enqueueNetwork, UpdateFunc: func(old, new interface{}) { oldNetwork := old.(*samplecrdv1.Network) newNetwork := new.(*samplecrdv1.Network) if oldNetwork.ResourceVersion == newNetwork.ResourceVersion { return } controller.enqueueNetwork(new) }, DeleteFunc: controller.enqueueNetworkForDelete, return controller } |
之前main函数创建了两个client kubeclientse和networkclientset,在这个代码中,使用这两个client和之前的Informer,初始化了自定义控制器
这个自定义控制器中,还有一个工作队列,就是work queue,这就是示意图中的workqueue,这个工作队列的作用,负责同步Infromer和控制循环之间的数据
然后为这个Informer注册了三个Handler,AddFunc UpdateFunc DeleteFunc,分别对应着添加 更新 删除的事件,而具体的处理操作,就是讲该事件的对应API对象加入工作队列中
实际入队的并不是API对象本身,而是其Key,就是API对象的<namespace>/<name>
我们在后面编写的控制循环,会不断的从这个工作队列中拿到这些对象
这样,所谓的Informer,就是一个带有本地缓存和索引机制的,可以注册EventHandler的client,是自定义控制器和APIServer进行数据同步的重要组件
或者说,Informer通过一种叫做ListAndWatch的方法,将APIServer的API对象缓存在了本地,并且负责更新和维护这个缓存
ListAndWatch的具体做法,就是通过APIServer的LIST API获取到所有最新版本的API对象,然后通过WATCH API来监听这些API对象的变化
然后根据监听到的事件变化,Informer来实时的更新本地的缓存,调用本地事件对应的EventHandler
在此过程中,每次经过resyncPeriod指定的时间,Informer维护的本地缓存,也会使用最新一次List返回的结果强制更新一次,从而保证缓存的有效性,在Kubernetes中,这个缓存强制更新操作就是resync
需要注意的是,这个定时的resync的操作,也会触发Informer注册的更新时间,但此时,如果这个事件对应的Network对象实际上没发生变化,就是新 旧两个Network对象的ResourceVersion是一样的,那么Informer就不需要再对这个更新事件进行进一步的处理了
这样就是UpdateFuc方法中,进行了版本变化的判断
最后,就是后面的控制循环 Control Loop部分,也是main函数最后掉用的Controller.Run()启动的控制
在main函数的最后掉用Controller.Run()启动的控制循环,主要内容如下所示
|
func (c *Controller) Run(threadiness int, stopCh <-chan struct{}) error {
… if ok := cache.WaitForCacheSync(stopCh, c.networksSynced); !ok { return fmt.Errorf(“failed to wait for caches to sync”) } … for i := 0; i < threadiness; i++ { go wait.Until(c.runWorker, time.Second, stopCh) } … return nil } |
启动控制循环的逻辑非常简单
首先,等待Informer完成Sync的同步操作
然后通过goroutine启动一个无限循环的任务
这个无限循环的任务的每一个循环周期,执行的就是我们的关心的业务逻辑
我们尝试的编写这个业务逻辑
|
func (c *Controller) runWorker() {
for c.processNextWorkItem() { } } func (c *Controller) processNextWorkItem() bool { obj, shutdown := c.workqueue.Get() … err := func(obj interface{}) error { … if err := c.syncHandler(key); err != nil { return fmt.Errorf(“error syncing ‘%s’: %s”, key, err.Error()) } c.workqueue.Forget(obj) … return nil }(obj) … return true } func (c *Controller) syncHandler(key string) error { namespace, name, err := cache.SplitMetaNamespaceKey(key) … network, err := c.networksLister.Networks(namespace).Get(name) if err != nil { if errors.IsNotFound(err) { glog.Warningf(“Network does not exist in local cache: %s/%s, will delete it from Neutron …”, namespace, name) glog.Warningf(“Network: %s/%s does not exist in local cache, will delete it from Neutron …”, namespace, name) // FIX ME: call Neutron API to delete this network by name. // // neutron.Delete(namespace, name) return nil } … return err } glog.Infof(“[Neutron] Try to process network: %#v …”, network) // FIX ME: Do diff(). // // actualNetwork, exists := neutron.Get(namespace, name) // // if !exists { // neutron.Create(namespace, name) // } else if !reflect.DeepEqual(actualNetwork, network) { // neutron.Update(namespace, name) // } return nil } |
在这个执行周期中,先从工作队列中出队了一个成员,也就是一个KEY,Network对象的namespace/name
然后,在syncHandler方法中,使用的这个Key,尝试从Informer维护的缓存中拿到了对应的Network对象
可以看到,在这里,我使用了networksLister来尝试获取到Key对应的Network对象,这个操作,就是访问本地缓存的索引,实际上,在Kubernetes源码中,可以看到控制器从各个Lister中获取对象,比如podlister,nodeLister,都是利用了Informer和缓存机制
控制循环中,在缓存中这个对象不存在,那么就意味着这个对象已经被缓存中删除了,也意味着从ApiServer中删除了,所以,尽管这个队列中有这个Key,但是对应的Network对象已经被删除了
这时候,就要调用Neutron的API,将这个Key对应的Neutron网络从真实的集群中删除掉
如果能够获取到对应的Network对象,就可以执行控制器模式中的对比和实际状态的逻辑了
这就需要从真实的Neutron网络中获取到实际状态,然后对比ApiServer提供期望状态,进行不同的操作
先查询这个Network在真实的网络中是否存在,如果不存在,就是一个典型的create操作
如果存在,就要读取这个真实网络的信息,判断是否和现在信息一致,从而决定是否需要更新这个已经存在的真实网络
那么一个完整的自定义API对象和其对应的自定义控制器,就编写完了
然后就可以编译并启动这个项目了
# Clone repo
$ git clone https://github.com/resouer/k8s-controller-custom-resource$ cd k8s-controller-custom-resource
### Skip this part if you don’t want to build
# Install dependency
$ go get github.com/tools/godep
$ godep restore
# Build
$ go build -o samplecrd-controller .
$ ./samplecrd-controller -kubeconfig=$HOME/.kube/config -alsologtostderr=true
I0915 12:50:29.051349 27159 controller.go:84] Setting up event handlers
I0915 12:50:29.051615 27159 controller.go:113] Starting Network control loop
I0915 12:50:29.051630 27159 controller.go:116] Waiting for informer caches to sync
E0915 12:50:29.066745 27159 reflector.go:134] github.com/resouer/k8s-controller-custom-resource/pkg/client/informers/externalversions/factory.go:117: Failed to list *v1.Network: the server could not find the requested resource (get networks.samplecrd.k8s.io)
…
这样,配合创建好的Network的CRD,这个操作就完成了
就可以直接创建一个Network的对象
$ cat example/example-network.yaml
apiVersion: samplecrd.k8s.io/v1
kind: Network
metadata:
name: example-network
spec:
cidr: “192.168.0.0/16”
gateway: “192.168.0.1”
$ kubectl apply -f example/example-network.yaml
network.samplecrd.k8s.io/example-network created
在执行上面的yaml的文件后,就可以查看对应的控制器的输出
…
I0915 12:50:29.051349 27159 controller.go:84] Setting up event handlers
I0915 12:50:29.051615 27159 controller.go:113] Starting Network control loop
I0915 12:50:29.051630 27159 controller.go:116] Waiting for informer caches to sync
…
I0915 12:52:54.346854 25245 controller.go:121] Starting workers
I0915 12:52:54.346914 25245 controller.go:127] Started workers
I0915 12:53:18.064409 25245 controller.go:229] [Neutron] Try to process network: &v1.Network{TypeMeta:v1.TypeMeta{Kind:””, APIVersion:””}, ObjectMeta:v1.ObjectMeta{Name:”example-network”, GenerateName:””, Namespace:”default”, … ResourceVersion:”479015″, … Spec:v1.NetworkSpec{Cidr:”192.168.0.0/16″, Gateway:”192.168.0.1″}} …
I0915 12:53:18.064650 25245 controller.go:183] Successfully synced ‘default/example-network’
…
example-network的操作,触发了EventHandler的添加事件,从而被放进了工作队列
紧接着,控制循环就从这个队列中拿到了这个对象,并且打印出了正在处理这个Network的对象日志
这个Network的ResourceVersion,也就是API对象的版本号,是479015,而其的spec字段的内容,和YAML文件一样
然后,我们修改了一下这个YAML文件的内容
$ cat example/example-network.yaml
apiVersion: samplecrd.k8s.io/v1
kind: Network
metadata:
name: example-network
spec:
cidr: “192.168.1.0/16”
gateway: “192.168.1.1”
然后改完了,将这个YAML文件的CIDR和Gateway字段修改为了192.168.1.0/16
然后kubectl apply命令来提交这次更新,再看一下控制器的输出
这一次Inform注册的更新时间被触发,更新后的Network的key被添加到了工作队列中了,接下来,控制循环从工作队列中拿到的Network对象,和前一个对象是不同的,版本发生了变化
最后,将这个对象删除掉
kubectl delete -f example/example-network.yaml
在这个控制器的输出中,Informer注册的删除时间被触发了,并且控制循环调用Neutron API 删除 了真实环境的网络
W0915 12:54:09.738464 25245 controller.go:212] Network: default/example-network does not exist in local cache, will delete it from Neutron …
I0915 12:54:09.738832 25245 controller.go:215] [Neutron] Deleting network: default/example-network …
I0915 12:54:09.738854 25245 controller.go:183] Successfully synced ‘default/example-network’
这套流程不仅可以用在自定义API资源,也可以用在Kubernetes原生的默认API对象中
在main函数汇总,除了常见一个Network的Informer之外,还能初始化一个Kubernetes默认的API对象的Informer工厂,比如Deployment对象的Informer
func main() {
…
kubeInformerFactory := kubeinformers.NewSharedInformerFactory(kubeClient, time.Second*30)
controller := NewController(kubeClient, exampleClient,
kubeInformerFactory.Apps().V1().Deployments(),
networkInformerFactory.Samplecrd().V1().Networks())
go kubeInformerFactory.Start(stopCh)
…
}
我们首先使用Kubernetes的client创建了一个工厂
然后使用Network类似的处理方法,生成一个Deployment Informer
接着,把Deployment Informer 传递给了自定义控制器,这样,使用Start启动这个Informer
有了这个Deployment Informer之后,这个控制器可以持有所有Deployment对象的信息,接下来,可以通过deploymentInformer.Lister()来获取Etcd所有的Deployment对象,为这个Deployment Informer注册具体的Hadner
那么就可以通过自定义的API对象和默认的API对象进行协同,实现更加复杂的编排功能
用户创建一个新的Deployment,自定义控制器,可以为其创建一个对应的Network供他使用
今天剖析了Kubernetes API的编程范式,并编写了自定义控制器
Informer,是一个自带缓存和索引机制,触发Handler的客户端库,这个本地缓存在Kubernetes中一般被称为Store,索引一般称为Index
Informer使用了Reflector包,可以通过ListAndWatch机制获取并监视API对象变化的客户端封装
而Reflector和Informer之间,用到一个队列协同
而且,除了控制循环外的代码,大抵都是Kubernetes自动生成的,即pkg/client/{informers,listers,clientset}中的内容
这些自动生成的代码,提供了一个可靠且高效获取API对象期望状态的编程库
作为开发者,只需要关心如何拿到实际状态,拿他跟期望状态做对比,从而决定要做的业务逻辑即可
思考题,为何Informer和编写的控制循环之间,一定要使用一个工作队列来协作呢?
经典的消费者生产者模型,主要是为了协调两者的速度不一致来使用,利用一个队列进行存储,避免消费者的消费速度过慢
这一章的思路我读懂了,但是由于没从事过GO语言的学习过,所以代码并不是很了解,看来有必要学习下Go语言的编写