在书写SQL语句的时候,可以明确指定使用哪个索引,但是如果不指定的时候,使用哪个索引是由MySql来确定的
假设如下一张表
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`),
KEY `b` (`b`)
) ENGINE=InnoDB;
上面有三个字段,然后往表上插入10万行记录,值依次递增,从1,1,1到100000,100000,100000
然后分析一个SQL语句
select * from t where a between 10000 and 20000;
然后我们使用
explain来查看mysql如何执行的

使用了索引a
这说明mysql的执行并没有问题
然后我们执行如下的操作

在Session A中,直接开启了一个事务A,但是没有任何操作,进行了commit
在Session B 中执行了如下语句
删除整个表
然后重新存储
然后进行查询
这时候如果通过slow log 查看对应的执行情况
会直接发现进行了一次全表扫描,这时候需要一个对比,我们再次编写一个Sql语句
为何进行了一次全表扫描呢?
也就是为何没有选择索引a呢?
这是因为Mysql在选择索引来执行语句之前,会进行判断一下需要扫描的行数
MySql并不能知道满足条件的行数,只能进行相关的估算
如何进行的估算,也就是MySql存储在索引上的区分度,亦可以称为 基数 cardinality,基数越大,索引的区分度越好

对于这个基数的获取呢?
采用了采样统计的方法
就是InnoDB选择N个数据页,然后统计不同值,得到一个平均值,然后乘以索引的页面数
一般来说,也会从索引树上拿取这个基数值
但是MySql是会发生更新的,于是在更新超过1/M行后,进行一次重新统计
这个值可以设置
可以通过 innodb_stats_persistent来设置,可以分为 on和off
on的时候,统计信息放在持久化存储中,默认N是20,M是10
off的时候,统计信息值放在内存中,默认N是8,M是16
但是 M还是N都不准
但是MySql统计索引虽然不是非常准确,但并非是选错索引的唯一原因
如果我们使用如下的explain来进行测试的话
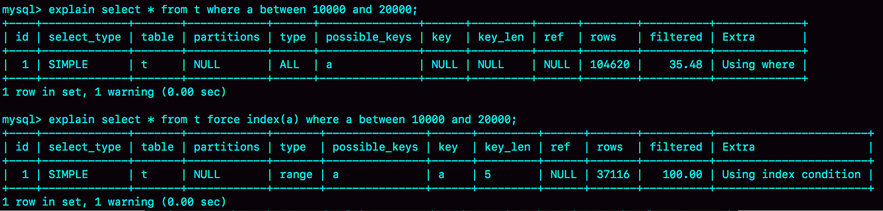
会发现,如果强制使用index a,也只需要37000行
为啥放着37000行的执行不用,而是使用了100000行的执行呢?.
这可能是MySql预计了,如果使用了索引a,还需要进行回表扫描,这就导致优化器认为直接扫描主键索引会更加快,但是实际上它的选择是错误的
那么如何重新让索引回到正轨呢?
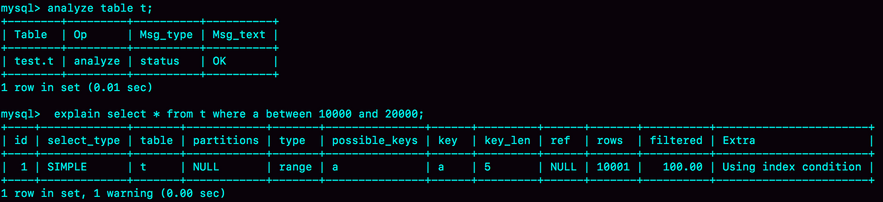
可以使用analyze table t命令,来重新统计索引信息,看一下执行效果
还有就是一种索引的选错
Select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 1;
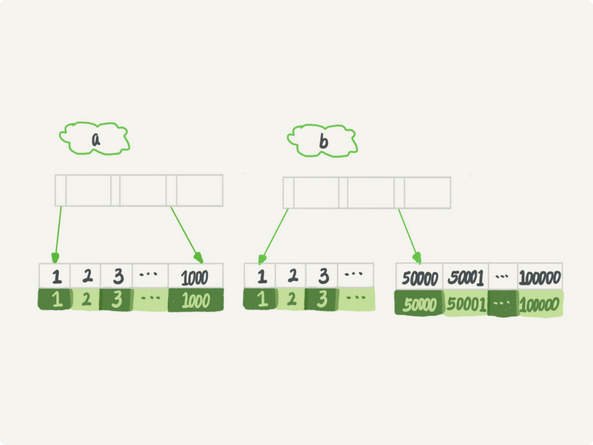
如果是索引A,那么是扫描索引a的前1000个值,然后回表找b,扫描1000行
如果是索引B,那么是扫描索引b的最后50001值,然后在回表判断,扫描500001行
这样看,是索引A的执行快

但是还是选择了索引B,这是为何?
当然可以使用force index来进行优化解决,但是并不建议这么做,我们仍需要知道为啥innodb选择了这个索引
1.我们使用了order by b,这样导致了优化器选择了索引b,因为索引b来进行查找的话,就无需排序了
2.当然,如果想要优化,可以将order by b改为了 order by b,a limit 1,让索引进行竞争,从而引导MySql选择正确的数值
3.最好的方式是建立一个更加合适的索引,来让优化器更加方便的去使用,或者删除诱导的索引
往往直接删除一个索引会更加的简单,有时候索引就是多余了,没必要去维护他