本次主要是介绍在不同的业务的场景中,是选择普通索引还是唯一索引
假设在维护一个市民的系统,每个人有一个唯一的身份证,如果市民的系统需要按照身份证查询你名字,那么会执行如下的SQL

这就可以考虑在id_card 字段上建立索引
但是身份证的字段长度较大,并不是很建议将身份证号作为主键,那么就可以有两个选择,要么偶给id_card字段创建一个唯一索引,要么创建一个普通的索引
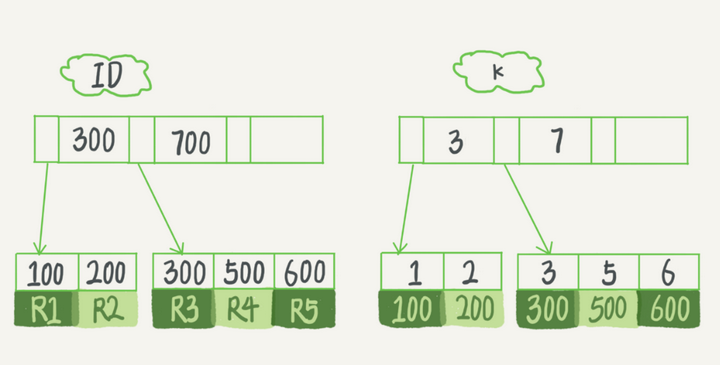
对于上面的两种索引,如何进行考虑
如果执行一个语句 select id from T where k = 5 这个查询语句在索引树上查询的过程,可以先从B+树的树根开始,一直找到k=5位置
也就是 5,500,但是并不会停止,而是继续找下一个记录,直到k不为5
对于唯一索引来说,因为具有了唯一性,所以找到后就不会继续查找了
唯一索引的优势来了
但是两者的差距并不大,因为InnoDB的数据是按照数据页为单位读写的,所以需要读一个记录的时候,是数据页其整体读入内存,在InnoDB中,每一个数据页的大小默认是16KB
当然如果是一般索引的话,会出现下个数据正好在下一个数据页的情况,但是很少见
而且对于更新,唯一索引和一般索引也就有区别
如果更新的目标页在内存中,InnoDB中为
唯一索引,找到3,5之间,判断没有冲突,进行插入
一般索引,找到3,5之间,直接插入
如果不在内存中
唯一索引,将数据页读入内存之中,找到3,5之间,判断是否有冲突,插入这个值
普通索引,直接将记录放在change buffer中,完成执行
两者在changebuffer上的操作如下:
当需要一个数据页的,如果数据页在内存中就直接更新,如果这个数据页还没在内存中的话,在不影响数据一致性的前提下,InooDB会将这些更新操作缓存在change buffer之中,这就不需要从磁盘中读入这个数据页了,下次查询访问你这个数据页的时候,将数据页读入内存,然后执行change buffer中和这个页相关的操作,将change buffer中的操作应用到数据页中,得到最新的结果的过程为merge,但是唯一索引不能走如上的流程
什么时候会使用change buffer,在读取入数据页的时候回触发,后台线程定期触发,数据库正常关闭也会触发
而且可以避免磁盘读盘次数,而且数据读入内存需要占用buffer pool的,这种方式还能避免浪费内存,change buffer用的是buffer pool中的内存,可以通过 innodb_change_buffer_max_size来设置.
说完了唯一索引和普通索引的区别之后.说一下change buffer在数据更新和读取的操作
change buffer和redo log,如何进行的配合
假设插入一条数据
insert into t(id,k) values(id1,k1),(id2,k2)
假设k索引树的状态,在查找到位置之后,k1所在锁的数据在内存(InnoDB buffer pool)中,k2所在的数据页不在内存中
1.Page1在内存中,将直接更新内存
2.Page2不在内存区域之中,就在change buffer中的区域,记录下插入的信息
3.记入redo log之中
接下来如果对这两个数据进行读取
1.读Page1的时候,直接从内存中返回
2.读取Page2的时候,会先从Page从磁盘读入内存中,然后应用change buffer里面的操作日志,生成一个正确的版本进行返回
在真正读取Page2的时候,这个数据页才会读入内存,之前只是写入了redo log
所以redo log是为了节省随机写磁盘的消耗,而change buffer为了节省随机读取磁盘的IO消耗
所以一般在实战中,只要业务允许,尽可能的使用非唯一索引
如果某次使用了change buffer机制了,主机异常重启了,可能会出现丢失change buffer的问题,但是无须担心数据的安全性,因为change buffer中数据的变化已经记录到redo log中了,崩溃恢复的change buffer,也能找回来